はじめに
『ベイズ推論による機械学習入門』の学習時のノートです。基本的な内容は「数式の行間を読んでみた」とそれを「RとPythonで組んでみた」になります。「数式」と「プログラム」から理解するのが目標です。
この記事は、4.4.2項の内容です。「観測モデルを多次元ガウス混合分布(多変量正規混合分布)」、「事前分布をガウス・ウィシャート分布とディリクレ分布」とするガウス混合モデルに対するギブスサンプリングをRで実装します。
省略してある内容等ありますので、本とせあわせて読んでください。初学者な自分が理解できるレベルまで落として書き下していますので、分かる人にはかなりくどくなっています。同じような立場の人のお役に立てれば幸いです。
【数式読解編】
【他の節一覧】
【この節の内容】
・Rでやってみる
人工的に生成したデータを用いて、ベイズ推論を行ってみましょう。アルゴリズム4.5を参考に実装します。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse) library(mvnfast) library(MCMCpack)
mvnfastは、多次元ガウス分布に関するパッケージです。多次元ガウス分布に従う乱数生成関数rmvn()と確率密度関数dmvn()を使います。また、MCMCpackパッケージのディリクレ分布に従う乱数生成関数rdirichlet()を使います。
・観測モデルの設定
まずは、観測モデルを設定します。この節では、$K$個の観測モデルを多次元ガウス分布$\mathcal{N}(\mathbf{x}_n | \boldsymbol{\mu}_k, \boldsymbol{\Lambda}_k^{-1})$とします。また、各データに対する観測モデルの割り当てをカテゴリ分布$\mathrm{Cat}(\mathbf{s}_n | \boldsymbol{\pi})$によって行います。
観測モデルのパラメータを設定します。この実装例では2次元のグラフで表現するため、$D = 2$のときのみ動作します。
# 次元数を設定:(固定) D <- 2 # クラスタ数を指定 K <- 3 # K個の真の平均を指定 mu_truth_kd <- matrix( c(5, 35, -20, -10, 30, -20), nrow = K, ncol = D, byrow = TRUE ) # K個の真の分散共分散行列を指定 sigma2_truth_ddk <- array( c(250, 65, 65, 270, 125, -45, -45, 175, 210, -15, -15, 250), dim = c(D, D, K) )
$K$の平均パラメータ$\boldsymbol{\mu} = \{\boldsymbol{\mu}_1, \boldsymbol{\mu}_2, \cdots, \boldsymbol{\mu}_K\}$、$\boldsymbol{\mu}_k = (\mu_{k,1}, \mu_{k,2}, \cdots, \mu_{k,D})$をmu_truth_kd、分散共分散行列パラメータ$\boldsymbol{\Sigma} = \{\boldsymbol{\Sigma}_1, \boldsymbol{\Sigma}_2, \cdots, \boldsymbol{\Sigma}_K\}$、$\boldsymbol{\Sigma}_k = (\sigma_{k,1,1}^2, \cdots, \sigma_{k,D,D}^2)$をsigma2_truth_ddkとして、値を指定します。$\boldsymbol{\Sigma}_k$は正定値行列です。また、分散共分散行列の逆行列$\boldsymbol{\Lambda}_k = \boldsymbol{\Sigma}_k^{-1}$を精度行列と呼びます。
mu_true_kdの作成の際に、matrix()の引数にbyrow = TRUEを指定すると行方向に要素を並べるため、値を指定しやすくなります。
設定したパラメータは次のようになります。
# 確認
mu_truth_kd
sigma2_truth_ddk
## [,1] [,2] ## [1,] 5 35 ## [2,] -20 -10 ## [3,] 30 -20 ## , , 1 ## ## [,1] [,2] ## [1,] 250 65 ## [2,] 65 270 ## ## , , 2 ## ## [,1] [,2] ## [1,] 125 -45 ## [2,] -45 175 ## ## , , 3 ## ## [,1] [,2] ## [1,] 210 -15 ## [2,] -15 250
混合比率を設定します。
# 真の混合比率を指定 pi_truth_k <- c(0.45, 0.25, 0.3)
混合比率パラメータ$\boldsymbol{\pi} = (\pi_1, \pi_2, \cdots, \pi_K)$をpi_true_kとして、$\sum_{k=1}^K \pi_k = 1$、$\pi_k \geq 0$の値を指定します。ここで、$\pi_k$は各データがクラスタ$k$となる($s_{n,k} = 1$となる)確率を表します。
この3つのパラメータの値を観測データから求めるのがここでの目的です。
設定した観測モデルをグラフで確認しましょう。作図用の点を作成します。
# 作図用のx軸のxの値を作成 x_1_vec <- seq( min(mu_truth_kd[, 1] - 3 * sqrt(sigma2_truth_ddk[1, 1, ])), max(mu_truth_kd[, 1] + 3 * sqrt(sigma2_truth_ddk[1, 1, ])), length.out = 300) # 作図用のy軸のxの値を作成 x_2_vec <- seq( min(mu_truth_kd[, 2] - 3 * sqrt(sigma2_truth_ddk[2, 2, ])), max(mu_truth_kd[, 2] + 3 * sqrt(sigma2_truth_ddk[2, 2, ])), length.out = 300 ) # 作図用のxの点を作成 x_point_mat <- cbind( rep(x_1_vec, times = length(x_2_vec)), rep(x_2_vec, each = length(x_1_vec)) )
作図用に、2次元ガウス分布に従う変数$\mathbf{x}_n = (x_{n,1}, x_{n,2})$がとり得る点(値の組み合わせ)を作成します。$x_{n,1}$がとり得る値(x軸の値)をseq()で作成してx_1_vecとします。この例では、$K$個のクラスタそれぞれで平均値から標準偏差の3倍を引いた値と足した値を計算して、その最小値から最大値までを範囲とします。length.out引数を使うと指定した要素数で等間隔に切り分けます。by引数を使うと切り分ける間隔を指定できます。処理が重い場合は、この値を調整してください。同様に、$x_{n,2}$がとり得る値(y軸の値)も作成してx_2_vecとします。
x_1_vecとx_2_vecの要素の全ての組み合わせを持つようにマトリクスを作成してx_point_matとします。これは、確率密度を等高線図にする際に格子状の点(2軸の全ての値が直交する点)を渡す必要があるためです。
作成した$\mathbf{x}$の点は次のようになります。
# 確認 x_point_mat[1:5, ]
## [,1] [,2] ## [1,] -53.54102 -67.43416 ## [2,] -53.11622 -67.43416 ## [3,] -52.69142 -67.43416 ## [4,] -52.26662 -67.43416 ## [5,] -51.84182 -67.43416
1列目がx軸の値、2列目がy軸の値に対応しています。
観測モデルの確率密度を計算します。
# 観測モデルを計算 model_density <- 0 for(k in 1:K) { # クラスタkの分布の確率密度を計算 tmp_density <- mvnfast::dmvn( X = x_point_mat, mu = mu_truth_kd[k, ], sigma = sigma2_truth_ddk[, , k] ) # K個の分布の加重平均を計算 model_density <- model_density + pi_truth_k[k] * tmp_density }
$K$個のパラメータmu_truth_kd, sigmga2_truth_ddkを使って、x_point_matの点ごとに、次の混合ガウス分布の式で確率密度を計算します。
$K$個の多次元ガウス分布に対して、$\boldsymbol{\pi}$を使って加重平均をとります。
多次元ガウス分布の確率密度は、mvnfastパッケージのdmvn()で計算できます。$k$番目の分布の場合は、データの引数Xにx_point_mat、平均の引数muにmu_truth_kd[k, ]、分散共分散行列の引数sigmaにsigma2_truth_ddk[, , k]を指定します。
この計算をfor()ループでK回繰り返し行います。各パラメータによって求めた$K$回分の確率密度をそれぞれpi_truth_k[k]で割り引いてmodel_probに加算していきます。
計算結果をデータフレームに格納します。
# 観測モデルをデータフレームに格納 model_df <- tibble( x_1 = x_point_mat[, 1], x_2 = x_point_mat[, 2], density = model_density ) # 確認 head(model_df)
## # A tibble: 6 x 3 ## x_1 x_2 density ## <dbl> <dbl> <dbl> ## 1 -53.5 -67.4 9.07e-13 ## 2 -53.1 -67.4 1.07e-12 ## 3 -52.7 -67.4 1.27e-12 ## 4 -52.3 -67.4 1.50e-12 ## 5 -51.8 -67.4 1.78e-12 ## 6 -51.4 -67.4 2.10e-12
ggplot2パッケージを利用して作図するには、データフレームを渡す必要があります。
