はじめに
「プログラミング」学習初手『ゼロから作るDeep Learning』民のための実装攻略ノートです。『ゼロつく1』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
関数やクラスとして実装される処理の塊を細かく分解して、1つずつ処理を確認しながらゆっくりと組んでいきます。
この記事は、6.3節「Batch Normalization」の内容になります。出力データを正規化することで広がりのある分布に調整するBatch Normalizationを説明し、Pythonで実装します。また最後に、MNISTデータセットに対する認識精度の変化を確認します。
【前節の内容】
【他の節の内容】
【この節の内容】
6.3 Batch Normalization
前項は重みの初期値の設定を工夫することで、アクティベーション(活性化関数の出力)の広がりを保つ方法を考えました。この項では、アクティベーション自体に手を加えることで分布を調整する方法を考えます。
6.3.1 Batch Normalizationのアルゴリズム
Batch Normとは、ミニバッチごとに正規化(標準化)することです。ここで言う正規化とは、ミニバッチデータの分布が平均が0で標準偏差が1になるようにすることです。ソフトマックス関数によりデータの総和が1になるようにする正規化とは全く別の意味なので注意してください。
まずは数式からアルゴリズムを確認しましょう。
Batch Normalizationは、データ数が$m$のミニバッチデータを$B = \{x_1, x_2, \cdots, x_m\}$とすると、次の4つの式で表せます。
いきなり数式が出てくるとビビりますが、1つ目の式は全てのデータの和をとりデータ数$m$で割っているので、バッチデータの平均のことですね。
2つ目の式の$x_i - \mu_B$は、各データと平均との差で偏差と呼びます。その偏差を2乗して和をとりデータ数で割ったもの(つまり偏差の2乗和の期待値)を分散と呼びます。分散はデータの散らばり具合を表します。
分散の平方根を標準偏差と呼びます。こちらもデータの散らばり具合を表す統計量です。分散とは違い標準偏差は、単位がデータと同じものになります。$\epsilon$は、除算のときに0で割ることにならないように加える微小な値です。
4つ目の式計算により正規化を行います。各データ$x_i$から平均を引き標準偏差で割ることで、平均0、標準偏差1に正規化できます。(ただしこれはガウス分布(正規分布)の場合です。)
正規化後の($i$番目の)データを$\hat{x}_i$と表記することにします。
更に、正規化したミニバッチデータ$\{\hat{x}_1, \hat{x}_2, \cdots, \hat{x}_m\}$に対して次の式の計算を行い、分布を調整します。
$\mathbf{y}_B = \{y_1, y_2, \cdots, y_m\}$は、平均$\beta$、標準偏差$\gamma$となります。$y_i$から$\beta$を引き$\gamma$で割ると$\hat{x}_i$に戻りますね。
$\beta$と$\gamma$もハイパーパラメータと呼び、学習によって最適な値を求めます。
以上がBatch Normレイヤの順伝播になります。
次はプログラム上で実際にやってみて確認しましょう。
正規分布に従う乱数を生成して、統計量を求めます。np.random.normal(平均, 標準偏差, データ数)で、それぞれ指定した値に従うデータをランダムに生成できます。
# 正規分布に従う乱数を生成 x = np.random.normal(10, 5, 10000) # 平均:式(6.7)の1つ目の式 mu = np.mean(x) print(mu) # 偏差:式(6.7)の2つ目の式の括弧の計算 xc = x - mu # 分散:式(6.7)の2つ目の式 var = np.mean(xc**2) print(var) # 標準偏差:式(6.7)の3つ目の式 std = np.sqrt(var + 1e-7) print(std)
10.040724651856767
