はじめに
機械学習プロフェッショナルシリーズの『トピックモデル』の勉強時に自分の理解の助けになったことや勉強会資料のまとめです。トピックモデルの各種アルゴリズムを「数式」と「プログラム」から理解することを目指します。
この記事は、2.5節「ベイズ推定」と2.6節「ベイズ予測分布」の内容です。ユニグラムモデルにおけるベイズ推定とベイズ予測分布を説明して、ベイズ推定値とその事後分布を用いた予測分布を導出します。そして最後にR言語で実装します。
この記事で用いる記号類やユニグラムモデルの定義については、2.1-2:ユニグラムモデル【『トピックモデル』の勉強ノート】 - からっぽのしょこをご確認ください。
【前節の内容】
【他の節一覧】
【この節の内容】
2.5 ベイズ推定
最尤推定とMAP推定では、それぞれの基準で最も良いパラメータを1つ求めた。これを点推定と呼ぶ。ベイズ推定では、ハイパーパラメータ(事前分布のパラメータ)を(点)推定することでパラメータの分布を求める。点推定に対して、これを分布推定と呼ぶ。パラメータを分布推定することで確からしさを表現でき、過学習の問題を緩和できる。
ディリクレ事前分布を$p(\boldsymbol{\phi} | \beta)$、尤度を$p(\mathbf{W} | \boldsymbol{\phi})$として、文書集合(観測データ)$\mathbf{W}$を得た後のパラメータ$\boldsymbol{\phi}$の事後分布$p(\boldsymbol{\phi} | \mathbf{W}, \beta)$をベイズの定理(1.4)を用いて求める。
【途中式の途中式】
- ベイズの定理(1.4)より、式を立てる。分母は分子を$\boldsymbol{\phi}$について周辺化したもので、正規化項である。
- それぞれ具体的な値に置き換える。
- 尤度は、ユニグラムモデルの定義式(2.1)より置き換える。
- 事前分布は、$p(\boldsymbol{\phi} | \beta, \cdots, \beta) = \mathrm{Direchlet}(\boldsymbol{\phi} | \beta)$で置き換える。
- ディリクレ分布の正規化項は$\boldsymbol{\phi}$と無関係なので、$\int$の外に出す。また、$\phi_v$の項をまとめる。
- 約分して式を整理する。