観測モデルを作図します。
# 観測モデルを作図 ggplot(model_df, aes(x = x_1, y = x_2, z = density, color = ..level..)) + geom_contour() + # 真の分布 labs(title = "Gaussian Mixture Model", subtitle = paste0("K=", K), x = expression(x[1]), y = expression(x[2]))
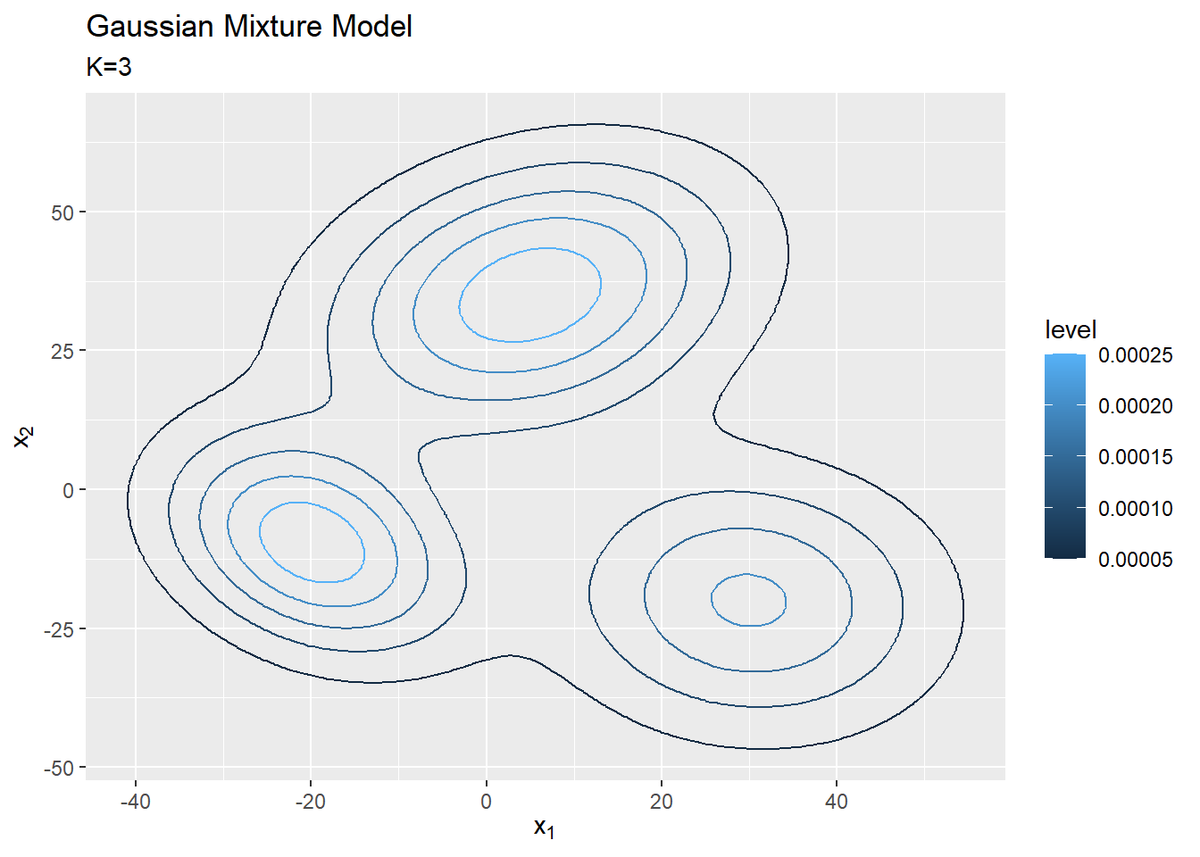
等高線グラフはgeom_contour()で描画します。
$K$個の分布を重ねたような分布になります。ただし、積分して1となるようにしているため、$K$個の分布そのものよりも1つ1つの山が小さく(確率密度が小さく)なっています。
・データの生成
続いて、構築した観測モデルに従ってデータを生成します。先に、潜在変数$\mathbf{S} = \{\mathbf{s}_1, \mathbf{s}_2, \cdots, \mathbf{s}_N\}$、$\mathbf{s}_n = (s_{n,1}, s_{n,2}, \cdots, s_{n,K})$を生成し、各データにクラスタを割り当てます。次に、割り当てられたクラスタに従い観測データ$\mathbf{X} = \{\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_N\}$、$\mathbf{x}_n = (x_{n,1}, x_{n,2}, \cdots, x_{n,D})$を生成します。
$N$個の潜在変数$\mathbf{S}$を生成します。
# (観測)データ数を指定 N <- 250 # 潜在変数を生成 s_truth_nk <- rmultinom(n = N, size = 1, prob = pi_truth_k) %>% t()
生成するデータ数$N$をNとして値を指定します。
カテゴリ分布に従う乱数は、多項分布に従う乱数生成関数rmultinom()のsize引数を1にすることで生成できます。また、試行回数の引数nにN、確率(パラメータ)の引数probにpi_truth_kを指定します。生成した$N$個の$K$次元ベクトルをs_truth_nkとします。ただし、クラスタが行でデータが列方向に並んで出力されるので、t()で転置しておきます。
結果は次のようになります。
# 確認 s_truth_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 0 1 0 ## [2,] 0 0 1 ## [3,] 1 0 0 ## [4,] 1 0 0 ## [5,] 0 0 1
これが本来は観測できない潜在変数であり、真のクラスタです。各行がデータを表し、値が1の列番号が割り当てられたクラスタ番号を表します。
s_truth_nkから各データのクラスタ番号を抽出します。
# クラスタ番号を取得 s_truth_n <- which(t(s_truth_nk) == 1, arr.ind = TRUE) %>% .[, "row"] # 確認 s_truth_n[1:5]
## [1] 2 3 1 1 3
which()を使って行(データ)ごとに要素が1の列番号を抽出します。
各データに割り当てられたクラスタに従い$N$個のデータを生成します。
# (観測)データを生成 x_nd <- matrix(0, nrow = N, ncol = D) for(n in 1:N) { # n番目のデータのクラスタ番号を取得 k <- s_truth_n[n] # n番目のデータを生成 x_nd[n, ] = mvnfast::rmvn(n = 1, mu = mu_truth_kd[k, ], sigma = sigma2_truth_ddk[, , k]) }
各データ$\mathbf{x}_n$に割り当てられたクラスタ($s_{n,k} = 1$である$k$)のパラメータ$\boldsymbol{\mu}_k,\ \boldsymbol{\Sigma}_k$を持つ多次元ガウス分布に従いデータ(値)を生成します。多次元ガウス分布の乱数は、mvnfastパッケージのrmvn()で生成できます。
データごとにクラスタが異なるので、for()で1データずつ処理します。$n$番目のデータのクラスタ番号s_true_n[n]を取り出してkとします。そのクラスタに従ってデータ$\mathbf{x}_n$を生成します。平均の引数muにmu_true_kd[k, ]、分散共分散行列の引数sigmaにsigma2_true_ddk[, , k]を指定します。また1データずつ生成するので、データ数の引数nは1です。
観測データもグラフで確認しましょう。作図用のデータフレームを作成します。
# 観測データと真のクラスタ番号をデータフレームに格納 x_df <- tibble( x_n1 = x_nd[, 1], x_n2 = x_nd[, 2], cluster = as.factor(s_truth_n) ) # 確認 head(x_df)
## # A tibble: 6 x 3 ## x_n1 x_n2 cluster ## <dbl> <dbl> <fct> ## 1 -25.8 10.8 2 ## 2 43.3 -14.9 3 ## 3 -0.293 27.7 1 ## 4 3.23 56.7 1 ## 5 31.6 -13.3 3 ## 6 73.4 -21.1 3
2次元の観測データに1つのクラスタが割り当てられています。
観測データの散布図を観測モデルに重ねて作図します。
# 観測データの散布図を作成 ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density), linetype = "dashed") + # 真の分布 #geom_contour_filled(data = model_df, aes(x = x_1, y = x_2, z = density, fill = ..level..), # alpha = 0.6, linetype = "dashed") + # 真の分布:(塗りつぶし) geom_point(data = x_df, aes(x = x_n1, y = x_n2, color = cluster)) + # 真のクラスタ labs(title = "Gaussian Mixture Model", subtitle = paste0('N=', N, ", pi=(", paste0(pi_truth_k, collapse = ", "), ")"), x = expression(x[1]), y = expression(x[2]))
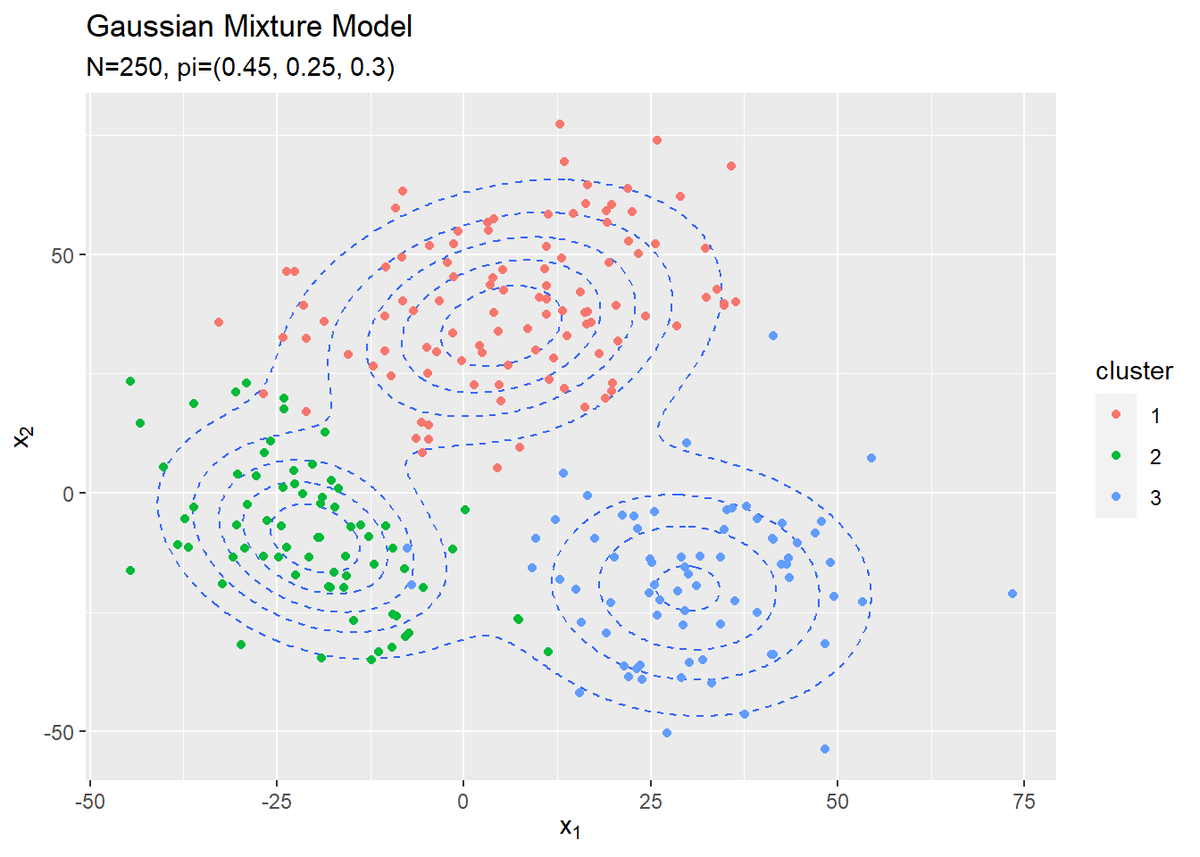
散布図はgeom_point()で描画します。クラスタごとに色分けしています。観測データから各データのクラスタも推定します。
・事前分布の設定
次に、観測モデル(観測データの分布)$p(\mathbf{X} | \mathbf{S}, \boldsymbol{\mu}, \boldsymbol{\Lambda})$と潜在変数の分布$p(\mathbf{S} | \boldsymbol{\pi})$に対する共役事前分布を設定します。多次元ガウス分布のパラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda}$に対する事前分布$p(\boldsymbol{\mu}, \boldsymbol{\Lambda})$としてガウス・ウィシャート分布$\mathrm{NW}(\boldsymbol{\mu}, \boldsymbol{\Lambda} | \mathbf{m}, \beta, \nu, \mathbf{W})$、カテゴリ分布のパラメータ$\boldsymbol{\pi}$に対する事前分布$p(\boldsymbol{\pi})$としてディリクレ分布$p(\boldsymbol{\pi} | \boldsymbol{\alpha})$を設定します。
各事前分布のパラメータ(超パラメータ)を設定します。
# muの事前分布のパラメータを指定 beta <- 1 m_d <- rep(0, D) # lambdaの事前分布のパラメータを指定 w_dd <- diag(D) * 0.0005 nu <- D # piの事前分布のパラメータを指定 alpha_k <- rep(2, K)
$K$個の観測モデルの平均パラメータ$\boldsymbol{\mu}$の共通の事前分布(多次元ガウス分布)の平均パラメータ$\mathbf{m} = (m_1, m_2, \cdots, m_D)$をm_d、精度行列パラメータの係数$\beta$をbetaとして値を指定します。
$K$個の観測モデルの精度行列パラメータ$\boldsymbol{\Lambda}$の共通の事前分布(ウィシャート分布)のパラメータ$\mathbf{W} = (w_{1,1}, \cdots, w_{D,D})$をw_dd、自由度$\nu$をnuとして値を指定します。$\mathbf{W}$は正定値行列であり、自由度は$\nu > D - 1$の値をとります。
混合比率パラメータ$\boldsymbol{\pi}$の事前分布(ディリクレ分布)のパラメータ$\boldsymbol{\alpha} = (\alpha_1, \alpha_2, \cdots, \alpha_K)$をalpha_kとして、$\alpha_k > 0$の値を指定します。
パラメータを設定できたので、$\boldsymbol{\mu}$の事前分布をグラフで確認しましょう。作図用の$\boldsymbol{\mu}$の点を作成します。
