はじめに
『ゼロからできるMCMC』の図とサンプルコードをR言語で再現します。本と一緒に読んでください。
この記事は、5章の内容です。多変数のガウス分布(多変量正規分布)に対してメトロポリス法を用いて期待値計算を近似します。
【前の章の内容】
【他の章の内容】
【この章の内容】
この章で利用するパッケージを読み込みます。
# 5章で利用するパッケージ library(tidyverse)
5.1 多変数のガウス分布
この節では、作用(負の対数尤度?)を
とし、確率密度関数を
とする2次元ガウス分布に対するメトロポリス法を考えます。ただしこの式は、正規化項を省略しています。$\propto$は、比例関係を示す記号です。
ちなみに、この多変数ガウス分布(多変量正規分布)の平均$\boldsymbol{\mu}$、分散共分散行列の逆数$\boldsymbol{\Sigma}^{-1}$は
です。2変数を$\mathbf{x} = (x, y)$で表すと、多変数のガウス分布の定義式は
です。ただし正規化項は省略しています。括弧の中について、パラメータを代入して整理すると
式(5.2)の形になります。
では話戻って、$P(x, y)$と$S(x, y)$を計算する関数を定作成して、分布をグラフで確認しておきます。
# 作用(負の対数尤度)を指定 fn_S <- function(x, y) { (x^2 + y^2 + x * y) * 0.5 } # 確率分布を指定 fn_P <- function(x, y) { exp(-fn_S(x, y)) } # 一様分布の範囲(ステップ幅)を指定 c <- 4 # 真の分布を計算 vec <- seq(-c, c, 0.01) # 描画用の点 true_df <- tibble( x = rep(vec, times = length(vec)), y = rep(vec, each = length(vec)), P_xy = fn_P(x, y) # 確率密度 ) # 真の分布をプロット ggplot(true_df, aes(x = x, y = y, z = P_xy, color = ..level..)) + geom_contour() + # 等高線 labs(title = "Mixture Gaussian Distribution")
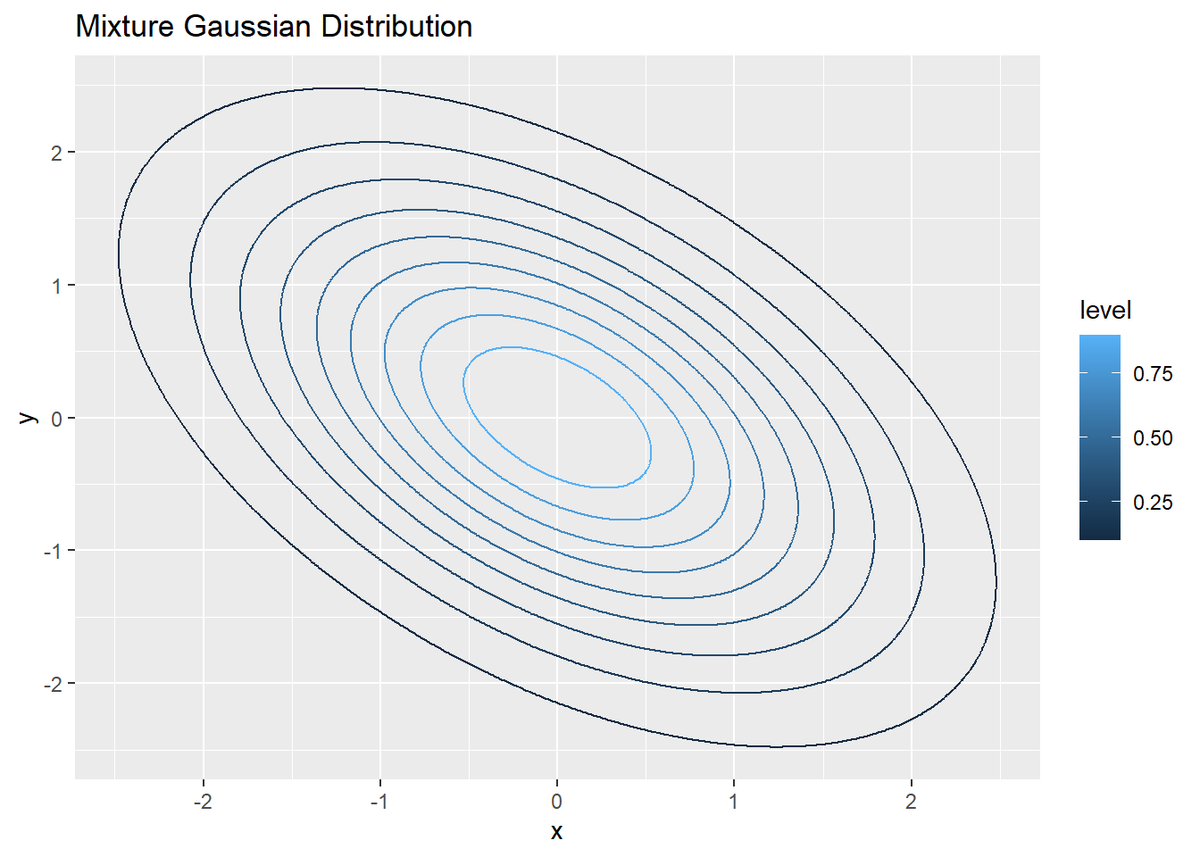