24.449056183075726
4.944598697879913
データ数を増やすほど誤差が小さくなります。1e-7は、次の割り算時に0で割ることにならないように加えておく微小な値です。
この分布をグラフからも確認しましょう。
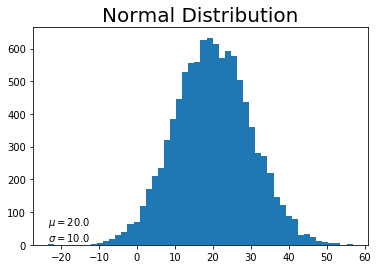
# 作図 plt.hist(x, bins=50) # ヒストグラム plt.title("Normal Distribution", fontsize=20) # タイトル plt.text(np.min(x), 10, "$\\mu=$" + str(np.round(mu, 2)) + "\n$\\sigma=$" + str(np.round(std, 2))) # メモ plt.show()
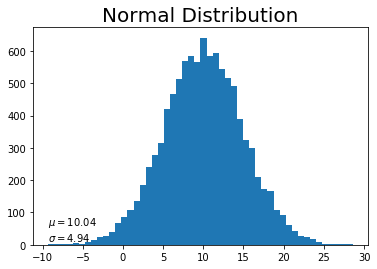
これもデータを増やすと綺麗な釣鐘型の分布になっていきます。
各要素に対して式(6.7)の計算を行い、平均が0で標準偏差が1のガウス分布(標準正規分布)に正規化(標準化)します。
# 正規化:式(6.7) x_n = xc / std # 平均:式(6.7)の1つ目の式 mu_n = np.mean(x_n) print(mu_n) # 分散:式(6.7)の2つ目の式 var_n = np.mean((x_n - mu_n)**2) print(var_n) # 標準偏差:式(6.7)の3つ目の式 std_n = np.sqrt(var_n + 1e-7) print(std_n)
2.962963208119618e-16
0.9999999959098621
1.0000000479549298
これもプロットしましょう。
# 作図 plt.hist(x_n, bins=50) # ヒストグラム plt.title("Standard Normal Distribution", fontsize=20) # タイトル plt.text(np.min(x_n), 10, "$\\mu=$" + str(np.round(mu_n, 2)) + "\n$\\sigma=$" + str(np.round(std_n, 2))) # メモ plt.show()
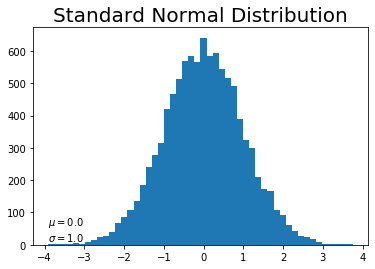
同様の形のまま、平均0、標準偏差1の分布に変換されていることが確認できます。
ちなみに、正規化前のグラフと同じx軸の範囲をみると次のようになります。
# 作図 plt.hist(x_n, bins=25) # ヒストグラム plt.xlim(np.min(x), np.max(x)) # x軸の範囲 plt.title("Standard Normal Distribution", fontsize=20) # タイトル plt.text(np.min(x), 10, "$\\mu=$" + str(np.round(mu_n, 2)) + "\n$\\sigma=$" + str(np.round(std_n, 2))) # メモ plt.show()
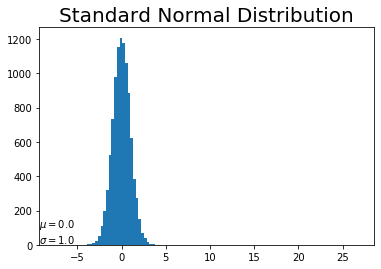
元の分布よりも標準偏差が小さいため、分布の形が細くなっています。データ数は変わらないためy軸方向の変化はありません。
ここに更に任意の値を掛けて引くことで、任意の標準偏差と平均に調整することができます。
# 調整用の平均 beta = 20 # 調整用の標準偏差 gamma = 10 # 値を調整:式(6.8) y = gamma * x_n + 20 # 平均:式(6.7)の1つ目の式 mu_y = np.mean(y) print(np.mean(y)) # 標準偏差:式(6.7)の3つ目の式 std_y = np.std(y) print(np.std(y))
20.0
9.999999979549312
グラフで確認!