# muの事前分布の標準偏差を計算 sigma_mu_d <- solve(beta * nu * w_dd) %>% diag() %>% sqrt() # 作図用のx軸のmuの値を作成 mu_1_vec <- seq( min(mu_truth_kd[, 1]) - sigma_mu_d[1], max(mu_truth_kd[, 1]) + sigma_mu_d[1], length.out = 250) # 作図用のy軸のmuの値を作成 mu_2_vec <- seq( min(mu_truth_kd[, 2]) - sigma_mu_d[2], max(mu_truth_kd[, 2]) + sigma_mu_d[2], length.out = 250 ) # 作図用のmuの点を作成 mu_point_mat <- cbind( rep(mu_1_vec, times = length(mu_2_vec)), rep(mu_2_vec, each = length(mu_1_vec)) )
$\mathbf{x}$の点のときと同様に作成します。各軸の描画範囲は、真の平均の最小値から事前分布の標準偏差を引いた値から、真の平均の最大値に標準偏差を足した値までとします。事前分布の標準偏差は$(\beta \boldsymbol{\Lambda}_k)^{-1}$の対角成分の平方根です。ただしこの時点では$\boldsymbol{\Lambda}$が未知の値なので、代わりに$\boldsymbol{\Lambda}$の期待値$\mathbb{E}[\boldsymbol{\Lambda}]$を使うことにします。ウィシャート分布の期待値(2.89)より
です。
また、逆行列の計算はsolve()、対角成分の抽出はdiag()、平方根の計算はsqrt()で行えます。
面倒でしたら適当な値を直接指定してください。
$\boldsymbol{\mu}$の事前分布の確率密度を計算して、作図用のデータフレームを作成します。
# muの事前分布をデータフレームに格納 prior_mu_df <- tibble( mu_1 = mu_point_mat[, 1], mu_2 = mu_point_mat[, 2], density = mvnfast::dmvn(X = mu_point_mat, mu = m_d, sigma = solve(beta * nu * w_dd)) )
観測モデルのときと同様に、多次元ガウス分布の確率密度を計算します。ここでも、$\boldsymbol{\mu}$の事前分布の分散共分散行列を$(\beta \mathbb{E}[\boldsymbol{\Lambda}])^{-1}$とします。
作成したデータフレームは次のようになります。
# 確認 head(prior_mu_df)
## # A tibble: 6 x 3 ## mu_1 mu_2 density ## <dbl> <dbl> <dbl> ## 1 -51.6 -51.6 0.0000111 ## 2 -51.2 -51.6 0.0000113 ## 3 -50.7 -51.6 0.0000116 ## 4 -50.3 -51.6 0.0000119 ## 5 -49.8 -51.6 0.0000121 ## 6 -49.3 -51.6 0.0000124
$\boldsymbol{\mu}$の事前分布を作図します。
# 真の平均をデータフレームに格納 mu_df <- tibble( x_1 = mu_truth_kd[, 1], x_2 = mu_truth_kd[, 2] ) # muの事前分布を作図 ggplot() + geom_contour(data = prior_mu_df, aes(x = mu_1, y = mu_2, z = density, color = ..level..)) + # 事前分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の値 labs(title = "Gaussian Distribution", subtitle = paste0("m=(", paste0(m_d, collapse = ", "), ")", ", sigma2_mu=(", paste0(solve(beta * nu * w_dd), collapse = ", "), ")"), x = expression(mu[1]), y = expression(mu[2]))
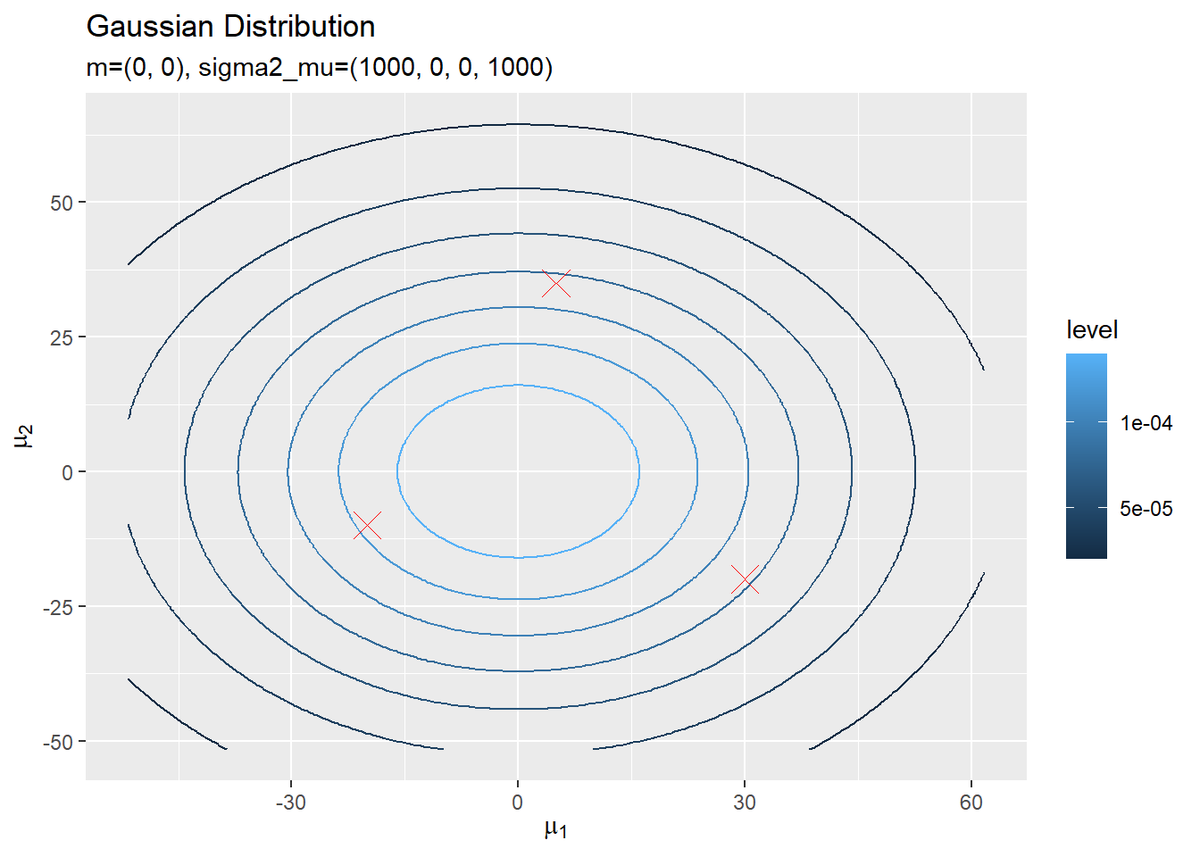
真の平均値をプロットしておきます。この真の平均を分布推定します。
$\boldsymbol{\Lambda}$と$\boldsymbol{\pi}$の事前分布(と事後分布)については省略します。詳しくは、3.2.2 項「カテゴリ分布の学習と予測」と3.4.2項「多次元ガウス分布の学習と予測:精度が未知の場合」を参照してください。
・初期値の設定
設定した各パラメータの事前分布$p(\boldsymbol{\mu} | \boldsymbol{\Lambda}),\ p(\boldsymbol{\Lambda}),\ p(\boldsymbol{\pi})$に従いパラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda},\ \boldsymbol{\pi}$を生成して初期値とします。
$\boldsymbol{\mu},\ \boldsymbol{\Lambda}$の事前分布から観測モデルのパラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda}$を生成します。
# 観測モデルのパラメータをサンプル mu_kd <- matrix(0, nrow = K, ncol = D) lambda_ddk <- array(0, dim = c(D, D, K)) for(k in 1:K) { # クラスタkの精度行列をサンプル lambda_ddk[, , k] <- rWishart(n = 1, df = nu, Sigma = w_dd) # クラスタkの平均をサンプル mu_kd[k, ] <- mvnfast::rmvn(n = 1, mu = m_d, sigma = solve(beta * lambda_ddk[, , k])) %>% as.vector() }
精度行列パラメータ$\boldsymbol{\Lambda}$の事前分布(ウィシャート分布)と平均パラメータ$\boldsymbol{\mu}$の事前分布(多次元ガウス分布)からそれぞれ$K$個のパラメータをサンプルして初期値とします。
ウィシャート分布に従う乱数は、rWishart()で生成できます。クラスタごとに生成するので、データ数の引数nに1を指定します。また、自由度の引数dfにnu、スケール行列の引数Sigmaにw_ddを指定します。
多次元ガウス分布の乱数生成関数mvnfast::rmvn()の引数muにm_d、sigmaには今サンプルしたlambda_ddk[, , k]と係数betaの積をsolve()で逆行列に変換して指定します。
生成したパラメータを確認します。
# 確認
mu_kd
lambda_ddk
## [,1] [,2] ## [1,] -53.59999 148.64908 ## [2,] 113.67250 -157.49942 ## [3,] 124.89589 -66.97592 ## , , 1 ## ## [,1] [,2] ## [1,] 3.824488e-04 9.112352e-05 ## [2,] 9.112352e-05 2.215145e-05 ## ## , , 2 ## ## [,1] [,2] ## [1,] 0.001929030 0.001309451 ## [2,] 0.001309451 0.001018470 ## ## , , 3 ## ## [,1] [,2] ## [1,] 0.0002050408 0.0004737594 ## [2,] 0.0004737594 0.0019467019
$\boldsymbol{\pi}$の事前分布から$\boldsymbol{\pi}$を生成します。
# 混合比率をサンプル pi_k <- MCMCpack::rdirichlet(n = 1, alpha = alpha_k) %>% as.vector()
$\boldsymbol{\pi}$の事前分布(ディリクレ分布)に従い$\boldsymbol{\pi}$をサンプルして初期値とします。
ディリクレ分布に従う乱数は、MCMCpackパッケージのrdirichlet()で生成できます。パラメータの引数alphaにalpha_kを指定します。マトリクスで出力されるため、as.vector()でベクトルに変換しておきます。
生成したパラメータを確認します。
# 確認 pi_k sum(pi_k)
## [1] 0.3411637 0.4360153 0.2228210 ## [1] 1
$K$個の要素の和が1になるのを確認できます。
パラメータの初期値が得られたので、グラフで確認しましょう。初期値を使った分布を計算します 。
# 事前分布からサンプルしたパラメータによる混合分布を計算 init_density <- 0 for(k in 1:K) { # クラスタkの分布の確率密度を計算 tmp_density <- mvnfast::dmvn( X = x_point_mat, mu = mu_kd[k, ], sigma = solve(lambda_ddk[, , k]) ) # K個の分布のの加重平均を計算 init_density <- init_density + pi_k[k] * tmp_density } # 初期値による分布をデータフレームに格納 init_df <- tibble( x_1 = x_point_mat[, 1], x_2 = x_point_mat[, 2], density = init_density ) # 初期値による分布を作図 ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density, color = ..level..), alpha = 0.5, linetype = "dashed") + # 真の分布 geom_contour(data = init_df, aes(x = x_1, y = x_2, z = density, color = ..level..)) + # サンプルによる分布 labs(title = "Gaussian Mixture Model", subtitle = paste0("iter:", 0, ", K=", K), x = expression(x[1]), y = expression(x[2]))
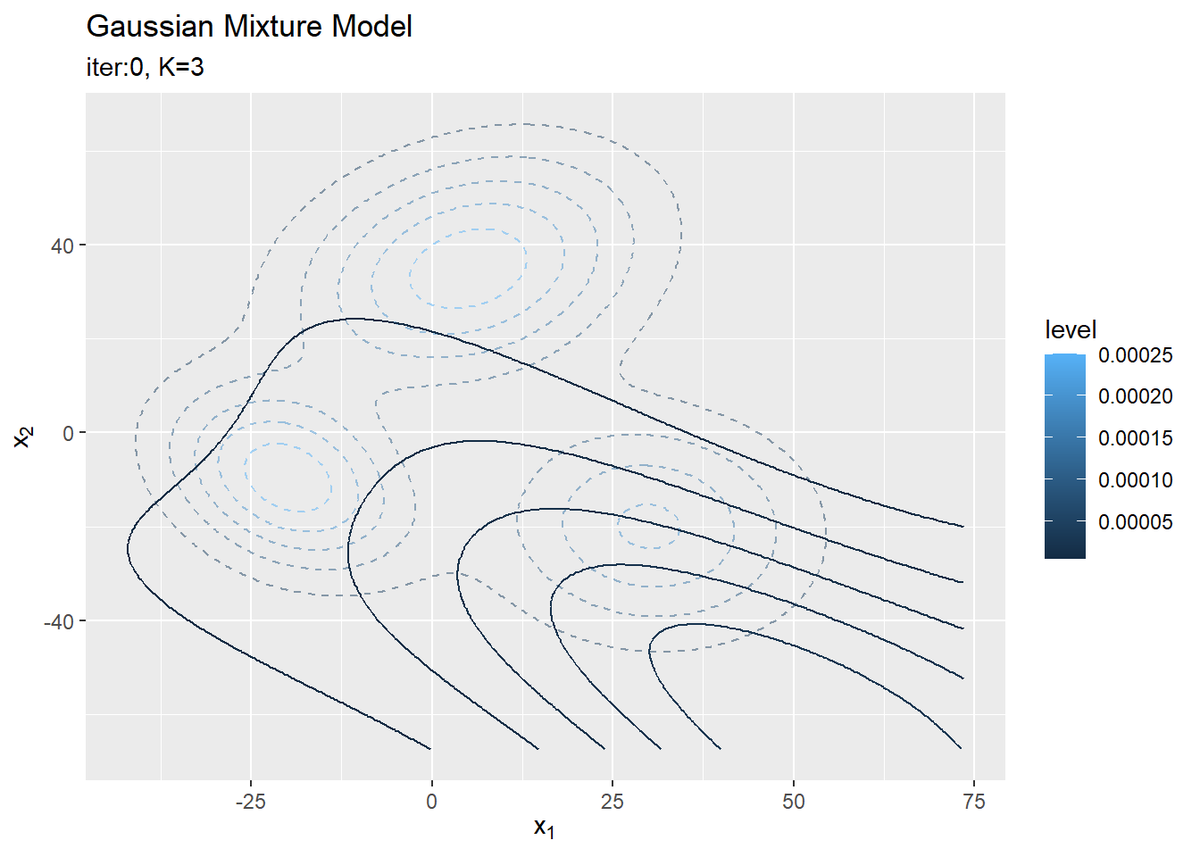