確率密度は、geom_contour()で等高線を引くことで表します。このときx軸とy軸が直交するように敷き詰められた点を用意する必要があります。
・分布の近似
メトロポリス法の処理は、前章のコードとほとんど同じです。xに関する処理をyにも行います。$x,\ y$の初期値を$x^{(0)} = y^{(0)} = 0$、繰り返し回数を$K = 10000$とします。
# 繰り返し回数を指定 K <- 10000 # 初期値を指定 x <- 0 y <- 0 # Main loop trace_x <- rep(0, K) trace_y <- rep(0, K) for(k in 1:K) { # 更新候補を計算 dash_x <- x + runif(n = 1, min = -c, max = c) dash_y <- y + runif(n = 1, min = -c, max = c) # テスト値を生成 r <- runif(n = 1, min = 0, max = 1) # メトロポリステストにより更新 if(r < exp(fn_S(x, y) - fn_S(dash_x, dash_y))) { x <- dash_x y <- dash_y } # 更新値を記録 trace_x[k] <- x trace_y[k] <- y } # 更新値のデータフレームを作成 update_df <- tibble( k = 1:K, x = trace_x, y = trace_y ) # 確認 head(update_df)
## # A tibble: 6 x 3 ## k x y ## <int> <dbl> <dbl> ## 1 1 0 0 ## 2 2 0 0 ## 3 3 0 0 ## 4 4 0 0 ## 5 5 0 0 ## 6 6 0 0
メトロポリス法により$x^{(1)}, \cdots, x^{(K)}$と$y^{(1)}, \cdots, y^{(K)}$が得られました。
これを先ほどの分布に重ねて確認しましょう。
# 散布図を作成 ggplot() + geom_point(data = update_df, aes(x = x, y = y)) + # サンプルの散布図 geom_contour(data = true_df, aes(x = x, y = y, z = P_xy, color = ..level..)) + # 真の確率密度 labs(title = "Metropolis Method", subtitle = paste0("K=", K))
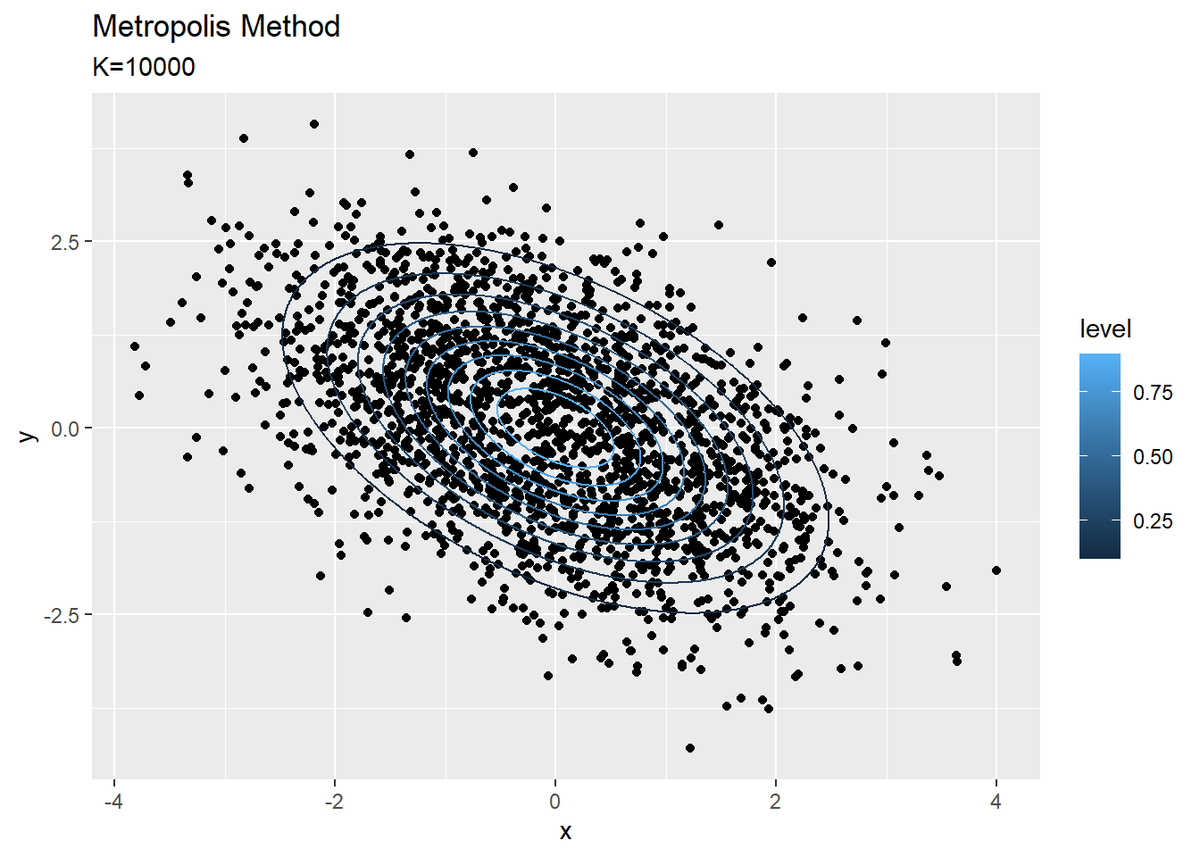
外れ値などはなく、真の分布に沿ったデータを得られています。
・期待値の近似
前章では、$x$の期待値を求めました。この例では、$x$と$y$それぞれの関数を用意して、その期待値を求めます。
2つの関数
を用います(本ではそれぞれを物理学者(physics)と野球選手(baseball)の収入関数としています)。tanh関数は、-1から1を返す関数です。詳しくは「A.2:tanh関数【ゼロつく2のノート(実装)】 - からっぽのしょこ」にまとめています。
この計算を関数として定義します。
# 関数を指定 fn_phy <- function(x) { (2 + tanh(x)) / 3 } fn_bb <- function(y) { # データ数を取得 n <- length(y) # 受け皿を初期化 f_y <- rep(0, n) # 出力を計算 for(i in 1:n) { # i番目のデータを取得 y_i <- y[i] # 式(5.4)の計算 if(y_i <= 2) { f_y_i <- 0 } else if(y_i > 2) { f_y_i <- y_i^2 * 0.5 } # 計算結果を格納 f_y[i] <- f_y_i } # 出力 f_y } # 関数の出力をプロット tibble( x = seq(-c, c, 0.01), f_x = fn_phy(x), f_y = fn_bb(x) ) %>% ggplot(aes(x = x)) + geom_line(aes(y = f_x)) + geom_line(aes(y = f_y)) + labs(x, "x, y", y = "f_phy(x), f_bb(y)")

作成した関数と$x^{(1)}, \cdots, x^{(K)}$と$y^{(1)}, \cdots, y^{(K)}$を用いて、2つの関数の期待値をそれぞれ