- ディリクレ分布の正規化項の導出過程(1.13)より、$\frac{1}{\int \prod_{v=1}^V \phi_v^{N_v + \beta - 1} d\boldsymbol{\phi}} = \frac{\Gamma(\sum_{v=1}^V N_v + \beta)}{\prod_{v=1}^V \Gamma(N_v + \beta)}$である。このとき、各語彙の出現回数の総和は総単語数$\sum_{v=1}^V N_v = N$であり、この例の$\beta$は定数のため$\sum_{v=1}^V \beta = \beta V$になる。
この推定結果は、単語分布$\boldsymbol{\phi}$がパラメータ$N_1 + \beta, N_2 + \beta, \cdots, N_V + \beta$を持つディリクレ分布に従うことを意味している。また、事後分布も事前分布と同様にディリクレ分布になることが確認できる。
・Rでやってみる
簡単な例として、文書が1つの場合について考えます。文書は1つですが、次章以降への繋がりを考えてこの文書を文書$d$と呼ぶことにします。またそれぞれの過程をイメージしやすいように、サイコロに例えながら進めます。ただしこの例では、2次元の図に落とし込めるように3変数(サイコロの目が1から3)とします。
まずはパラメータを指定し、そのパラメータに従ってランダムに単語を生成します。生成された単語データ(文書)を用いて、ベイズ推定により事前分布のパラメータの推定値を求めます(パラメータの分布を推定します)。
# 利用パッケージ library(tidyverse)
利用するパッケージを読み込みます。
文書$d$(文書全体)の単語数と語彙数とハイパーパラメータを指定します。
# 単語数(サイコロを振る回数)を指定 N_d <- 32 # 語彙数(サイコロの目の数):(V=3) V = 3 # 単語分布のパラメータを指定 beta <- 2
単語数はサイコロを振る回数と言えます。
語彙数はサイコロの目の数と言えます。この例では3とします。
事前分布のパラメータを指定します。
真の単語分布を指定します。
# 真の単語分布(カテゴリ分布のパラメータ)を指定 phi_turth <- rep(1, V) / V phi_turth
## [1] 0.3333333 0.3333333 0.3333333
sum(phi_turth)
## [1] 1
この例では(正六面体の)サイコロのように一様に設定します。一様でなくとも問題なく推定を行えますが、総和が1となるように指定する必要があります。
この値は本来知り得ない値です。ここで指定した値をベイズ推定により推定することが目的になります。
指定したパラメータ類に従って、単語をランダムに生成し文書を作成します。