# 作図 plt.hist(y, bins=50) # ヒストグラム plt.title("Normal Distribution", fontsize=20) # タイトル plt.text(np.min(y), 10, "$\\mu=$" + str(np.round(mu_y, 2)) + "\n$\\sigma=$" + str(np.round(std_y, 2))) # メモ plt.show()
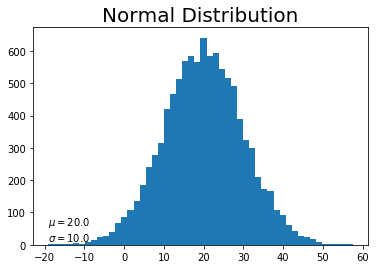
アクティベーション(活性化後のデータ)の分布が偏ってしまっても(6.2節)、このようにデータ間の関係を維持したまま調整することができます。ちなみに、偏差値というのもこのようにテストの点の分布を平均50、標準偏差10となるように調整した値です。
ハイパーパラメータについては、初期値を$\gamma = 1,\ \beta = 0$として学習することによって、入力データに適した値に調整します。
・逆伝播
逆伝播については「Batch Normレイヤの逆伝播【ゼロつく1のノート(数学)】 - からっぽのしょこ」の方でやります。次で実装する逆伝播メソッドの定義についても、数式と見比べる必要があるためこの記事で確認します。
・実装
アルゴリズムの確認ができたので、Batch Normalizationを実装します。
インスタンス作成時の引数として、アクティベーションの調整用の標準偏差gamma、平均betaを設定します。またこの2つのハイパーパラメータの値は試行の度に更新されます。そのとき、過去の値を減衰率momentumで割り引きつつrunning_meanとrunning_var(分散)にそれぞれ加えていきます。この値は評価時に使用する平均と標準偏差(分散の平方根)になります。
(本に書いてないのでよく分かってないけど、)式(6.7)の計算は学習時にしか行わないようです。テスト時には過去の平均の情報running_meanと標準偏差の情報running_var(の平方根)を用いて正規化します。そのためtrain_flgの値によって、学習TrueなのかテストFalseなのかを条件分岐します。
# Batch Normalizationの実装 class BatchNormalization: # インスタンス変数の定義 def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None): # 再変換用のパラメータ self.gamma = gamma # 標準偏差 self.beta = beta # 平均 self.momentum = momentum # 減衰率 # テスト時に使用する統計量 self.running_mean = running_mean # 平均 self.running_var = running_var # 分散 # 逆伝播時に使用する統計量 self.batch_size = None # データ数 self.xc = None # 偏差 self.std = None # 標準偏差 self.dgamma = None # (再変換用の)標準偏差の微分 self.dbeta = None # (再変換用の)平均の微分 # 順伝播メソッドの定義 def forward(self, x, train_flg=True): # 初期値を与える if self.running_mean is None: N, D = x.shape self.running_mean = np.zeros(D) self.running_var = np.zeros(D) if train_flg: # 学習時 # 正規化の計算 mu = x.mean(axis=0) # 平均 xc = x - mu # 偏差 var = np.mean(xc ** 2, axis=0) # 分散 std = np.sqrt(var + 10e-7) # 標準偏差 xn = xc / std # 標準化:式(6.7) # 計算結果を(逆伝播用に)インスタンス変数として保存 self.batch_size = x.shape[0] self.xc = xc # 偏差 self.xn = xn # 標準化データ self.std = std # 標準偏差 self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * mu # 過去の平均の情報 self.running_var = self.momentum * self.running_var + (1 - self.momentum) * var # 過去の分散の情報 else: # テスト時 xc = x - self.running_mean xn = xc / np.sqrt(self.running_var + 10e-7) # 標準化:式(6.7') # 再変換 out = self.gamma * xn + self.beta # 式(6.8) return out # 逆伝播メソッドの定義 def backward(self, dout): # 微分の計算 dbeta = dout.sum(axis=0) # 調整後の平均 dgamma = np.sum(self.xn * dout, axis=0) # 調整後の標準偏差 dxn = self.gamma * dout # 正規化後のデータ dxc = dxn / self.std # 偏差 dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0) # 標準偏差 dvar = 0.5 * dstd / self.std # 分散 dxc += (2.0 / self.batch_size) * self.xc * dvar # 偏差 dmu = np.sum(dxc, axis=0) # 平均 dx = dxc - dmu / self.batch_size # 入力データ # インスタンス変数に保存 self.dgamma = dgamma self.dbeta = dbeta return dx
(もう少し説明が欲しいが、このレベルはまだ理解しなくてよいということなのだと思う。)
では試してみます。np.random.normal()の第3引数に、括弧で閉じることで行数と列数を指定できます。
# 正規分布に従う乱数を生成 x = np.random.normal(10, 5, (100, 100)) # インスタンスを作成 bn = BatchNormalization(gamma=10, beta=20) # 正規化と変換 y = bn.forward(x) mean_y = np.mean(y) std_y = np.std(y) # 作図 plt.hist(y.flatten(), bins=50) # ヒストグラム plt.title("Normal Distribution", fontsize=20) # タイトル plt.text(np.min(y), 10, "$\\mu=$" + str(np.round(mean_y, 2)) + "\n$\\sigma=$" + str(np.round(std_y, 2))) # メモ plt.show()
Batch Normalizationによる効果について、「6.2:重みの初期値【ゼロつく1のノート(実装)】 - からっぽのしょこ」と同様の方法で各層のアクティベーションの分布を確認してみましょう。Affineレイヤと活性化レイヤの間にBatch Normレイヤの処理を加えます。
# インスタンスを作成 bn = BatchNormalization(gamma=1, beta=0) # 活性化関数を選択(キーを指定) activation_key = 'sigmoid' #activation_key = 'relu' #activation_key = 'tanh' # 重みの初期値の標準偏差を選択 #weight_init_std = 1.0 weight_init_std = 0.01 #weight_init_std = 'xavier' #weight_init_std = 'he' # 入力データを複製 x = input_data # 活性化後のデータの受け皿を初期化 activations = {} # 1層ずつ処理 for i in range(layer_size): # 前の層(i-1回目)の出力データを現在の層の入力データとして代入 if i != 0: # 初回は飛ばす x = activations[i-1] # 指定した標準偏差に対応する値を取得 scale = weight_init_std if weight_init_std == 'xavier': # xavierのとき scale = np.sqrt(1.0 / node_num) # Xavierの初期値 elif weight_init_std == 'he': # heのとき scale = np.sqrt(2.0 / node_num) # Heの初期値 # 指定した標準偏差に従い重みをランダムに生成 w = scale * np.random.randn(node_num, node_num) # Affineレイヤの計算 a = np.dot(x, w) # BatchNormalizationレイヤの処理 a_bn = bn.forward(a) # 活性化 z = activation_layer[activation_key](a_bn) # 活性化関数の出力データを記録 activations[i] = z # 作図 for i, z in activations.items(): plt.subplot(1, len(activations), i + 1) # グラフの表示位置 plt.hist(z.flatten(), 30, range=(0, 1)) # ヒストグラム plt.xticks([0.0, 0.5, 1.0]) # x軸目盛 if i != 0: # 一番左以外 plt.yticks([], []) # y軸目盛(を非表示) plt.title(str(i + 1) + "-layer") # グラフごとのタイトル plt.suptitle("function:" + activation_key + ", W:std=" + str(weight_init_std)) # グラフ全体のタイトル plt.show()
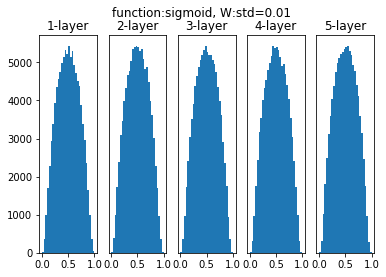
どの層についても標準正規分布の形状を保っています。
6.3.2 Batch Normalizationの評価
それではBatch Normalization(アクティベーションの正規化)による学習への影響を、MNISTデータセットを用いて確認しましょう。