で近似計算します。
# 期待値を計算 expected_df <- update_df %>% dplyr::mutate( f_x = fn_phy(x), f_y = fn_bb(y) ) %>% dplyr::mutate( E_f_x = cumsum(f_x) / k, E_f_y = cumsum(f_y) / k ) # 確認 head(expected_df)
## # A tibble: 6 x 7 ## k x y f_x f_y E_f_x E_f_y ## <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 0 0 0.667 0 0.667 0 ## 2 2 0 0 0.667 0 0.667 0 ## 3 3 0 0 0.667 0 0.667 0 ## 4 4 0 0 0.667 0 0.667 0 ## 5 5 0 0 0.667 0 0.667 0 ## 6 6 0 0 0.667 0 0.667 0
近似推移を確認します。
# 推移をプロット ggplot(expected_df, aes(x = k)) + geom_line(aes(y = E_f_x), color = "orange") + geom_hline(aes(yintercept = 2 / 3), linetype = "dashed", color = "orange") + geom_line(aes(y = E_f_y), color = "#00A986") + geom_hline(aes(yintercept = 0.1305), linetype = "dashed", color = "#00A986") + labs(y = "E[f]")
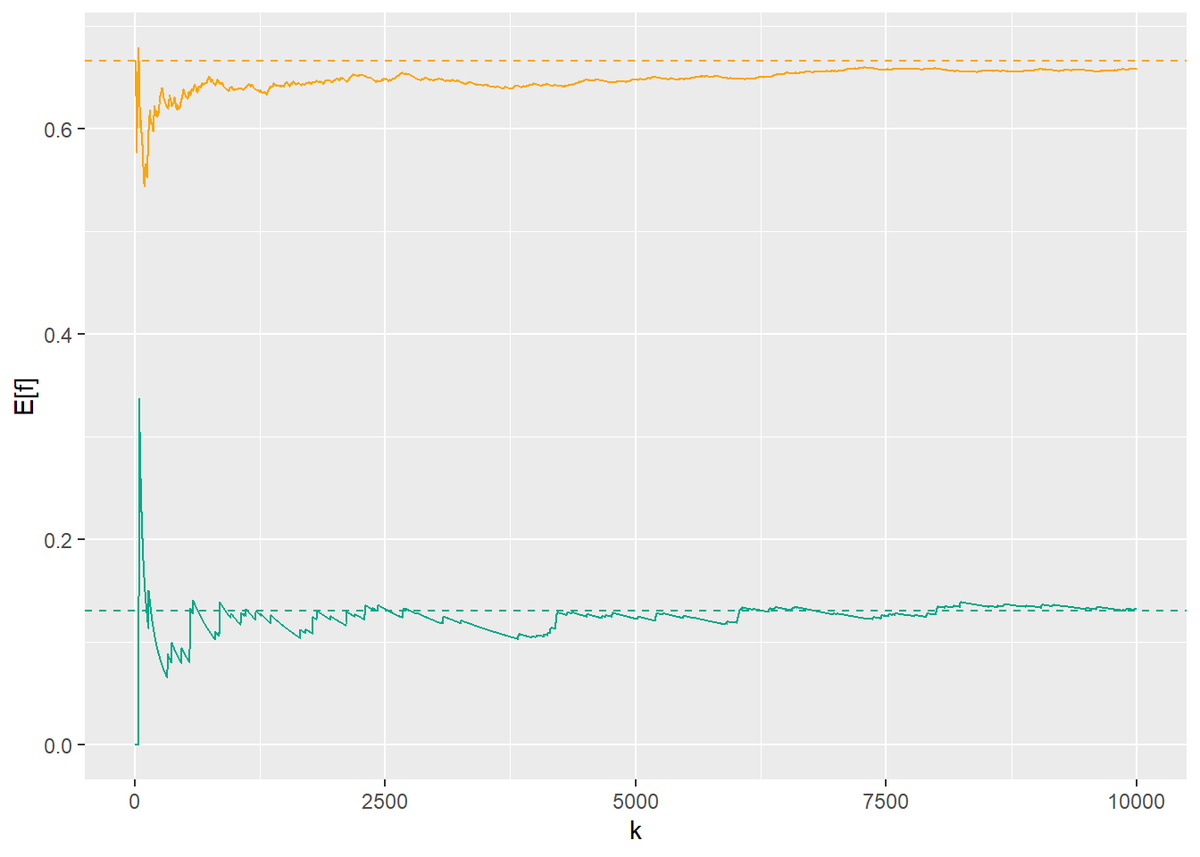
2つの関数の期待値の収束の仕方に違いがみられます。
・シミュレーション
同じことを複数回行ってみましょう。