# 文書を生成(サイコロを振る) w_dn <- sample(x = 1:V, size = N_d, replace = TRUE, prob = phi_turth) w_dn
## [1] 2 2 3 1 1 3 3 2 3 2 3 3 2 2 2 3 3 3 1 1 2 3 1 1 1 3 2 2 1 1 1 1
サイコロの目に応じた語彙が設定してあるイメージです。
語彙ごとの出現回数をカウントします。
# 各語彙の出現回数を集計 doc_df1 <- tibble(v = w_dn) %>% group_by(v) %>% # 出目でグループ化 summarise(N_v = n()) # 出目ごとにカウント # 出ない目があったとき用の対策 doc_df2 <- tibble(v = 1:V) %>% # 1からVまでの受け皿(行)を作成 left_join(doc_df1, by = "v") %>% # 結合 mutate(N_v = replace_na(N_v, 0)) # NAを0に置換
1度も出ない語彙(目)があると、値が0ではなくデータフレームに含まれません。なのでその対策をします。
推定を行う前に作図用の$\boldsymbol{\phi}$の値を用意します。
# 値をランダムに生成 phi_mat <- seq(0.001, 1, 0.001) %>% sample(size = 120000, replace = TRUE) %>% matrix(ncol = 3) # 正規化 phi_mat <- phi_mat / rowSums(phi_mat)
総和で割ることで正規化できます。
ベイズ推定を行います。
# ベイズ推定 bayes_df <- tibble( x = phi_mat[, 2] + (phi_mat[, 3] / 2), # 三角座標に変換 y = sqrt(3) * (phi_mat[, 3] / 2), # 三角座標に変換 nmlz_term = lgamma(sum(doc_df2[["N_v"]]) + beta * V) - sum(lgamma(doc_df2[["N_v"]] + beta)), # density = exp(nmlz_term + colSums((doc_df2[["N_v"]] + beta - 1) * log(t(phi_mat)))) # 正規化項 ) head(bayes_df)
## # A tibble: 6 x 4 ## x y nmlz_term density ## <dbl> <dbl> <dbl> <dbl> ## 1 0.255 0.185 41.9 0.0472 ## 2 0.268 0.229 41.9 0.112 ## 3 0.312 0.360 41.9 