観測モデルのときと同様に作図します。サンプルを繰り返すことで真の分布に近付けていきます。
以上でモデルが整いました。次からは、推論を行っていきます。
・ギブスサンプリング
ギブスサンプリングでは、潜在変数$\mathbf{S}$のサンプリングと、パラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda},\ \boldsymbol{\pi}$のサンプリングを交互に行います。
まずは、パラメータの初期値を用いて$\mathbf{S}$の条件付き分布(事後分布)$p(\mathbf{S} | \mathbf{X}, \boldsymbol{\mu}, \boldsymbol{\Lambda}, \boldsymbol{\pi})$を計算します。得られた条件付き分布から$\mathbf{S}$をサンプルします。次に、サンプルした$\mathbf{S}$を用いて各パラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda},\ \boldsymbol{\pi}$の条件付き分布(事後分布)$p(\boldsymbol{\mu} | \boldsymbol{\Lambda}, \mathbf{X}, \mathbf{S}),\ p(\boldsymbol{\Lambda} | \mathbf{X}, \mathbf{S}),\ p(\boldsymbol{\pi} | \mathbf{X}, \mathbf{S})$を計算します。得られた条件付き分布からパラメータをサンプルします。ここまでが1回の試行です。
さらに次の試行では、前回サンプルしたパラメータを用いて$\mathbf{S}$の条件付き分布を更新となります。この処理を指定した回数繰り返します。
・コード全体
各パラメータの変数に関して、添字を使って代入するため予め変数を用意しておく必要があります。
また、後で各パラメータの更新値や分布の推移を確認するために、それぞれ試行ごとにtrace_***に値を保存していきます。関心のあるパラメータを記録してください。
# 試行回数を指定 MaxIter <- 200 # パラメータを初期化 eta_nk <- matrix(0, nrow = N, ncol = K) s_nk <- matrix(0, nrow = N, ncol = K) beta_hat_k <- rep(0, K) m_hat_kd <- matrix(0, nrow = K, ncol = D) w_hat_ddk <- array(0, dim = c(D, D, K)) nu_hat_k <- rep(0, K) alpha_hat_k <- rep(0, K) # 推移の確認用の受け皿を初期化 trace_s_in <- matrix(0, nrow = MaxIter + 1, ncol = N) trace_mu_ikd <- array(0, dim = c(MaxIter + 1, K, D)) trace_lambda_iddk <- array(0, dim = c(MaxIter + 1, D, D, K)) trace_pi_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_beta_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_m_ikd <- array(0, dim = c(MaxIter + 1, K, D)) trace_w_iddk <- array(0, dim = c(MaxIter + 1, D, D, K)) trace_nu_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) trace_alpha_ik <- matrix(0, nrow = MaxIter + 1, ncol = K) # 初期値を記録 trace_s_in[1, ] <- rep(NA, N) trace_mu_ikd[1, , ] <- mu_kd trace_lambda_iddk[1, , , ] <- lambda_ddk trace_pi_ik[1, ] <- pi_k trace_beta_ik[1, ] <- rep(beta, K) trace_m_ikd[1, , ] <- matrix(rep(m_d, each = K), nrow = K, ncol = D) trace_w_iddk[1, , , ] <- array(rep(w_dd, times = K), dim = c(D, D, K)) trace_nu_ik[1, ] <- rep(nu, K) trace_alpha_ik[1, ] <- alpha_k # ギブスサンプリング for(i in 1:MaxIter) { # 潜在変数の事後分布のパラメータを計算:式(4.94) for(k in 1:K) { tmp_x_dn <- t(x_nd) - mu_kd[k, ] term_x_n <- (t(tmp_x_dn) %*% lambda_ddk[, , k] %*% tmp_x_dn) %>% diag() term_ln <- 0.5 * log(det(lambda_ddk[, , k]) + 1e-7) + log(pi_k[k] + 1e-7) eta_nk[, k] <- exp(term_ln - 0.5 * term_x_n) } eta_nk <- eta_nk / rowSums(eta_nk) # 正規化 # 潜在変数をサンプル:式(4.39) for(n in 1:N) { s_nk[n, ] <- rmultinom(n = 1, size = 1, prob = eta_nk[n, ]) %>% as.vector() } # 観測モデルのパラメータをサンプル for(k in 1:K) { # muの事後分布のパラメータを計算:式(4.99) beta_hat_k[k] <- sum(s_nk[, k]) + beta m_hat_kd[k, ] <- (colSums(s_nk[, k] * x_nd) + beta * m_d) / beta_hat_k[k] # lambdaの事後分布のパラメータを計算:式(4.103) term_x_dd <- t(s_nk[, k] * x_nd) %*% x_nd term_m_dd <- beta * matrix(m_d) %*% t(m_d) term_m_hat_dd <- beta_hat_k[k] * matrix(m_hat_kd[k, ]) %*% t(m_hat_kd[k, ]) w_hat_ddk[, , k] <- solve( term_x_dd + term_m_dd - term_m_hat_dd + solve(w_dd) ) nu_hat_k[k] <- sum(s_nk[, k]) + nu # lambdaをサンプル:式(4.102) lambda_ddk[, , k] <- rWishart(n = 1, df = nu_hat_k[k], Sigma = w_hat_ddk[, , k]) # muをサンプル:式(4.98) mu_kd[k, ] <- mvnfast::rmvn( n = 1, mu = m_hat_kd[k, ], sigma = solve(beta_hat_k[k] * lambda_ddk[, , k]) ) %>% as.vector() } # piの事後分布のパラメータを計算:式(4.45) alpha_hat_k <- colSums(s_nk) + alpha_k # piをサンプル:式(4.44) pi_k <- MCMCpack::rdirichlet(n = 1, alpha = alpha_hat_k) %>% as.vector() # i回目のパラメータを記録 trace_s_in[i + 1, ] <- which(t(s_nk) == 1, arr.ind = TRUE) %>% .[, "row"] trace_mu_ikd[i + 1, , ] <- mu_kd trace_lambda_iddk[i + 1, , , ] <- lambda_ddk trace_pi_ik[i + 1, ] <- pi_k trace_beta_ik[i + 1, ] <- beta_hat_k trace_m_ikd[i + 1, , ] <- m_hat_kd trace_w_iddk[i + 1, , , ] <- w_hat_ddk trace_nu_ik[i + 1, ] <- nu_hat_k trace_alpha_ik[i + 1, ] <- alpha_hat_k # 動作確認 #print(paste0(i, ' (', round(i / MaxIter * 100, 1), '%)')) }
・処理の解説
ギブスサンプリングで行う処理を確認していきます。
・潜在変数のサンプリング
潜在変数$\mathbf{S}$の条件付き分布(のパラメータ)を計算して、新たな$\mathbf{S}$をサンプルします。
$\mathbf{S}$の条件付き分布のパラメータを計算します。