この項では5層のニューラルネットワークを用います。そのためのBatch Normalization対応版多層ニューラルネットワークのクラスは、6章の最後に実装します。そのためここでは、マスターデータから(将来の自分が実装した)クラスを読み込みましょう。このクラスを用いた基本的な処理の流れは6.1.8項や6.2.4項と同じです。そちらも参考にしてください。
またMNISTデータセットも読み込みます。マスターデータからの読み込みに関する詳しい解説は「3.6.1:MNISTデータセットの読み込み【ゼロつく1のノート(Python)】 - からっぽのしょこ」を確認してください。
# データ読み込み用ライブラリを読み込む import sys, os # ファイルパスを指定 sys.path.append('C:\\Users\\「ユーザー名」\\Documents\\・・・\\deep-learning-from-scratch-master') # MNISTデータセット読み込み関数を読み込む from dataset.mnist import load_mnist # Batch Normalization対応版多層ニューラルネットワーククラスを読み込む from common.multi_layer_net_extend import MultiLayerNetExtend # 各種レイヤのクラス from common.layers import * # 画像データを読み込む (x_train, t_train), (x_test, t_test) = load_mnist(normalize = True, one_hot_label=True) print(x_train.shape) print(t_train.shape)
(60000, 784)
(60000, 10)
この例では、1000データだけを使うことにします。またバッチサイズを100とします。
# 学習データを削減 x_train = x_train[:1000] t_train = t_train[:1000] # 訓練データ数 train_size = x_train.shape[0] # バッチサイズを指定 batch_size = 100
重みの初期値の標準偏差を指定します。重みの初期値による学習への影響については前項を確認してください。
多層ニューラルネットワークMultiLayerNetExtendのインスタンスを2つ作成します。use_batchnorm引数にTrueかFalseを指定することで、正規化を行うかどうかを指定できます。正規化を行うように設定したインスタンスをbn_network、行わない設定の方をnetworkとします。
この例では6層のニューラルネットワークとするため、中間層のニューロン数の引数hidden_size_listに5つの値をリスト型変数で指定します(詳しくは実装時に説明します)。任意の値を指定できますが、この例では全て100とします。MNISTデータセットを用いる場合は、入力サイズinput_sizeがピクセル数の784、出力サイズoutput_sizeが数字の数10になります。(ちなみに、入出力層を含めた7つの層の間の数が6になります。)
利用する活性化関数を指定する引数activationには、'relu'か'sigmoid'を指定します。この例ではreluを指定します。
重みの初期値を設定するための引数weight_init_stdには、値あるいは'he'か'xavier'を指定します。この例では値を指定します。
この例では、最適化手法を確率的勾配降下法(SGD)とします。6.1節で実装した他の手法も使えます。
# 重みの初期値の標準偏差を指定 weight_init_std = 0.05 # Batch Normレイヤを含む5層のニューラルネットワークのインスタンスを作成 bn_network = MultiLayerNetExtend( input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10, activation='relu', # 活性化関数 weight_init_std=weight_init_std, # 重みの初期値の標準偏差 use_batchnorm=True # Batch Normalizationの設定 ) # Batch Normレイヤを含まない5層のニューラルネットワークのインスタンスを作成 network = MultiLayerNetExtend( input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10, activation='relu', # 活性化関数 weight_init_std=weight_init_std, # 重みの初期値の標準偏差 use_batchnorm=False # Batch Normalizationの設定 ) # 最適化手法を指定 optimizer = SGD(lr=0.01)
これまでは、複数のニューラルネットワークのインスタンスを1つのディクショナリ変数に格納して、for文によりキーを切り替えることで処理しました。この例では、2つのインスタンスを直接for文で切り替えます。
データセットの何回分試行するかを指定して、学習を行います。