0.0950 ## 4 0.326 0.257 41.9 1.72 ## 5 0.645 0.305 41.9 1.42 ## 6 0.555 0.206 41.9 7.71
事後分布のパラメータ$N_1 + \beta, \cdots, N_V + \beta$を持つディリクレ分布の計算を行い、$\phi_1,\ \phi_2,\ \phi_3$の組み合わせごとの確率密度を計算します。
また$\phi_1,\ \phi_2,\ \phi_3$の3変数を2次元のグラフに落とし込むため、三角座標に変換します。
推定結果を可視化します。
# 作図 ggplot(bayes_df, aes(x = x, y = y, color = density)) + # データ geom_point() + # 散布図 scale_color_gradientn(colors = c("blue", "green", "yellow", "red")) + # 色 scale_x_continuous(breaks = c(0, 1), labels = c("(1, 0, 0)", "(0, 1, 0)")) + # x軸目盛 scale_y_continuous(breaks = c(0, 0.87), labels = c("(1, 0, 0)", "(0, 0, 1)")) + # y軸目盛 coord_fixed(ratio = 1) + # 縦横の比率 labs(title = "Unigram Model:Bayesian Estimation", subtitle = paste0("N=", N_d), x = expression(paste(phi[1], ", ", phi[2], sep = "")), y = expression(paste(phi[1], ", ", phi[3], sep = ""))) # ラベル
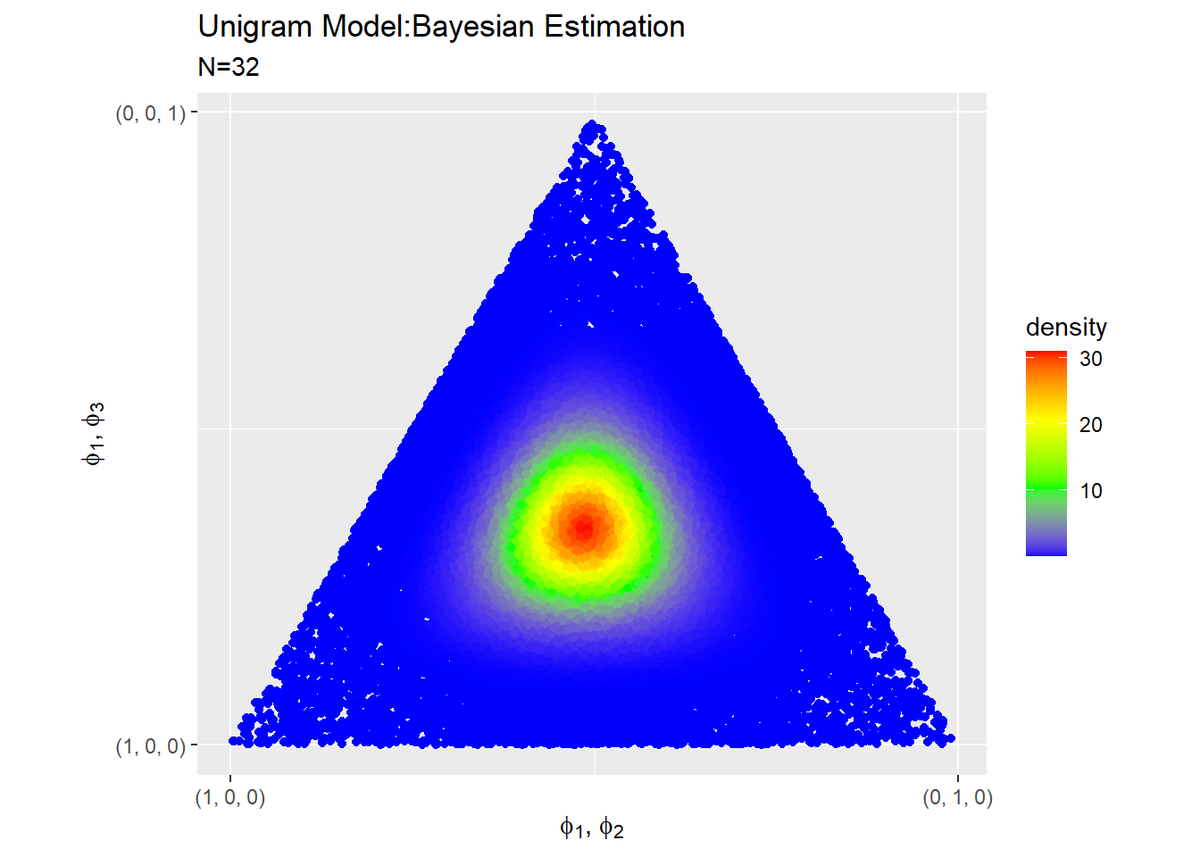
色が青から赤に近づくほど確率密度が(相対的に)高くなることを表しています。
この例では$\boldsymbol{\phi}$を一様に設定したので、真の値はこのグラフの中央になります。試行回数が32回だと、ある程度推定できていることが確認できます。
単語数(試行回数)が少ない場合も見てみましょう。
・$\beta = 2,\ N_d = 1$の場合
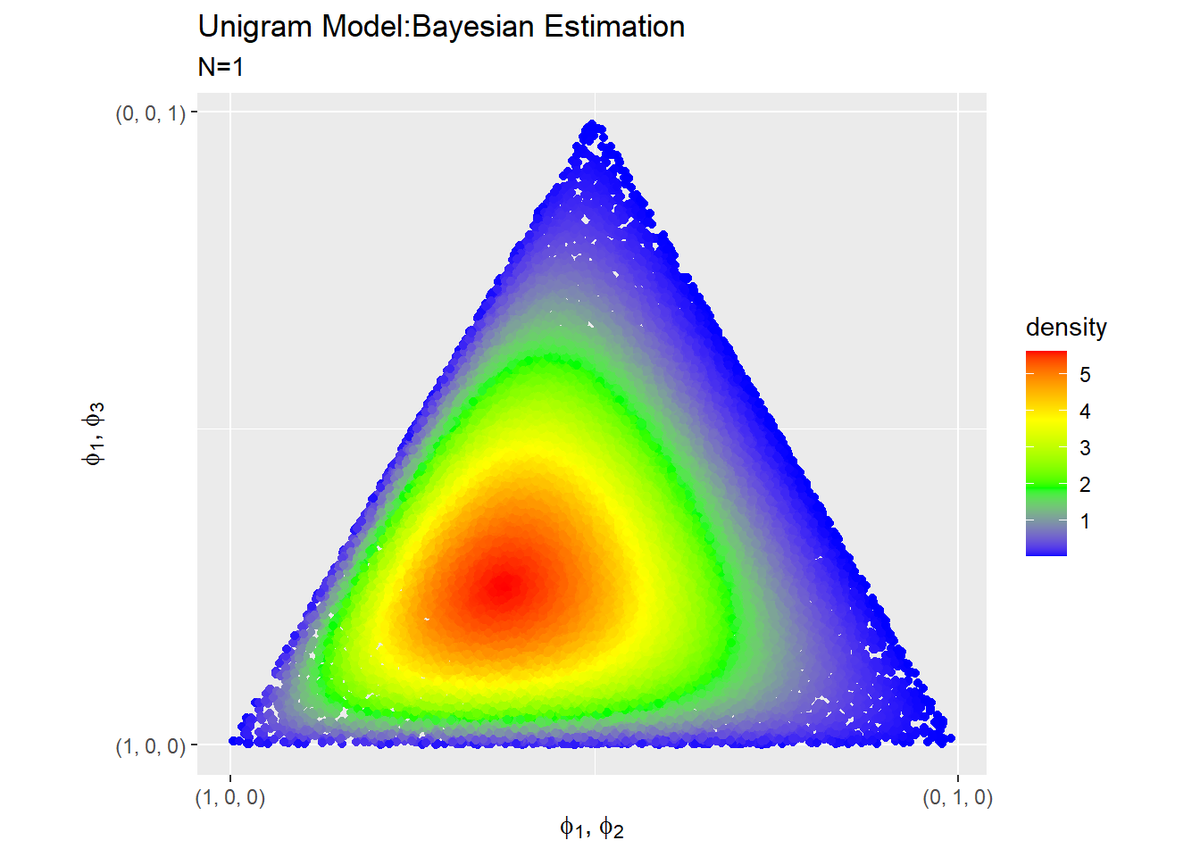
確率密度が一番大きくなる$\boldsymbol{\phi}$の値が、真の値(中央)から離れてしまいました。また試行回数が減る(増える)とばらつきが大きく(小さくなる)ことが確認できますね。