# 潜在変数の事後分布のパラメータを計算:式(4.94) for(k in 1:K) { tmp_x_dn <- t(x_nd) - mu_kd[k, ] term_x_n <- (t(tmp_x_dn) %*% lambda_ddk[, , k] %*% tmp_x_dn) %>% diag() term_ln <- 0.5 * log(det(lambda_ddk[, , k]) + 1e-7) + log(pi_k[k] + 1e-7) eta_nk[, k] <- exp(term_ln - 0.5 * term_x_n) } eta_nk <- eta_nk / rowSums(eta_nk) # 正規化
$n$番目のデータの潜在変数$\mathbf{s}_n$の条件付き分布(カテゴリ分布)のパラメータ$\boldsymbol{\eta}_n = (\eta_{n,1}, \eta_{n,2}, \cdots, \eta_{n,K})$の各項は、次の式で計算します。
$\eta_{n,k}$は、$n$番目の観測データ$\mathbf{x}_n$にクラスタ$k$が割り当てられる($s_{n,k} = 1$となる)確率を表します。
ただし、$N$個全てのデータを一度で処理するために、$(\mathbf{x}_n - \boldsymbol{\mu}_k)^{\top} \boldsymbol{\Lambda}_k (\mathbf{x}_n - \boldsymbol{\mu}_k)$の計算を1から$N$の全ての組み合わせで行います(term_x_nの計算)。この計算結果は、$N \times N$のマトリクスになります。これは例えば、1行$N$列目の要素は$(\mathbf{x}_1 - \boldsymbol{\mu}_k)^{\top} \boldsymbol{\Lambda}_k (\mathbf{x}_N - \boldsymbol{\mu}_k)$の計算結果です。これは不要なので、diag()で対角成分(同じデータによる計算結果)のみを取り出します。
また、対数の計算において$\ln 0$とならないように、微小な値1e-7($10^{-7} = 0.0000001$)を加えています。
最後に、データごとの和が1となるように
で正規化します。
# 確認 round(eta_nk[1:5, ], 4) rowSums(eta_nk[1:5, ])
## [,1] [,2] [,3] ## [1,] 0.1316 0.8684 0.0000 ## [2,] 0.0007 0.0000 0.9993 ## [3,] 0.9982 0.0017 0.0001 ## [4,] 1.0000 0.0000 0.0000 ## [5,] 0.0038 0.0000 0.9961 ## [1] 1 1 1 1 1
行(データ)ごとの和が1になるのを確認できます。
eta_nkを用いて、新たな$\mathbf{S}$を生成します。
# 潜在変数をサンプル:式(4.39) for(n in 1:N) { s_nk[n, ] <- rmultinom(n = 1, size = 1, prob = eta_nk[n, ]) %>% as.vector() }
真のクラスタのときと同様に、潜在変数をサンプルします。
ただし、ここではデータによってパラメータ(各クラスタの割り当て確率)が異なるため、for()で1データずつ生成します。
# 確認 s_nk[1:5, ]
## [,1] [,2] [,3] ## [1,] 1 0 0 ## [2,] 0 0 1 ## [3,] 1 0 0 ## [4,] 1 0 0 ## [5,] 0 0 1
これで$\mathbf{S}$が得られました。次は、更新した$\mathbf{S}$を用いて、パラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda},\ \boldsymbol{\pi}$を更新します。
・観測モデルのパラメータのサンプリング
観測モデルのパラメータ$\boldsymbol{\mu},\ \boldsymbol{\Lambda}$の条件付き分布(のパラメータ)を計算し、新たな$\boldsymbol{\mu},\ \boldsymbol{\Lambda}$をサンプルします。
$\boldsymbol{\mu}_k$の条件付き分布のパラメータを計算します。
# muの事後分布のパラメータを計算:式(4.99) beta_hat_k[k] <- sum(s_nk[, k]) + beta m_hat_kd[k, ] <- (colSums(s_nk[, k] * x_nd) + beta * m_d) / beta_hat_k[k]
$\boldsymbol{\mu}_k$の条件付き分布(多次元ガウス分布)の平均パラメータ$\hat{\mathbf{m}}_k = (\hat{m}_{k,1}, \hat{m}_{k,2}, \cdots, \hat{m}_{k,D})$、精度行列パラメータの係数$\hat{\beta}_k$を
で計算して、それぞれbeta_hat_k、m_hat_kdに代入します。
# 確認
beta_hat_k
m_hat_kd
## [1] 112 68 73 ## [,1] [,2] ## [1,] 6.384165 37.034271 ## [2,] -20.349459 -7.240235 ## [3,] 29.922451 -20.440525
ちなみに、$\sum_{n=1}^N s_{n,k} \mathbf{x}_n$の計算に注目すると
k <- 1 # クラスタ番号 round(x_nd[1:5, ], 1) s_nk[1:5, k]
## [,1] [,2] ## [1,] -25.8 10.8 ## [2,] 43.3 -14.9 ## [3,] -0.3 27.7 ## [4,] 3.2 56.7 ## [5,] 31.6 -13.3 ## [1] 1 0 1 1 0
round(s_nk[1:5, k] * x_nd[1:5, ], 1) colSums(s_nk[1:5, k] * x_nd[1:5, ])
## [,1] [,2] ## [1,] -25.8 10.8 ## [2,] 0.0 0.0 ## [3,] -0.3 27.7 ## [4,] 3.2 56.7 ## [5,] 0.0 0.0 ## [1] -22.89500 95.19163
対象としているクラスタのデータには1を掛けてそのままの値で、それ以外のクラスタのデータには0を掛けて値が0になっています。つまり、対象となるクラスタのデータのみの和をとっています。
同様に、$\sum_{n=1}^N s_{n,k}$は各クラスタが割り当てられたデータ数を表します。
$\boldsymbol{\lambda}_k$の条件付き分布のパラメータを計算します。
# lambdaの事後分布のパラメータを計算:式(4.103) term_x_dd <- t(s_nk[, k] * x_nd) %*% x_nd term_m_dd <- beta * matrix(m_d) %*% t(m_d) term_m_hat_dd <- beta_hat_k[k] * matrix(m_hat_kd[k, ]) %*% t(m_hat_kd[k, ]) w_hat_ddk[, , k] <- solve( term_x_dd + term_m_dd - term_m_hat_dd + solve(w_dd) ) nu_hat_k[k] <- sum(s_nk[, k]) + nu
$\boldsymbol{\lambda}_k$の条件付き分布(ウィシャート分布)のパラメータ$\hat{\mathbf{W}}_k = (\hat{w}_{k,1,1}, \cdots, \hat{w}_{k,D,D})$、自由度$\hat{\nu}_k$を
で計算して、結果をそれぞれnu_hat_k、w_hat_ddkに代入します。
# 確認
w_hat_ddk
nu_hat_k
## , , 1 ## ## [,1] [,2] ## [1,] 3.412730e-05 -8.933286e-06 ## [2,] -8.933286e-06 2.869736e-05 ## ## , , 2 ## ## [,1] [,2] ## [1,] 1.055681e-04 2.562018e-05 ## [2,] 2.562018e-05 6.879874e-05 ## ## , , 3 ## ## [,1] [,2] ## [1,] 5.902063e-05 -6.077742e-06 ## [2,] -6.077742e-06 6.807059e-05 ## [1] 113 69 74
nu_hat_k, w_hat_ddkを用いて、新たな$\boldsymbol{\lambda}_k$を生成します。
# lambdaをサンプル:式(4.102) lambda_ddk[, , k] <- rWishart(n = 1, df = nu_hat_k[k], Sigma = w_hat_ddk[, , k])
パラメータ$\hat{\mathbf{W}}_k$を持つ自由度$\hat{\nu}_k$のウィシャート分布から$\boldsymbol{\lambda}_k$をサンプルします。
初期値のときと同様に、rWishart()の自由度の引数dfにnu_hat_k[k]、スケール行列の引数Sigmaにw_hat_ddk[, , k]を指定します。
# 確認 lambda_ddk[, , k]
## [,1] [,2] ## [1,] 0.00345997 -0.001146610 ## [2,] -0.00114661 0.003373867
m_hat_kd, beta_hat_kとlambda_ddkを用いて、新たな$\boldsymbol{\mu}_k$を生成します。
# muをサンプル:式(4.98) mu_kd[k, ] <- mvnfast::rmvn( n = 1, mu = m_hat_kd[k, ], sigma = solve(beta_hat_k[k] * lambda_ddk[, , k]) ) %>% as.vector()
平均$\hat{\mathbf{m}}_k$、精度行列$\hat{\beta}_k \boldsymbol{\lambda}_k$の多次元ガウス分布から$\boldsymbol{\mu}_k$をサンプルします。
mvnfast::rmvn()の平均の引数muにm_hat_kd[k]、分散共分散行列の引数sigmaに今サンプルしたlambda_ddk[, , k]と係数beta_hat_k[k]との積をsolve()で逆行列に変換して指定します。