# 繰り返し回数を指定 K <- 1000 # シミュレーション回数を指定 n_simu <- 100 # Main loop trace_df <- tibble() for(k in 1:K) { # 前ステップの変数を取得 if(k > 1) { x <- tmp_df[["new_x"]] y <- tmp_df[["new_y"]] } else if(k == 1) { # 初回のみ # 初期値を指定 x <- rep(0, n_simu) y <- rep(0, n_simu) } # 全てのシミュレーションにおけるk回目の更新 tmp_df <- tibble( simulation = as.factor(1:n_simu), # シミュレーション番号 k = k, # 繰り返し番号 old_x = x, # 前ステップのx old_y = y, # 前ステップのy S_xy = fn_S(old_x, old_y), # 前ステップの作用を計算 delta_x = runif(n = n_simu, min = -c, max = c), # xの変化量を生成 delta_y = runif(n = n_simu, min = -c, max = c), # yの変化量を生成 S_dash_xy = fn_S(old_x + delta_x, old_y + delta_y), # 更新候補の作用を計算 r = runif(n = n_simu, min = 0, max = 1), # テスト値を計算 test = dplyr::if_else( r < exp(S_xy - S_dash_xy), true = 1, false = 0 ), # メトロポリステスト new_x = old_x + test * delta_x, # xを更新 new_y = old_y + test * delta_y # yを更新 ) # 結果を結合 trace_df <- rbind(trace_df, tmp_df) # n回ごとに途中経過を表示 if(k %% 25 == 0) { #print(paste0( # "k=", k, " (", round(k / K * 100, 1), "%)" #)) } } # 確認 head(trace_df)
## # A tibble: 6 x 12 ## simulation k old_x old_y S_xy delta_x delta_y S_dash_xy r test ## <fct> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 1 0 0 0 0.497 -3.46 5.26 0.676 0 ## 2 2 1 0 0 0 0.887 2.60 4.91 0.921 0 ## 3 3 1 0 0 0 2.34 -0.0592 2.67 0.0366 1 ## 4 4 1 0 0 0 -0.0977 -1.35 0.986 0.271 1 ## 5 5 1 0 0 0 -3.82 2.44 5.63 0.182 0 ## 6 6 1 0 0 0 -0.689 3.09 3.95 0.434 0 ## # ... with 2 more variables: new_x <dbl>, new_y <dbl>
全てのシミュレーションを同時に実行しています。n_simu個の$x,\ y$に関して$K$回サンプリングします。
各シミュレーションごとに関数$f_{\mathrm{phy}}(x)$と$f_{\mathrm{bb}}(y)$の期待値を計算します。
# 期待値を計算 expected_df <- tibble() for(s in 1:n_simu) { # s番目のシミュレーションを計算 tmp_df <- trace_df %>% dplyr::filter(simulation == s) %>% dplyr::select( simulation, k, x = new_x, y = new_y ) %>% # 関数の計算 dplyr::mutate( f_x = fn_phy(x), f_y = fn_bb(y) ) %>% # 期待値を計算 dplyr::mutate( E_f_x = cumsum(f_x) / k, E_f_y = cumsum(f_y) / k ) # 計算結果を結合 expected_df <- rbind(expected_df, tmp_df) } # 確認 head(expected_df)
## # A tibble: 6 x 8 ## simulation k x y f_x f_y E_f_x E_f_y ## <fct> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 1 0 0 0.667 0 0.667 0 ## 2 1 