ベイズ推定によってパラメータ$\boldsymbol{\phi}$の分布(事後分布)を推定した。次節では、ここから任意の単語$w^*$の分布を予測する。
2.6 ベイズ予測分布
ベイズ推定では、文書(観測)データを用いて、パラメータ$\boldsymbol{\phi}$を分布推定した。ベイズ予測では、このパラメータの事後分布$p(\boldsymbol{\phi} | \mathbf{W})$を用いて、単語(データ)の分布を求める。これはある単語がどの語彙になるのかの確率を推定することから、単語を予測しているとも言える。
まずは表記を確認する。
例えば文書5の3番目の単語は$w_{53}$と表記するのであった。この単語$w_{53}$が、文書全体において2番目の語彙であることを明示したいとき、$w_{53} = 2$と書く。
同様に、ある未知の単語(ある文書においてこれから生成される単語)を$w^*$で表すことにする。その未知の単語がある語彙$v$であることを$w^* = v$と表記する。また$w^*$が語彙$v$となる確率は
と書ける。
この未知の単語として語彙$v$が生成される確率が単語分布$\boldsymbol{\phi}$に従うとき、次のように書くのであった。
ここに$\boldsymbol{\phi}$の事後分布(文書データ$\mathbf{W}$を用いて更新した$\boldsymbol{\phi}$の分布)$p(\boldsymbol{\phi} | \mathbf{W}, \beta)$を掛ける。
これは乗法定理(1.3)より、ハイパーパラメータ$\beta$と文書集合$\mathbf{W}$を条件とした、単語$w^* = v$と単語分布$\boldsymbol{\phi}$の同時確率となる。
これは(尤度(生成モデル)と事前分布の積がパラメータ$\boldsymbol{\phi}$の事後分布(文書データ$\mathbf{W}$を条件とした分布)となるように)、事前知識$\beta$と観測データ$\mathbf{W}$によって更新されたデータ(単語)の生成確率と言える。
事後分布は$\boldsymbol{\phi}$の分布なので、$\boldsymbol{\phi}$は様々な値をとることを意味する。そこで$\boldsymbol{\phi}$について周辺化(積分)する。
$\boldsymbol{\phi}$がとり得る全ての可能性を考慮した未知の単語$w^* = v$の分布となる。これは未知のデータが何であるのかの可能性を示すことから予測分布と呼ぶ。