# 確認 mu_kd[k, ]
## [1] 4.257461 37.551694
ここまでの処理をfor()ループで$K$回行うことで、$K$個のクラスタの超パラメータ$\hat{\mathbf{m}} = \{\hat{\mathbf{m}}_1, \hat{\mathbf{m}}_2, \cdots, \hat{\mathbf{m}}_K\}$、$\hat{\boldsymbol{\beta}} = \{\hat{\beta}_1, \hat{\beta}_2, \cdots, \hat{\beta}_k\}$、$\hat{\boldsymbol{\nu}} = \{\hat{\nu}_1, \hat{\nu}_2, \cdots, \hat{\nu}_K\}$、$\hat{\mathbf{W}} = \{\hat{\mathbf{W}}_1, \hat{\mathbf{W}}_2, \cdots, \hat{\mathbf{W}}_K\}$が得られます。
・混合比率のサンプリング
混合比率パラメータ$\boldsymbol{\pi}$の条件付き分布(のパラメータ)を計算し、新たな$\boldsymbol{\pi}$をサンプルします。
$\boldsymbol{\pi}$の条件付き分布のパラメータを計算します。
# piの事後分布のパラメータを計算:式(4.45) alpha_hat_k <- colSums(s_nk) + alpha_k
$\boldsymbol{\pi}$の条件付き分布(ディリクレ分布)のパラメータ$\hat{\boldsymbol{\alpha}} = (\hat{\alpha}_1, \hat{\alpha}_2, \cdots, \hat{\alpha}_K)$の各項を
で計算して、結果をalpha_hat_kとします。
# 確認
alpha_hat_k
## [1] 113 69 74
alpha_hat_kを用いて、新たな$\boldsymbol{\pi}$を生成します。
# piをサンプル:式(4.44) pi_k <- MCMCpack::rdirichlet(n = 1, alpha = alpha_hat_k) %>% as.vector()
パラメータ$\hat{\boldsymbol{\alpha}}$を持つディリクレ分布から$\boldsymbol{\pi}$をサンプルします。
事前分布からのサンプルのときと同様に、MCMCpack::rdirichlet()の引数alphaにalpha_hat_kを指定します。
# 確認 pi_k sum(pi_k)
## [1] 0.4486537 0.2708860 0.2804603 ## [1] 1
以上がギブスサンプリングによる近似推論で行うの個々の処理です。これを指定した回数繰り返し行うことで、各パラメータの値を徐々に真の値に近付けていきます。
・推論結果の確認
推論結果を確認していきます。
・最後のパラメータの確認
超パラメータm_hat_k, beta_hat_kとlambda_ddkの最後の更新値を用いて、$\boldsymbol{\mu}$の事後分布を計算します。
# muの事後分布をデータフレームに格納 posterior_mu_df <- tibble() for(k in 1:K) { # クラスタkのmuの事後分布を計算 tmp_density <- mvnfast::dmvn( X = mu_point_mat, mu = m_hat_kd[k, ], sigma = solve(beta_hat_k[k] * lambda_ddk[, , k]) ) # クラスタkの分布をデータフレームに格納 tmp_df <- tibble( mu_1 = mu_point_mat[, 1], mu_2 = mu_point_mat[, 2], density = tmp_density, cluster = as.factor(k) ) # 結果を結合 posterior_mu_df <- rbind(posterior_mu_df, tmp_df) }
事前分布のときと同様に計算します。ただし、超パラメータが$K$個になったので、多次元ガウス分布も$K$個になります。$K$回分の計算結果をデータフレームに格納していきます。
クラスタ$k$の事後分布の平均は$\hat{\mathbf{m}}_k$、精度行列は$\hat{\beta}_k \boldsymbol{\Lambda}_k$です。
作成したデータフレームは次のようになります。
# 確認 head(posterior_mu_df)
head(posterior_mu_df) ## # A tibble: 6 x 4 ## mu_1 mu_2 density cluster ## <dbl> <dbl> <dbl> <fct> ## 1 -51.6 -51.6 0 1 ## 2 -51.2 -51.6 0 1 ## 3 -50.7 -51.6 0 1 ## 4 -50.3 -51.6 0 1 ## 5 -49.8 -51.6 0 1 ## 6 -49.3 -51.6 0 1
$\boldsymbol{\mu}$の事後分布を作図します。
# muの事後分布を作図 ggplot() + geom_contour(data = posterior_mu_df, aes(x = mu_1, y = mu_2, z = density, color = cluster)) + # 事後分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の値 labs(title = "Gaussian Distribution:Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N), x = expression(mu[1]), y = expression(mu[2]))
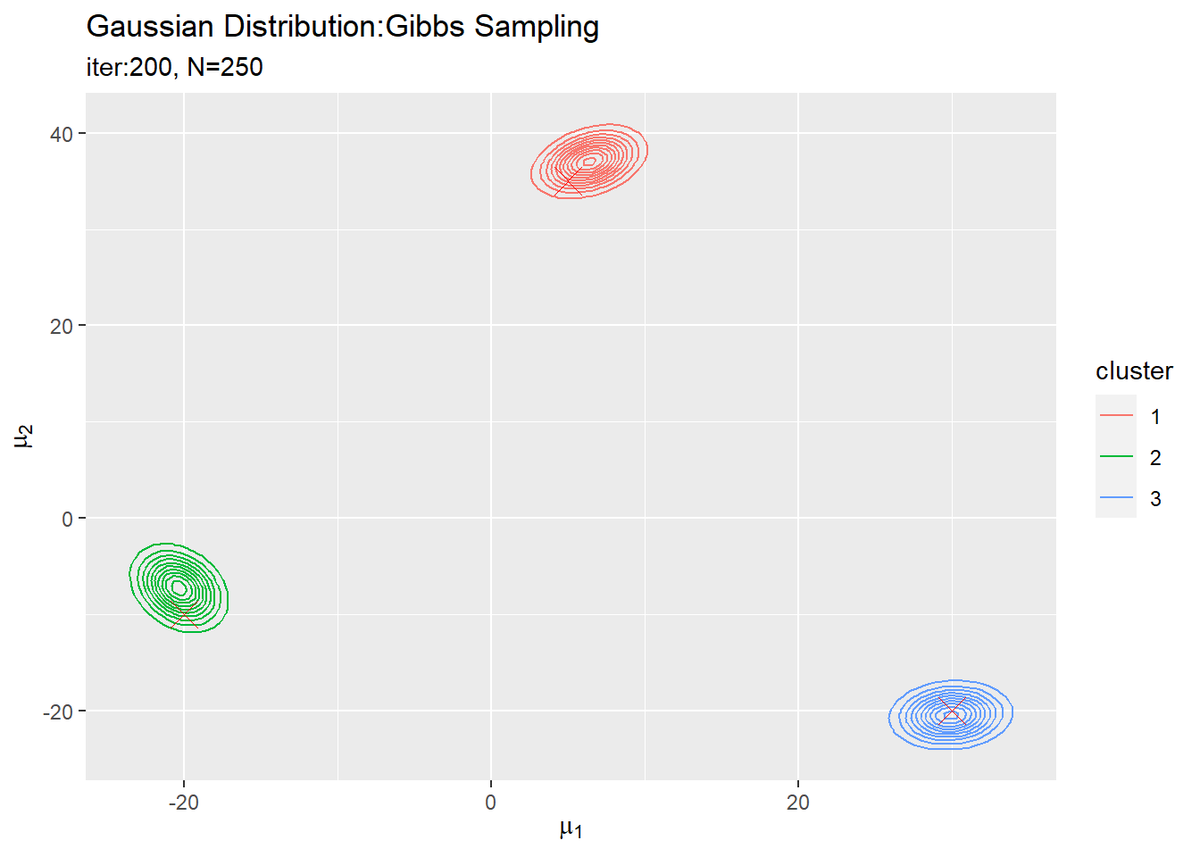
事前分布のときと同様に作図できます。
$K$個のガウス分布がそれぞれ真の平均付近をピークとする分布を推定できています。
最後の試行でサンプルしたパラメータmu_kd, lambda_ddkとpi_kを用いて、混合分布を計算します。
# 最後にサンプルしたパラメータによる混合分布を計算 res_density <- 0 for(k in 1:K) { # クラスタkの分布の確率密度を計算 tmp_density <- mvnfast::dmvn( X = x_point_mat, mu = mu_kd[k, ], sigma = solve(lambda_ddk[, , k]) ) # K個の分布の加重平均を計算 res_density <- res_density + pi_k[k] * tmp_density } # 最終的な分布をデータフレームに格納 res_df <- tibble( x_1 = x_point_mat[, 1], x_2 = x_point_mat[, 2], density = res_density ) # 最終的な分布を作図 ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density, color = ..level..), alpha = 0.5, linetype = "dashed") + # 真の分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の平均 geom_contour(data = res_df, aes(x = x_1, y = x_2, z = density, color = ..level..)) + # サンプルによる分布 geom_point(data = x_df, aes(x = x_n1, y = x_n2)) + # 観測データ labs(title = "Gaussian Mixture Model:Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N, ", K=", K), x = expression(x[1]), y = expression(x[2]))
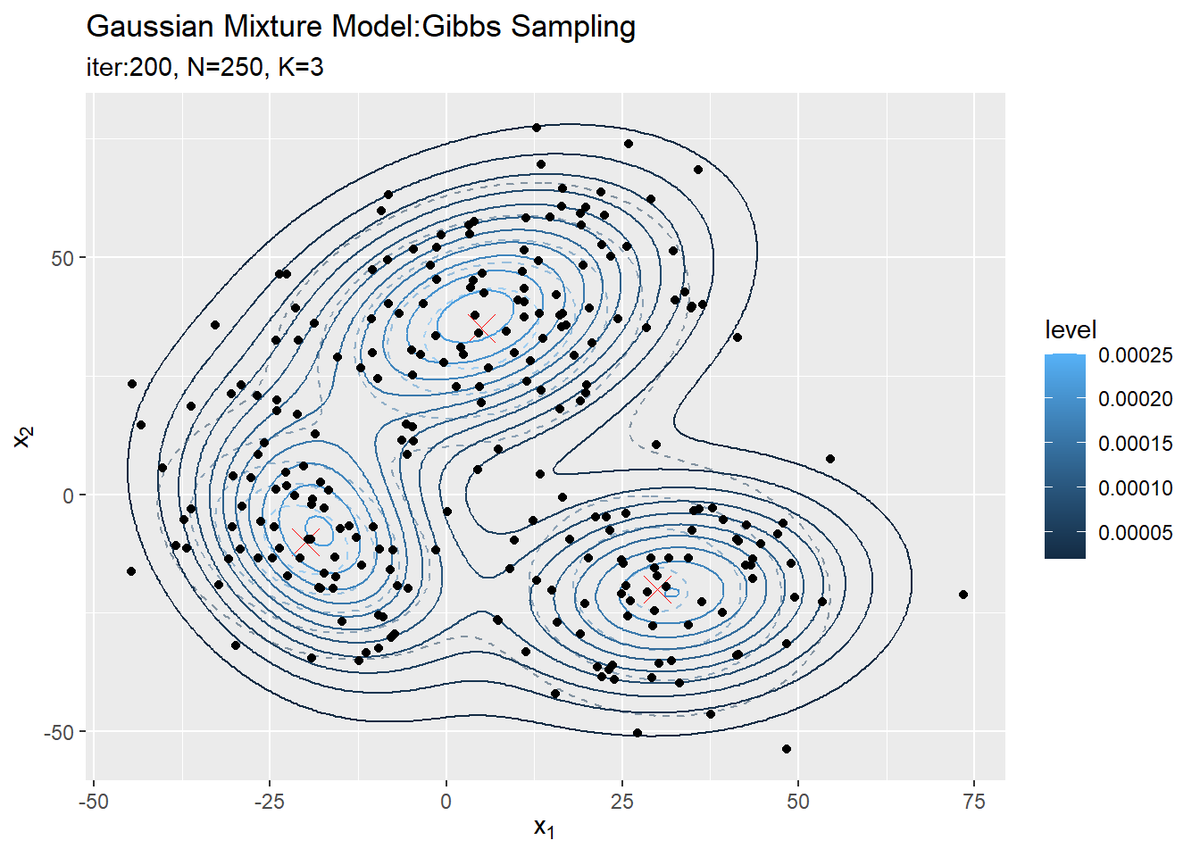
変数名やタイトル以外は「初期値の設定」のときと同じコードです。
最後にサンプルしたクラスタの散布図を作成します。
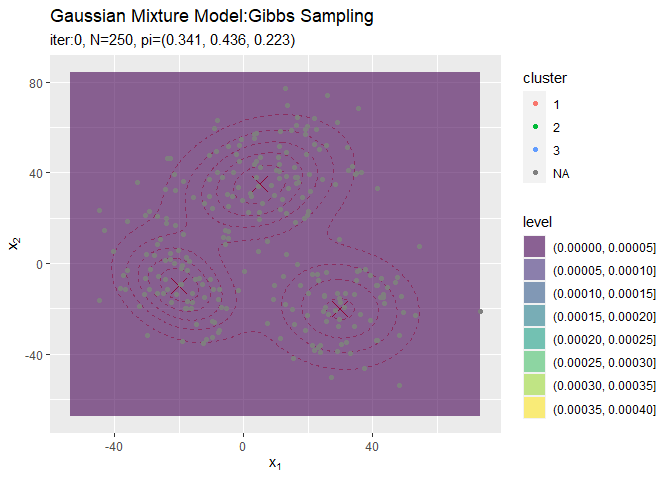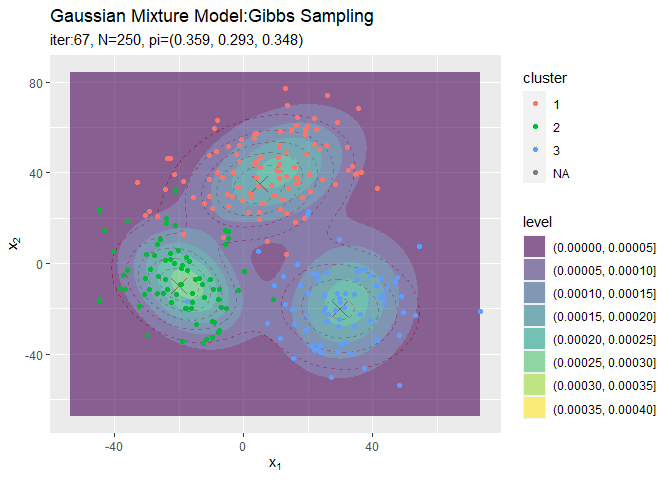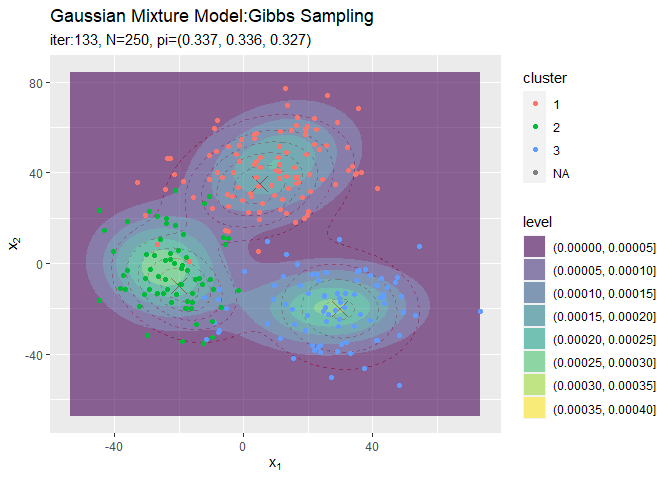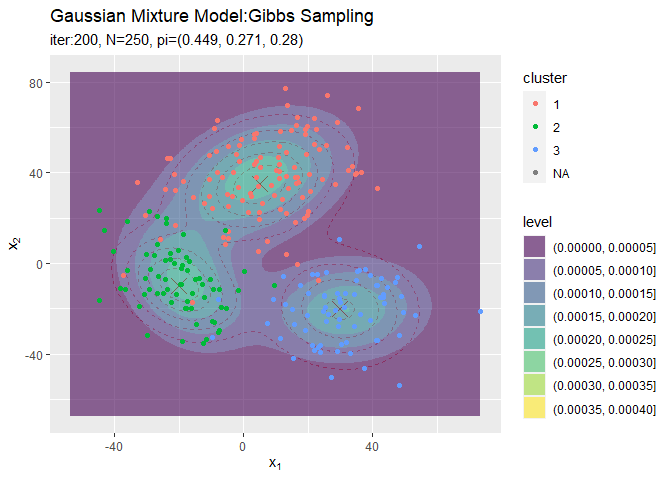
# 観測データと最後にサンプルしたクラスタ番号をデータフレームに格納 s_df <- tibble( x_n1 = x_nd[, 1], x_n2 = x_nd[, 2], cluster = which(t(s_nk) == 1, arr.ind = TRUE) %>% .[, "row"] %>% as.factor() ) # 最終的なクラスタを作図 ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density), color = "red", alpha = 0.5, linetype = "dashed") + # 真の分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の平均 geom_contour_filled(data = res_df, aes(x = x_1, y = x_2, z = density, fill = ..level..), alpha = 0.6) + # サンプルによる分布 geom_point(data = s_df, aes(x = x_n1, y = x_n2, color = cluster)) + # サンプルしたクラスタ labs(title = "Gaussian Mixture Model:Gibbs Sampling", subtitle = paste0("iter:", MaxIter, ", N=", N, ", pi=(", paste0(round(pi_k, 3), collapse = ", "), ")"), x = expression(x[1]), y = expression(x[2]))
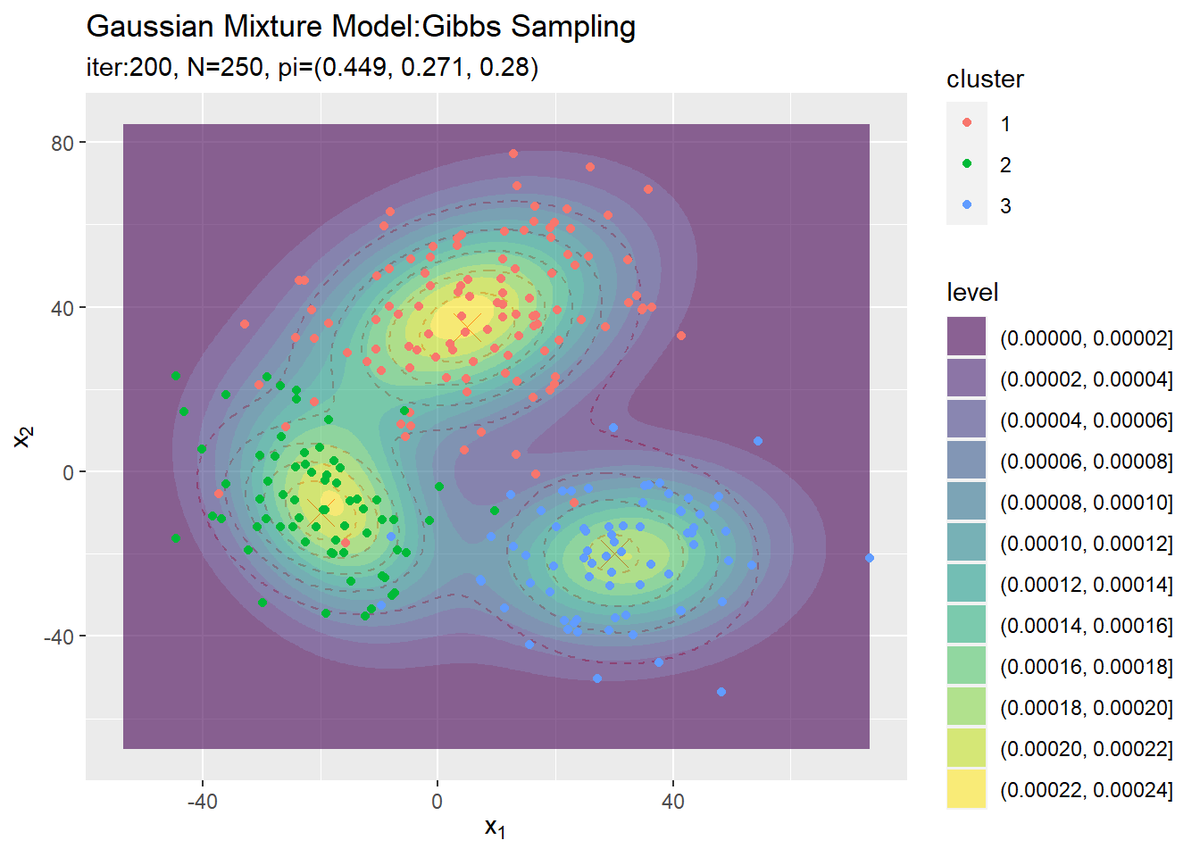