また交差エントロピー誤差を記録するための空のリスト型変数を作成します。正規化を行った場合の値を記録する変数をbn_train_acc_list、行わなかった場合をtrain_acc_listとし、.append()で追加していきます。
# 試行するエポック数を指定 max_epochs = 20 # 全データ数に対するバッチデータ数の割合(エポック数判定用) iter_per_epoch = max(train_size / batch_size, 1) # 試行エポック数を初期化 epoch_cnt = 0 # 認識精度の受け皿を初期化 bn_train_acc_list = [] train_acc_list = [] # 手書き文字認識 for i in range(1000000000): # ランダムにバッチデータを抽出 batch_mask = np.random.choice(train_size, batch_size, replace=False) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # Batch Normレイヤありver.なしver.を切り替え for _network in (bn_network, network): # 勾配を計算 grads = _network.gradient(x_batch, t_batch) # パラメータを更新 optimizer.update(_network.params, grads) # エポックごとに認識精度を測定 if i % iter_per_epoch == 0: # 認識精度を測定 bn_train_acc = bn_network.accuracy(x_train, t_train) train_acc = network.accuracy(x_train, t_train) # 値を記録 bn_train_acc_list.append(bn_train_acc) train_acc_list.append(train_acc) # (動作確認も兼ねて)認識精度を表示 print( "===========" + "epoch:" + str(epoch_cnt) + "===========" + "\nBatch Norm" + ":" + str(np.round(bn_train_acc, 5)) + "\nNormal" + " " * (len("Batch Norm") - len("Normal")) + ":" + # (間隔調整) str(np.round(train_acc, 5)) ) # エポック数をカウント epoch_cnt += 1 # 指定エポック数を超えたら終了 if epoch_cnt >= max_epochs: break
===========epoch:0===========
Batch Norm:0.116
Normal :0.078
===========epoch:1===========
Batch Norm:0.177
Normal :0.117
===========epoch:2===========
(省略)
===========epoch:18===========
Batch Norm:0.925
Normal :0.117
===========epoch:19===========
Batch Norm:0.934
Normal :0.117
結果をグラフ化します。
# 作図用のx軸の値 epochs = np.arange(max_epochs) # 作図 plt.plot(epochs, bn_train_acc_list, label="Batch Normalization") # 正規化あり plt.plot(epochs, train_acc_list, label="Nromal", linestyle="--") # 正規化なし plt.ylim(0, 1) # y軸の範囲 plt.xlabel("epochs") # x軸ラベル plt.ylabel("accuracy") # y軸ラベル plt.title("Training Accuracy", fontsize=20) # タイトル plt.text(-0.5, 0.75, "W:std=" + str(np.round(weight_init_std, 3))) # メモ plt.legend() # 凡例 plt.show()
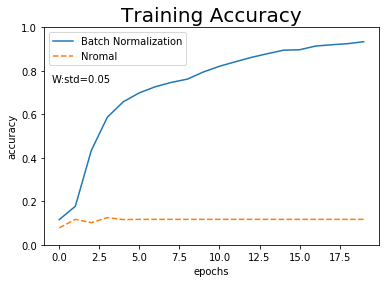
正規化を行うことで学習ができていることを確認できます。
重みの初期値の標準偏差を変更してみましょう!
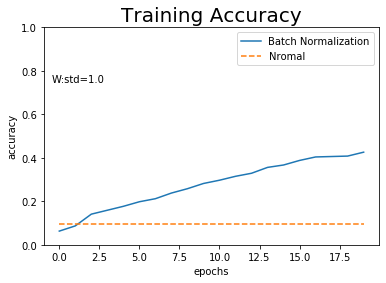
標準偏差の値が大きいと正規化しても学習できないようです。
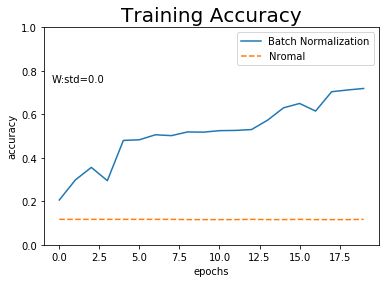
値が小さすぎても学習が進まないようです。
以上で重みの初期値の設定について確認できました!次は正則化によって過学習の抑制を考えます。
参考文献

おわりに
6章は説明が省略されていてかなーり困ってます。。このレベルは追々でいいよということだと思いますが、しかし今気になる、、
【次節の内容】
2020年8月16日は、ハロー!プロジェクトの末っ子グループ「BEYOOOOONDS」の小林萌花さん二十歳のお誕生日!!
おめでとうございます!ほのピアノをいつまでも聴いていたい。
こちらも!