2 0 0 0.667 0 0.667 0 ## 3 1 3 0 0 0.667 0 0.667 0 ## 4 1 4 0 0 0.667 0 0.667 0 ## 5 1 5 0 0 0.667 0 0.667 0 ## 6 1 6 0 0 0.667 0 0.667 0
関数ごとに推移をプロットします。
# 図5.3をプロット ggplot(expected_df, aes(x = k, y = E_f_x, color = simulation)) + geom_line(alpha = 0.5) + geom_hline(aes(yintercept = 2 / 3), linetype = "dashed", color = "orange") + theme(legend.position = "none") + labs(title = "Metropolis Method", subtitle = paste0("simulation:", n_simu), y = "E[f_phy(x)]")
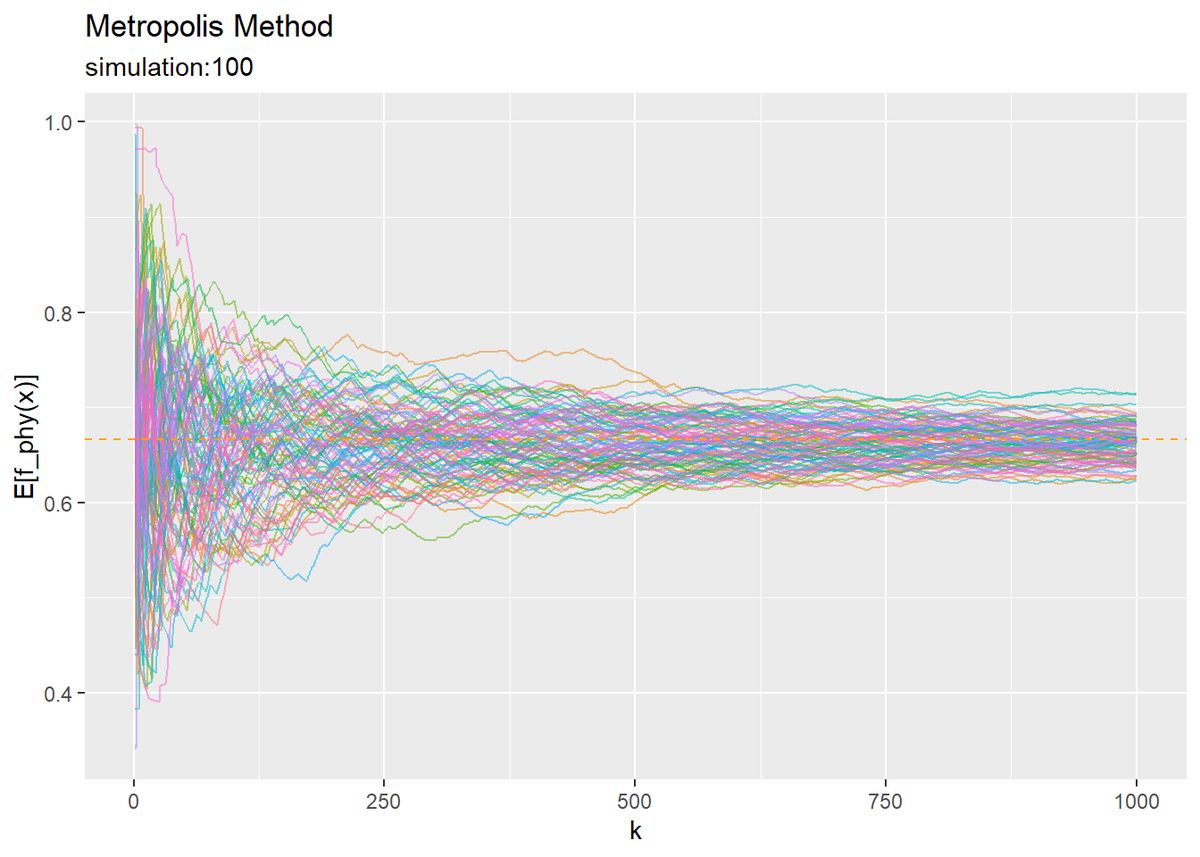
# 図5.4をプロット ggplot(expected_df, aes(x = k, y = E_f_y, color = simulation)) + geom_line(alpha = 0.5) + geom_hline(aes(yintercept = 0.1305), linetype = "dashed", color = "#00A986") + theme(legend.position = "none") + labs(title = "Metropolis Method", subtitle = paste0("simulation:", n_simu), y = "E[f_bb(y)]")
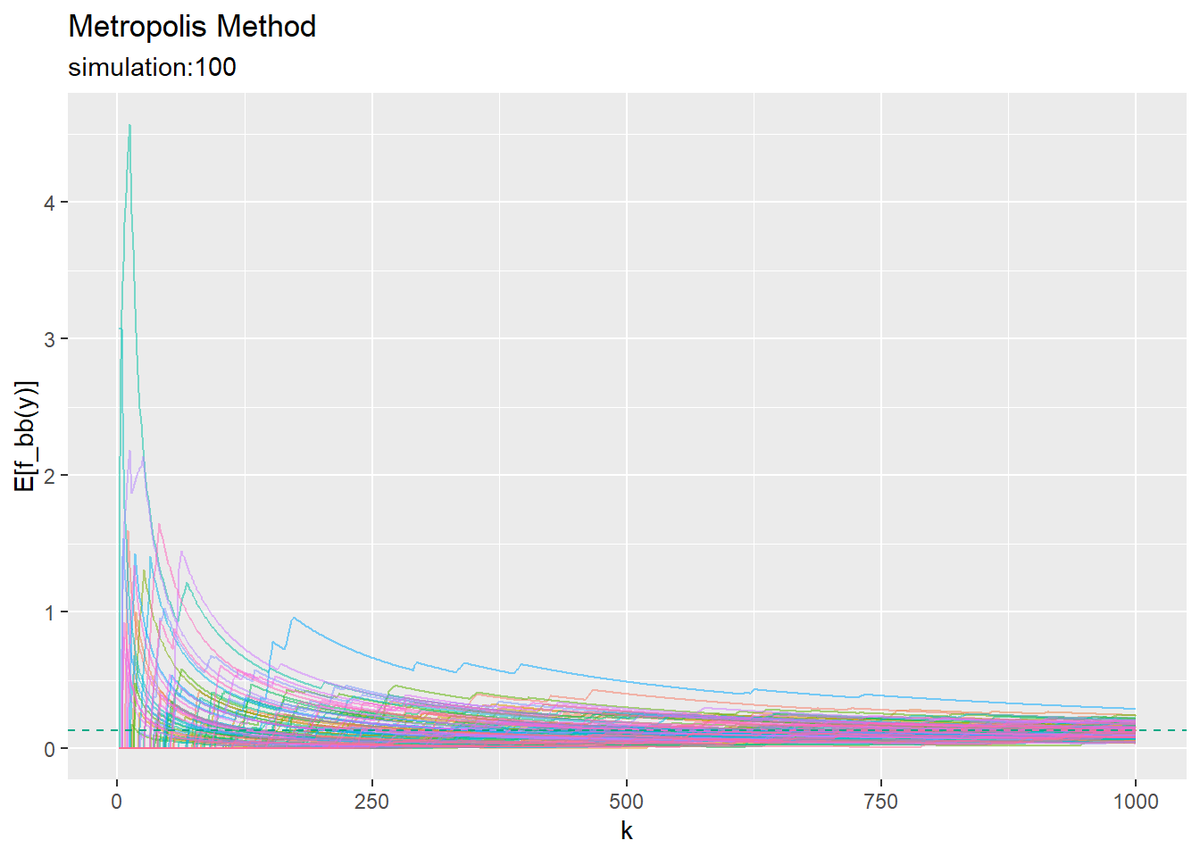
関数によって近似精度に差異が見られます。
参考文献
- 花田政範・松浦壮『ゼロからできるMCMC』講談社,2020年.
おわりに
ここまでが基礎編って感じですかね。とりあえず概ね理解できた気がするので良しとします。てなわけで、ゼロからDLの方に戻ります。続きはまたいずれ。
【次の章の内容】
つづきます。