クラスタリングできていることが確認できます。ただし、クラスタの番号についてはランダムに決まるため真のクラスタの番号と一致しません。
・超パラメータの推移の確認
超パラメータ$\hat{\mathbf{m}},\ \hat{\boldsymbol{\beta}},\ \hat{\boldsymbol{\nu}}, \hat{\mathbf{W}},\ \hat{\boldsymbol{\alpha}}$の更新値の推移を確認します。
・コード(クリックで展開)
学習ごとの値を格納した各パラメータのマトリクスtrace_***をtidyr::pivot_longer()で縦長のデータフレームに変換して作図します。
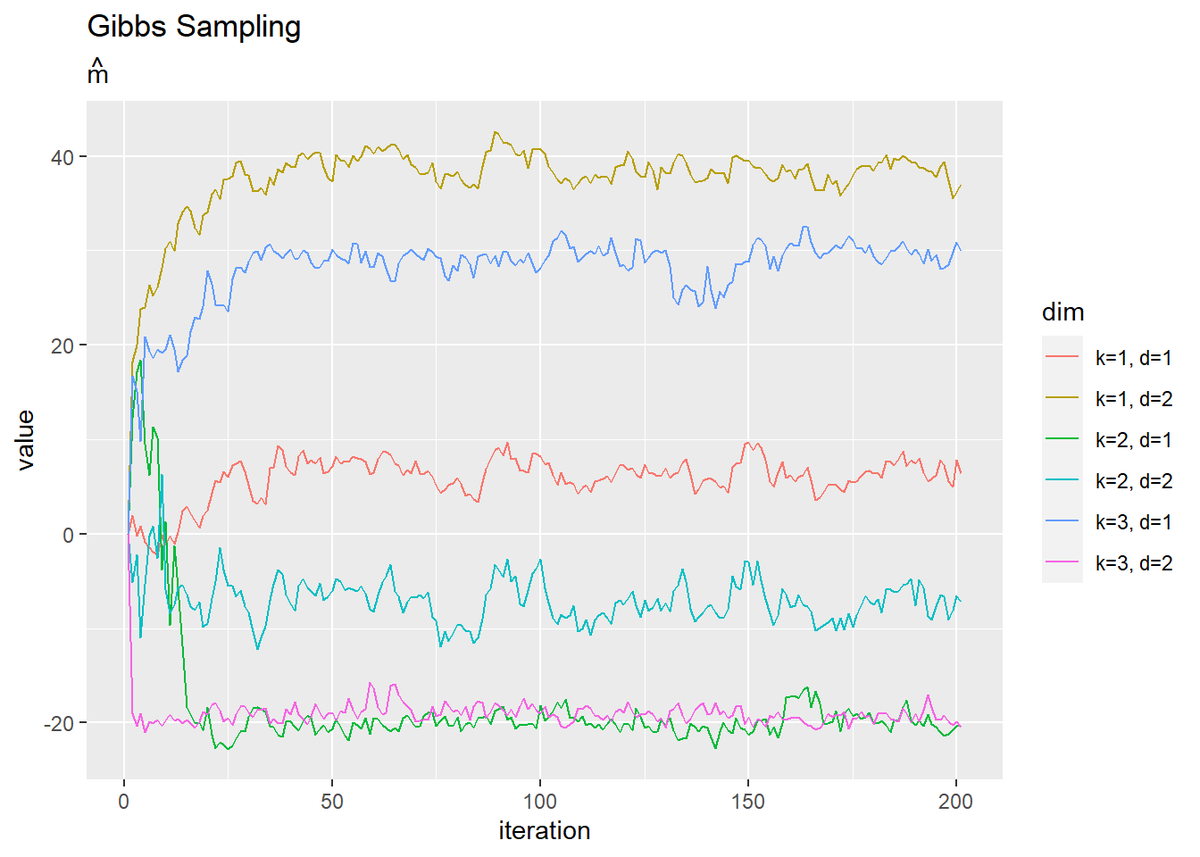
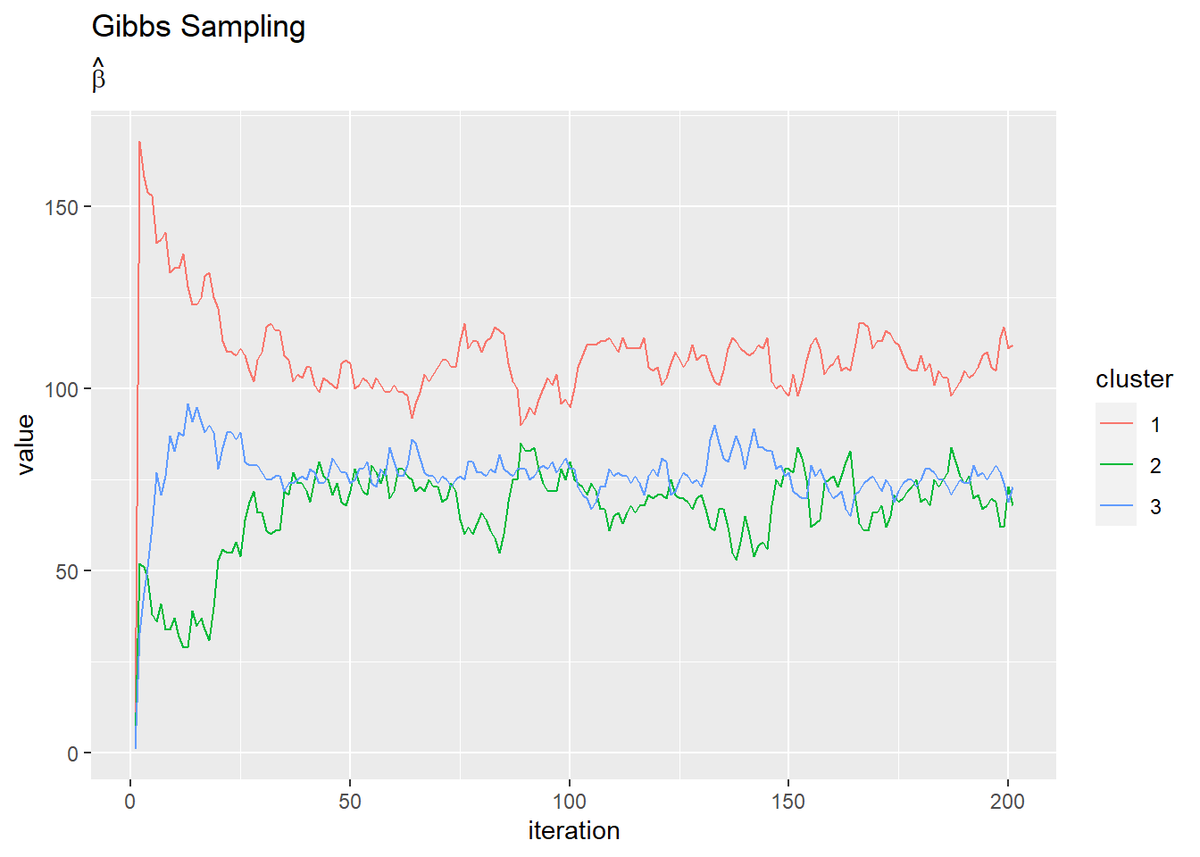
# mの推移を作図 dplyr::as_tibble(trace_m_ikd) %>% # データフレームに変換 magrittr::set_names( paste0(rep(paste0("k=", 1:K), D), rep(paste0(", d=", 1:D), each = K)) ) %>% # 列名として次元情報を付与 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "dim", # 現列名を格納する列名 values_to = "value" # 現要素を格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = dim)) + geom_line() + labs(title = "Gibbs Sampling", subtitle = expression(hat(m)))
# betaの推移を作図 dplyr::as_tibble(trace_beta_ik) %>% # データフレームに変換 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = cluster)) + geom_line() + # 推定値 labs(title = "Gibbs Sampling", subtitle = expression(hat(beta)))
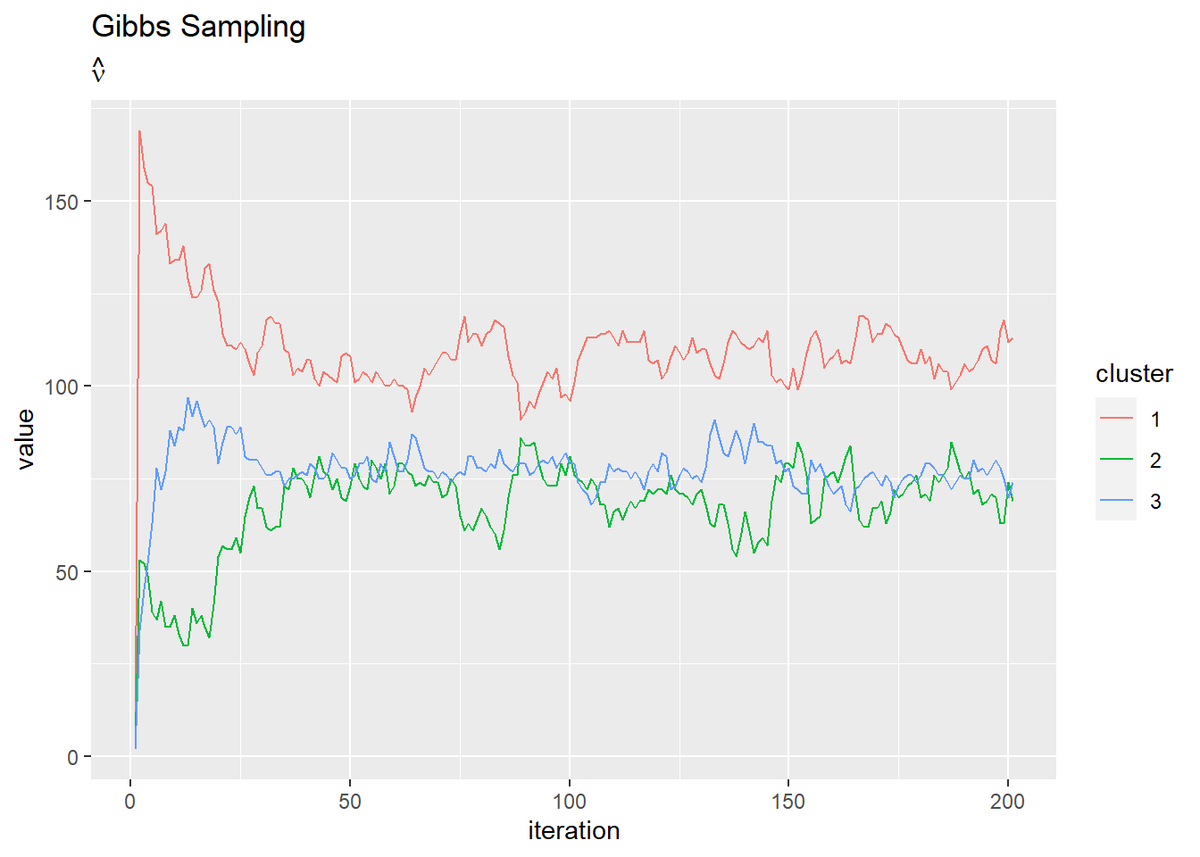
# nuの推移を作図 dplyr::as_tibble(trace_nu_ik) %>% # データフレームに変換 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = cluster)) + geom_line() + # 推定値 labs(title = "Gibbs Sampling", subtitle = expression(hat(nu)))
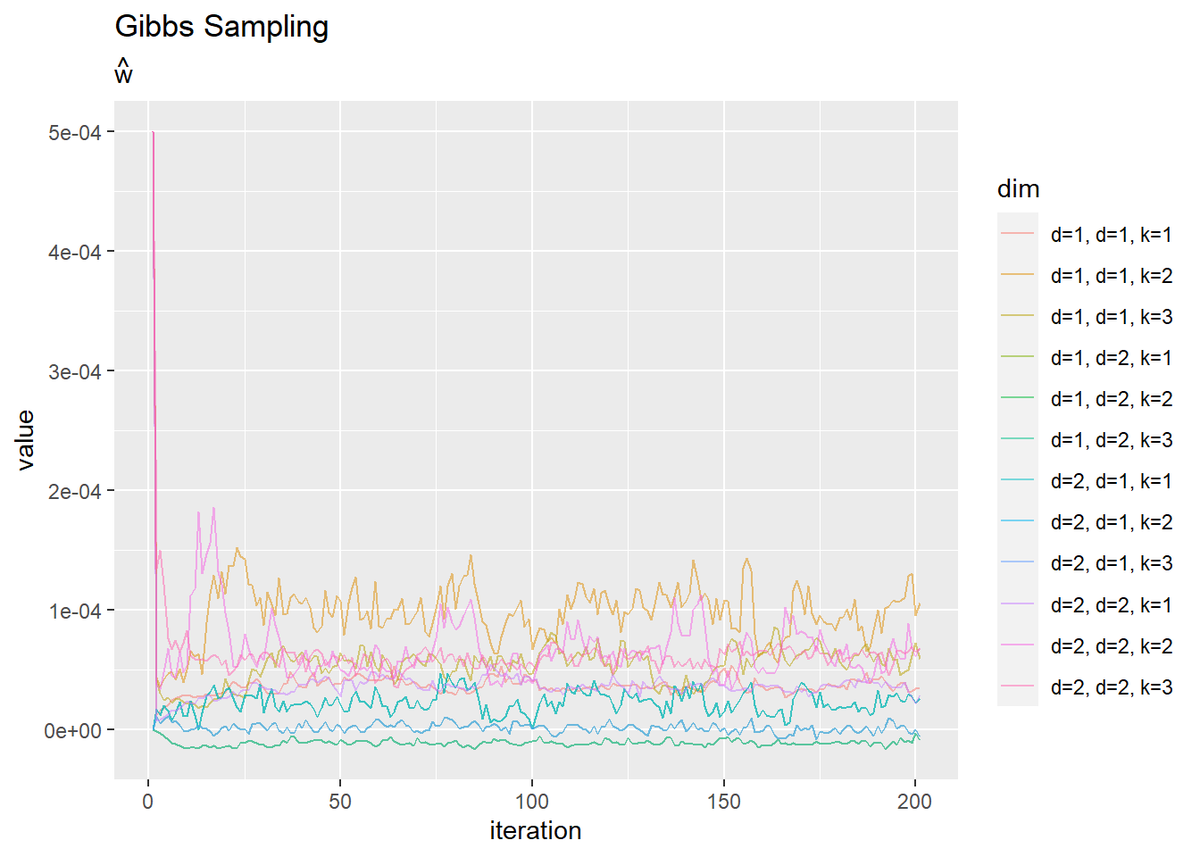
# wの推移を作図 dplyr::as_tibble(trace_w_iddk) %>% # データフレームに変換 magrittr::set_names( paste0( rep(paste0("d=", 1:D), times = D * K), rep(rep(paste0(", d=", 1:D), each = D), times = K), rep(paste0(", k=", 1:K), each = D * D) ) ) %>% # 列名として次元情報を付与 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "dim", # 現列名を格納する列名 values_to = "value" # 現要素を格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = dim)) + geom_line(alpha = 0.5) + labs(title = "Gibbs Sampling", subtitle = expression(hat(w)))
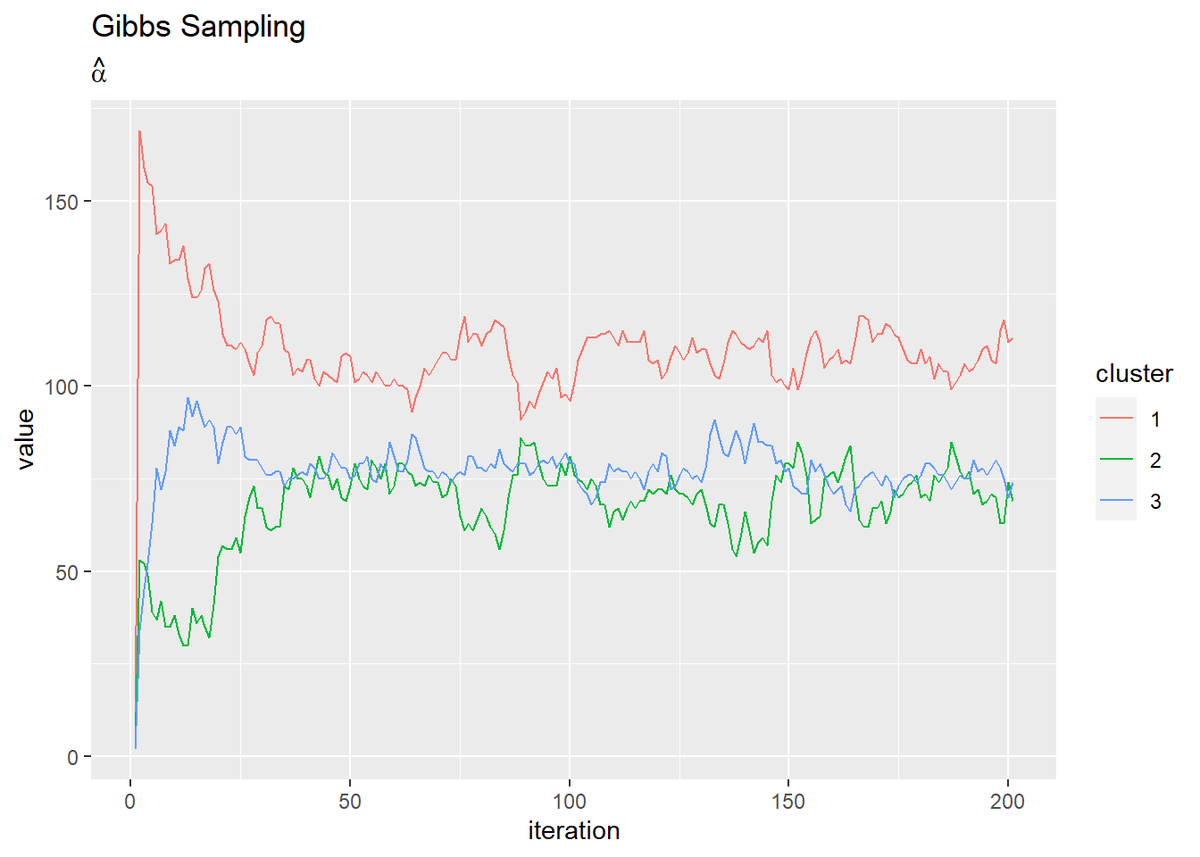
# alphaの推移を作図 dplyr::as_tibble(trace_alpha_ik) %>% # データフレームに変換 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = cluster)) + geom_line() + # 推定値 labs(title = "Gibbs Sampling", subtitle = expression(hat(alpha)))
・パラメータのサンプルの推移の確認
サンプルされた$\boldsymbol{\mu},\ \boldsymbol{\Lambda},\ \boldsymbol{\pi}$の値の推移を確認しましょう。
・コード(クリックで展開)
同様に作図します。それぞれ真の値***_truthを水平線geom_hline()で描画しておきます。
# muの推移を作図 dplyr::as_tibble(trace_mu_ikd) %>% # データフレームに変換 magrittr::set_names( paste0(rep(paste0("k=", 1:K), D), rep(paste0(", d=", 1:D), each = K)) ) %>% # 列名として次元情報を付与 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "dim", # 現列名を格納する列名 values_to = "value" # 現要素を格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = dim)) + geom_line() + geom_hline(yintercept = as.vector(mu_truth_kd), color = "red", linetype = "dashed") + # 真の値 labs(title = "Gibbs Sampling", subtitle = expression(mu))
# 分散共分散行列を精度行列に変換 lambda_truth_ddk <- array(0, dim = c(D, D, K)) for(k in 1:K) { lambda_truth_ddk[, , k] <- solve(sigma2_truth_ddk[, , k]) } # lambdaの推移を作図 dplyr::as_tibble(trace_lambda_iddk) %>% # データフレームに変換 magrittr::set_names( paste0( rep(paste0("d=", 1:D), times = D * K), rep(rep(paste0(", d=", 1:D), each = D), times = K), rep(paste0(", k=", 1:K), each = D * D) ) ) %>% # 列名として次元情報を付与 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "dim", # 現列名を格納する列名 values_to = "value" # 現要素を格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = dim)) + geom_line(alpha = 0.5) + geom_hline(yintercept = as.vector(lambda_truth_ddk), color = "red", linetype = "dashed") + # 真の値 labs(title = "Gibbs Sampling", subtitle = expression(Lambda))
# piの推移を作図 dplyr::as_tibble(trace_pi_ik) %>% # データフレームに変換 cbind(iteration = 1:(MaxIter + 1)) %>% # 試行回数の列を追加 tidyr::pivot_longer( cols = -iteration, # 変換しない列 names_to = "cluster", # 現列名を格納する列名 names_prefix = "V", # 現列名の頭から取り除く文字列 names_ptypes = list(cluster = factor()), # 現列名を値とする際の型 values_to = "value" # 現セルを格納する列名 ) %>% # 縦持ちに変換 ggplot(aes(x = iteration, y = value, color = cluster)) + geom_line() + # 推定値 geom_hline(yintercept = pi_truth_k, color = "red", linetype = "dashed") + # 真の値 labs(title = "Gibbs Sampling", subtitle = expression(pi))
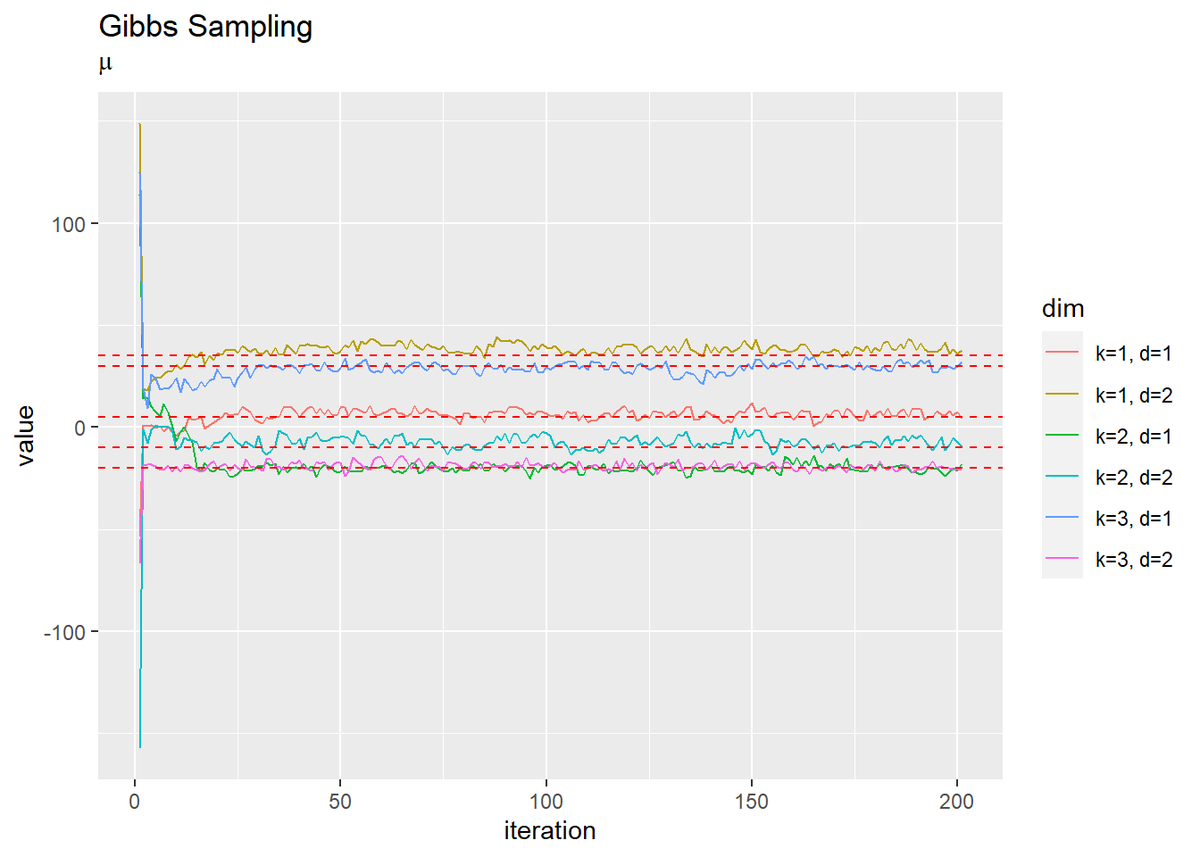
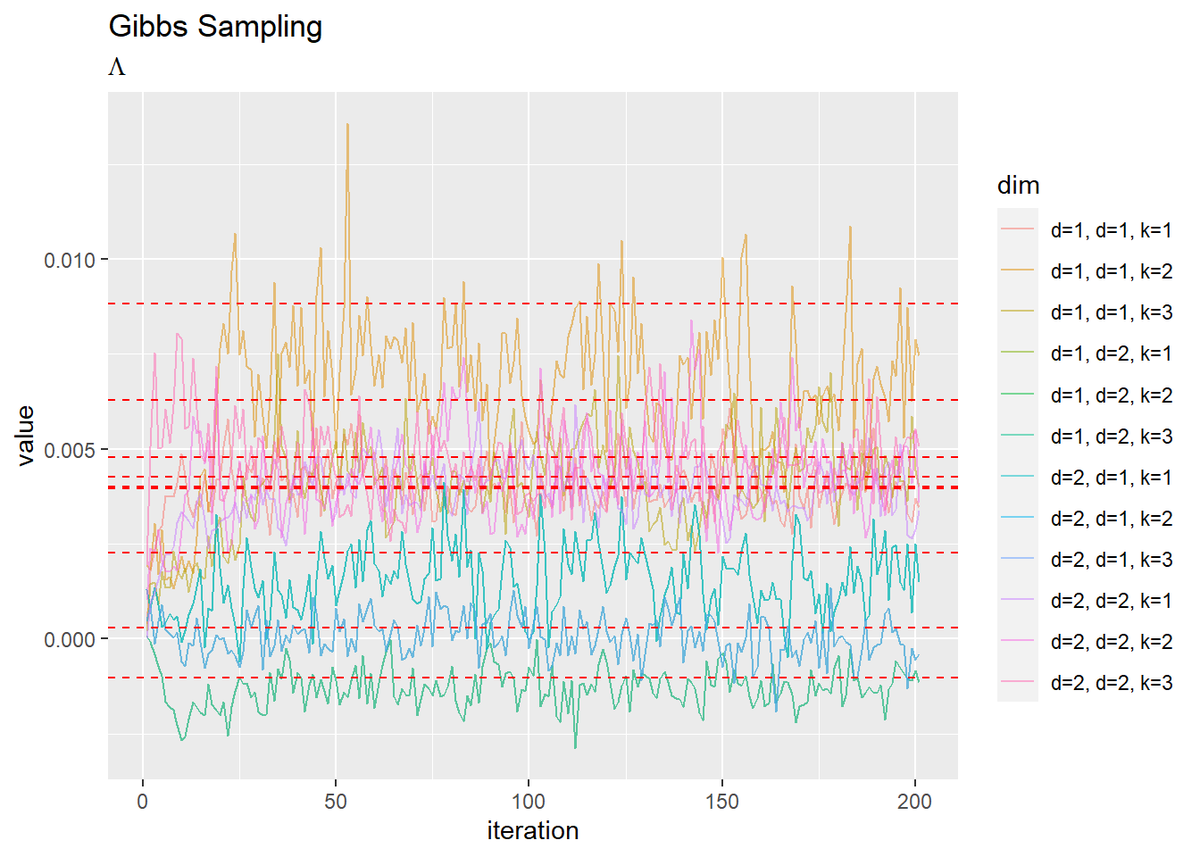
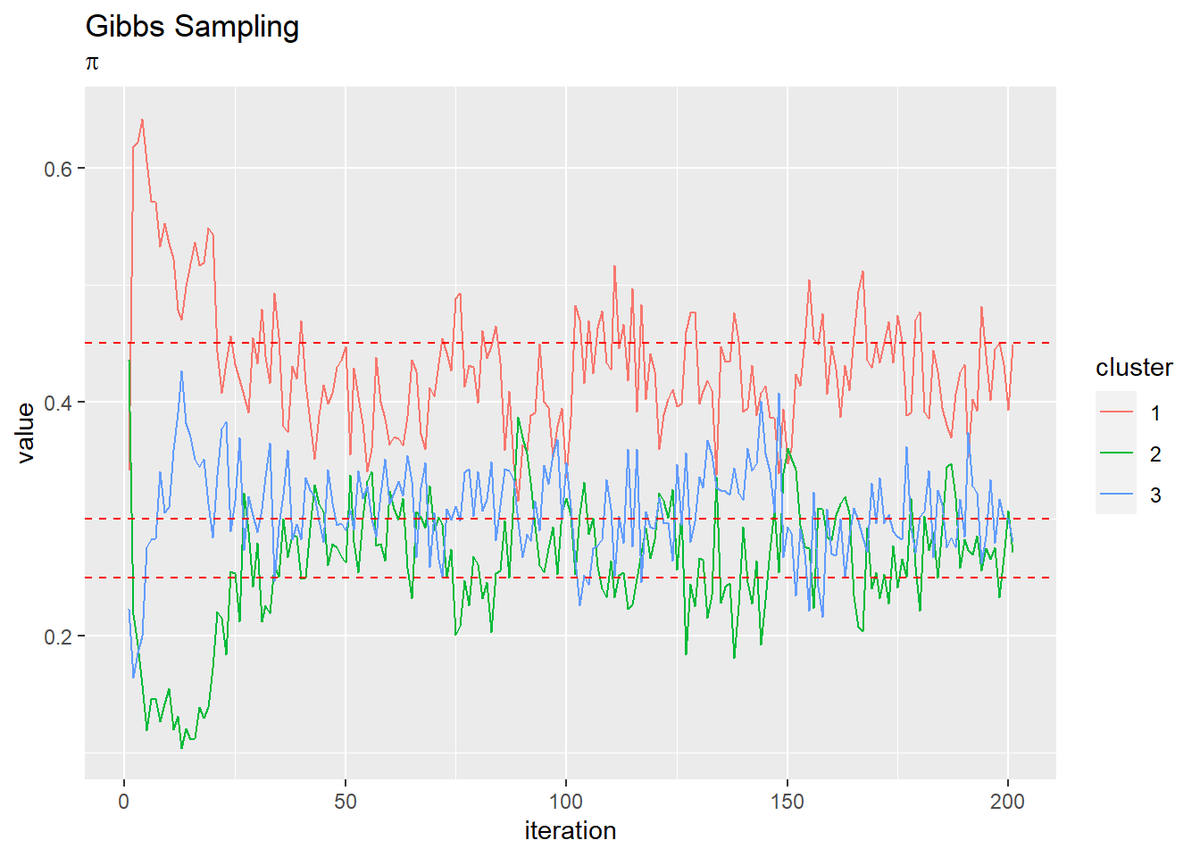
試行回数が増えるに従って真の値に近づいているのを確認できます。
・おまけ:アニメーションによる推移の確認
gganimateパッケージを利用して、各分布の推移のアニメーション(gif画像)を作成するためのコードです。
# 追加パッケージ library(gganimate)
・平均パラメータの事後分布の推移
・コード(クリックで展開)
$\boldsymbol{\mu}$の事後分布の推移を確認します。作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_posterior_df <- tibble() for(i in 1:(MaxIter + 1)) { for(k in 1:K) { # クラスタkのmuの事後分布を計算 tmp_density <- mvnfast::dmvn( X = mu_point_mat, mu = trace_m_ikd[i, k, ], sigma = solve(trace_beta_ik[i, k] * trace_lambda_iddk[i, , , k]) ) # クラスタkの分布をデータフレームに格納 tmp_df <- tibble( mu_1 = mu_point_mat[, 1], mu_2 = mu_point_mat[, 2], density = tmp_density, cluster = as.factor(k), iteration = as.factor(i - 1) ) # 結果を結合 trace_posterior_df <- rbind(trace_posterior_df, tmp_df) } # 動作確認 #print(paste0(i - 1, ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
各試行における計算結果を同じデータフレームに格納していく必要があります。処理に時間がかかる場合は、描画するフレーム数(1:(MaxIter + 1))や、mu_point_matの範囲や点の間隔を調整してください。
分布の推移をgif画像で出力します。
# muの事後分布を作図 trace_posterior_graph <- ggplot() + geom_contour(data = trace_posterior_df, aes(x = mu_1, y = mu_2, z = density, color = cluster)) + # 事後分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の値 gganimate::transition_manual(iteration) + # フレーム labs(title = "Gaussian Distribution:Gibbs Sampling", subtitle = paste0("iter:{current_frame}", ", N=", N), x = expression(mu[1]), y = expression(mu[2])) # gif画像を作成 gganimate::animate(trace_posterior_graph, nframes = MaxIter + 1, fps = 10)
各フレームの順番を示す列をgganimate::transition_manual()に指定します。初期値を含むため、フレーム数はMaxIter + 1です。

・サンプルしたパラメータによる分布とサンプルしたクラスタの推移
・コード(クリックで展開)
パラメータとクラスタのサンプルの推移を確認します。同様に、作図用のデータフレームを作成します。
# 作図用のデータフレームを作成 trace_model_df <- tibble() trace_cluster_df <- tibble() for(i in 1:(MaxIter + 1)) { # i回目の混合分布を計算 res_density <- 0 for(k in 1:K) { # クラスタkの分布の確率密度を計算 tmp_density <- mvnfast::dmvn( X = x_point_mat, mu = trace_mu_ikd[i, k, ], sigma = solve(trace_lambda_iddk[i, , , k]) ) # K個の分布の加重平均を計算 res_density <- res_density + trace_pi_ik[i, k] * tmp_density } # i回目の分布をデータフレームに格納 res_df <- tibble( x_1 = x_point_mat[, 1], x_2 = x_point_mat[, 2], density = res_density, iteration = as.factor(i - 1), label = paste0( "iter:", i - 1, ", N=", N, ", pi=(", paste0(round(trace_pi_ik[i, ], 3), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_model_df <- rbind(trace_model_df, res_df) # 観測データとi回目のクラスタ番号をデータフレームに格納 s_df <- tibble( x_n1 = x_nd[, 1], x_n2 = x_nd[, 2], cluster = as.factor(trace_s_in[i, ]), iteration = as.factor(i - 1), label = paste0( "iter:", i - 1, ", N=", N, ", pi=(", paste0(round(trace_pi_ik[i, ], 3), collapse = ", "), ")" ) %>% as.factor() ) # 結果を結合 trace_cluster_df <- rbind(trace_cluster_df, s_df) # 動作確認 #print(paste0(i - 1, ' (', round((i - 1) / MaxIter * 100, 1), '%)')) }
・サンプルしたパラメータによる分布の推移
# 分布の推移を作図 trace_model_graph <- ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density, color = ..level..), alpha = 0.5, linetype = "dashed") + # 真の分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の平均 geom_contour(data = trace_model_df, aes(x = x_1, y = x_2, z = density, color = ..level..)) + # サンプルによる分布 geom_point(data = trace_cluster_df, aes(x = x_n1, y = x_n2)) + # 観測データ gganimate::transition_manual(iteration) + # フレーム labs(title = "Gaussian Mixture Model:Gibbs Sampling", subtitle = paste0("iter:{current_frame}", ", N=", N, ", K=", K), x = expression(x[1]), y = expression(x[2])) # gif画像を作成 gganimate::animate(trace_model_graph, nframes = MaxIter + 1, fps = 10)
・サンプルしたクラスタの散布図の推移
# クラスタの推移を作図 trace_cluster_graph <- ggplot() + geom_contour(data = model_df, aes(x = x_1, y = x_2, z = density), color = "red", alpha = 0.5, linetype = "dashed") + # 真の分布 geom_point(data = mu_df, aes(x = x_1, y = x_2), color = "red", shape = 4, size = 5) + # 真の平均 geom_contour_filled(data = trace_model_df, aes(x = x_1, y = x_2, z = density), alpha = 0.6) + # サンプルによる分布 geom_point(data = trace_cluster_df, aes(x = x_n1, y = x_n2, color = cluster)) + # サンプルしたクラスタ gganimate::transition_manual(label) + # フレーム labs(title = "Gaussian Mixture Model:Gibbs Sampling", subtitle = "{current_frame}", x = expression(x[1]), y = expression(x[2])) # gif画像を作成 gganimate::animate(trace_cluster_graph, nframes = MaxIter + 1, fps = 10)
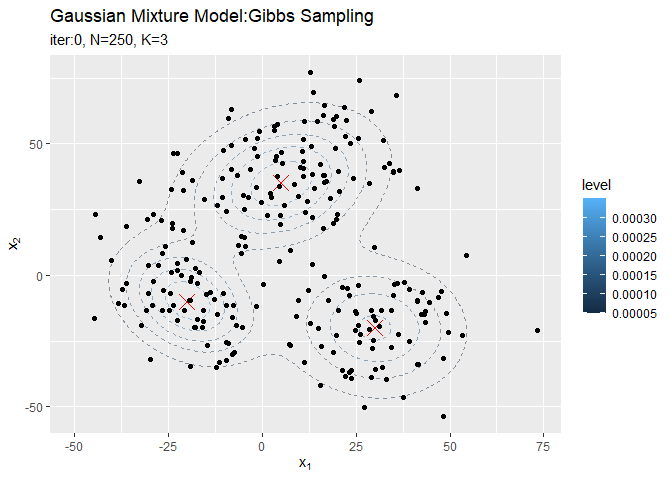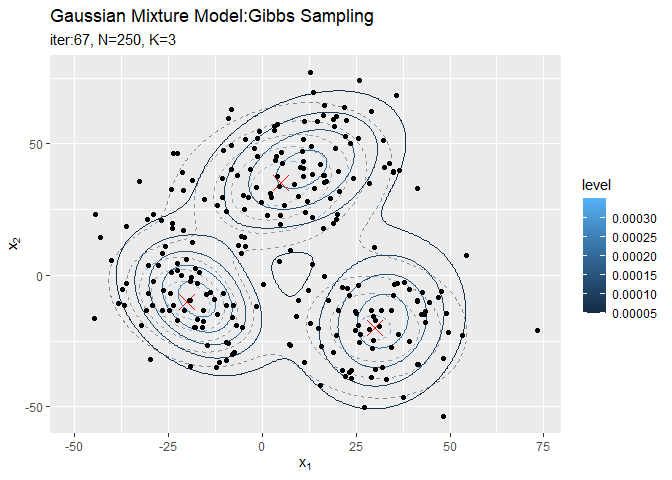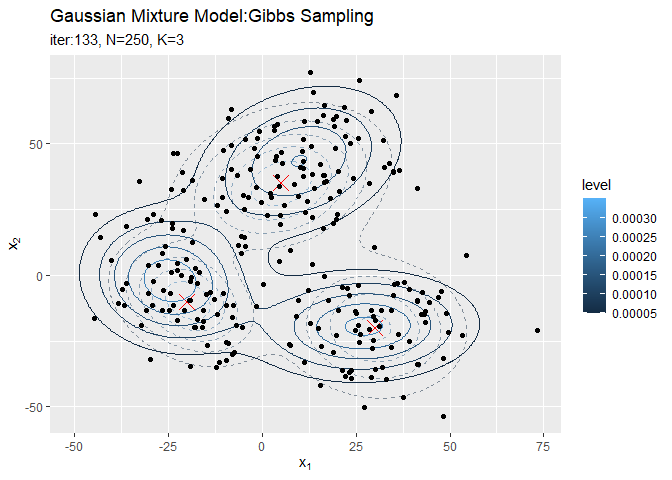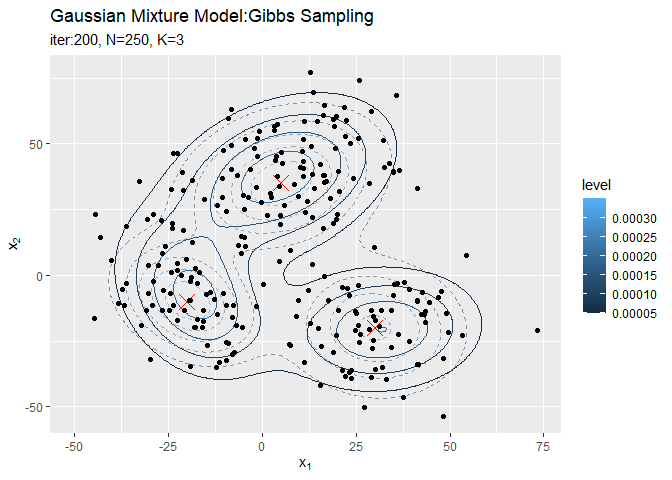
本当は、廃棄期間を設定した上でサンプル平均をとる操作が必要なはずですがここでは扱いません。
参考文献

おわりに
ブログ開設2年目の最終日です。170ちょい目の記事です。これからもよろしくお願いします。
2020年11月30日はモーニング娘。'20の加賀楓さん21歳のお誕生日です!おめでとうございます!
曲後半でセンターしてるショートボブの方です!
加賀温泉郷の観光大使もされているので、そちらも是非行きたいっ!!!
来年こそは、加賀!温泉♨紅葉狩り🍁
【次節の内容】
- 2021/05/15:加筆修正しました。