この式を同時確率ではなく、生成モデルと事後分布の積に戻す。
単語分布$\boldsymbol{\phi}$に従い語彙$v$となる確率は$\phi_v$なので、この式は事後分布による$\phi_v$の平均と言える。
以上で予測分布の定義式を確認した。続いてこの式に具体的な値を代入して解く。ここで、$v$はある特定の語彙を示すもので、語彙インデックスは$v'$を使って表す。
【途中式の途中式】
- $\boldsymbol{\phi}$に従う単語の分布とベイズ推定の事後分布の積の$\boldsymbol{\phi}$を周辺化することで、予測分布となる。
- それぞれ具体的な値に置き換える。
- $p(w^* = v | \boldsymbol{\phi})$は、単語$w^*$が$v$となる確率のことなので$\phi_v$である。
- $p(\boldsymbol{\phi} | \mathbf{W}, \beta)$は、2.5項で求めた事後分布(ディリクレ分布)である。
- $\prod_{v'=1}^V$から$\phi_v$に関する項を取り出す。
- 正規化項の導出過程(1.13)より、各項を変形する。ただし$v$の項は$\phi_v^{N_v +\beta}$なので、$N_v + 1 + \beta$になる。
- ガンマ関数の性質$\Gamma(x+1) = x\Gamma(x)$の変形を行う。また、分母の$\sum_{v'\neq v}$を展開して計算する。
- ガンマ関数の性質より変形する。また、分子の$\Gamma(N_v + \beta)$を$\prod_{v'\neq v}$に戻す。
- 約分して式を整理する。
単語$w^*$の分布(どの語彙になるのかの確率をまとめたもの)が観測データに関する値$N_v$と事前分布のパラメータ$\beta$から決まることが確認できる。
・Rでやってみる
2.5節と同様に、パラメータ類を指定して進めます。ただしこちらは周辺化することで次元を圧縮するので、一般的なサイコロのように$V = 6$とします。
# 利用パッケージ library(tidyverse) # 単語数(サイコロを振る回数)を指定 N_d <- 1 # 語彙数(サイコロの目の数) V = 6 # 真の単語分布(カテゴリ分布のパラメータ)を指定 phi_turth <- rep(1, V) / V # 単語分布のパラメータを指定 beta <- 2 # 文書を生成(サイコロを振る) w_dn <- sample(x = 1:V, size = N_d, replace = TRUE, prob = phi_turth) # 各語彙の出現回数を集計 doc_df1 <- tibble(v = w_dn) %>% group_by(v) %>% # 出目でグループ化 summarise(N_v = n()) # 出目ごとにカウント # 出ない目があったとき用の対策 doc_df2 <- tibble(v = 1:V) %>% # 1からVまでの受け皿(行)を作成 left_join(doc_df1, by = "v") %>% # 結合 mutate(N_v = replace_na(N_v, 0)) # NAを0に置換
ベイズ予測分布を推定する。
# ベイズ予測分布を計算 predict_df <- doc_df2 %>% mutate(prob = (N_v + beta) / sum(N_v + beta)) # 確率 head(predict_df)
## # A tibble: 6 x 3 ## v N_v prob ## <int> <dbl> <dbl> ## 1 1 0 0.154 ## 2 2 0 0.154 ## 3 3 0 0.154 ## 4 4 1 0.231 ## 5 5 0 0.154 ## 6 6 0 0.154
$p(w^* = v | \mathbf{W}, \beta) = \frac{N_v + \beta}{N + \beta V}$の計算を行い、観測データを考慮した各語彙となる確率($\boldsymbol{\phi}$の平均値)を求めます。
結果を可視化します。
# 作図 ggplot(predict_df, aes(x = v, y = prob)) + # データ geom_bar(stat = "identity", fill = "#00A968") + # 棒グラフ scale_x_continuous(breaks = 1:V, labels = 1:V) + # 軸目盛 labs(title = "Unigram Model:Bayesian Predictive Distribution", subtitle = paste0("N=", N_d)) # ラベル
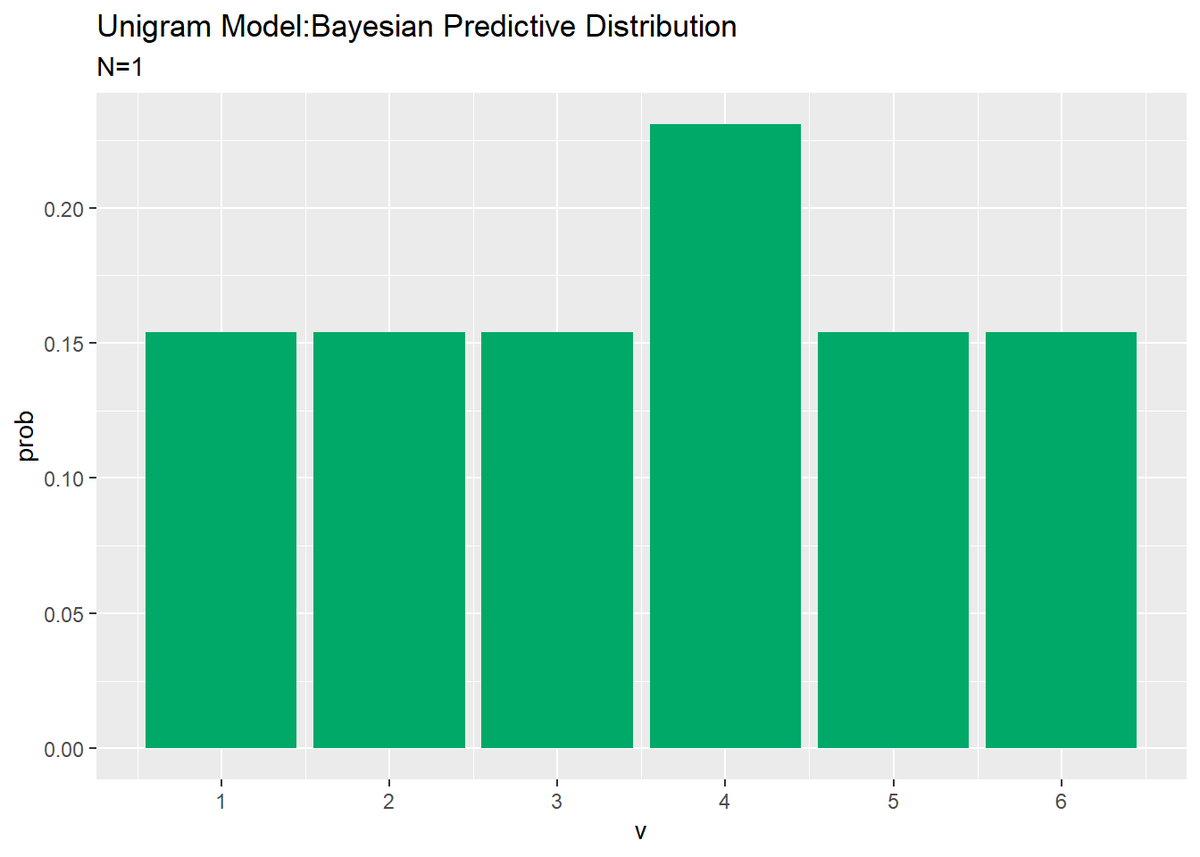
これは試行回数が1回の場合のグラフなので、観測があった語彙がぴょこんと頭を出している形になります。
試行回数を増やしてみましょう。
・試行回数:64
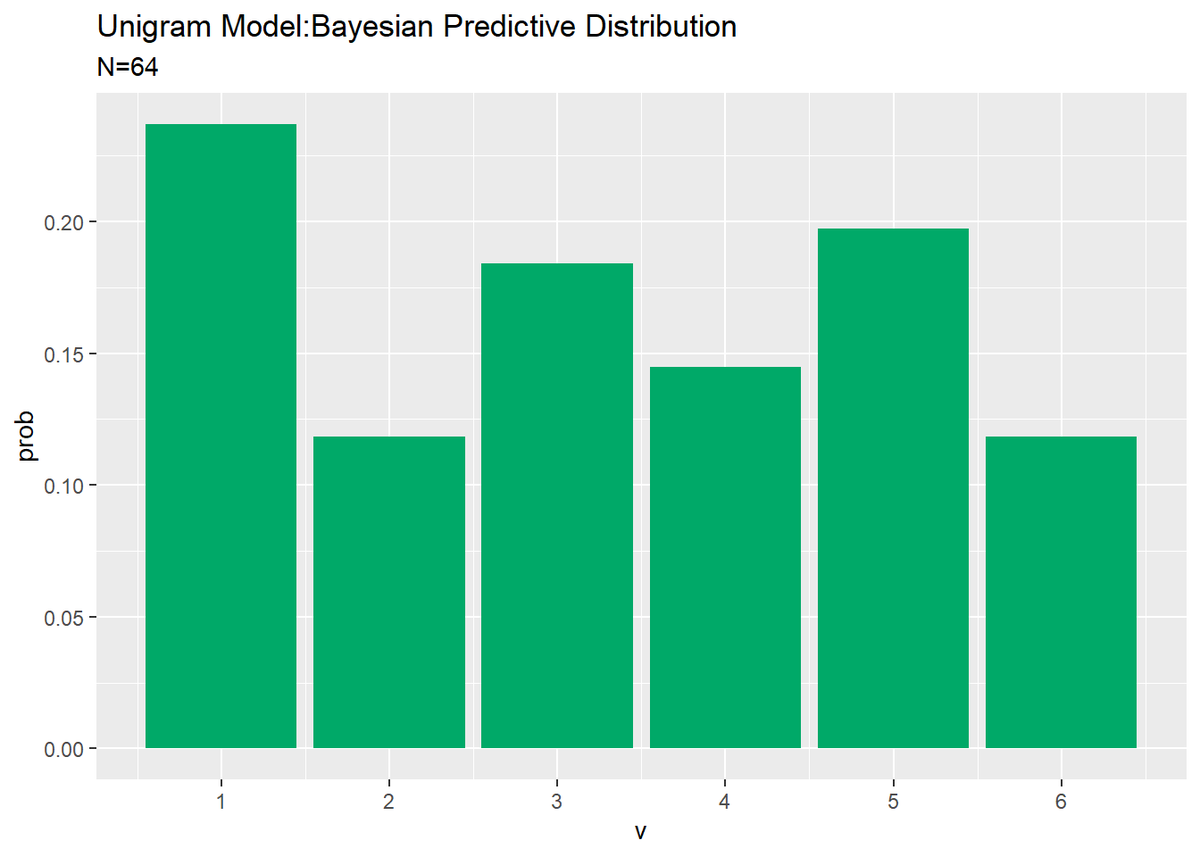
この例ではパラメータを一様に設定しているため、先ほどより観測データのばらつきの影響を受けてむしろ悪化したように感じます。パラメータを多様に設定すればもう少し印象が異なるかもしれません。
・試行回数:300
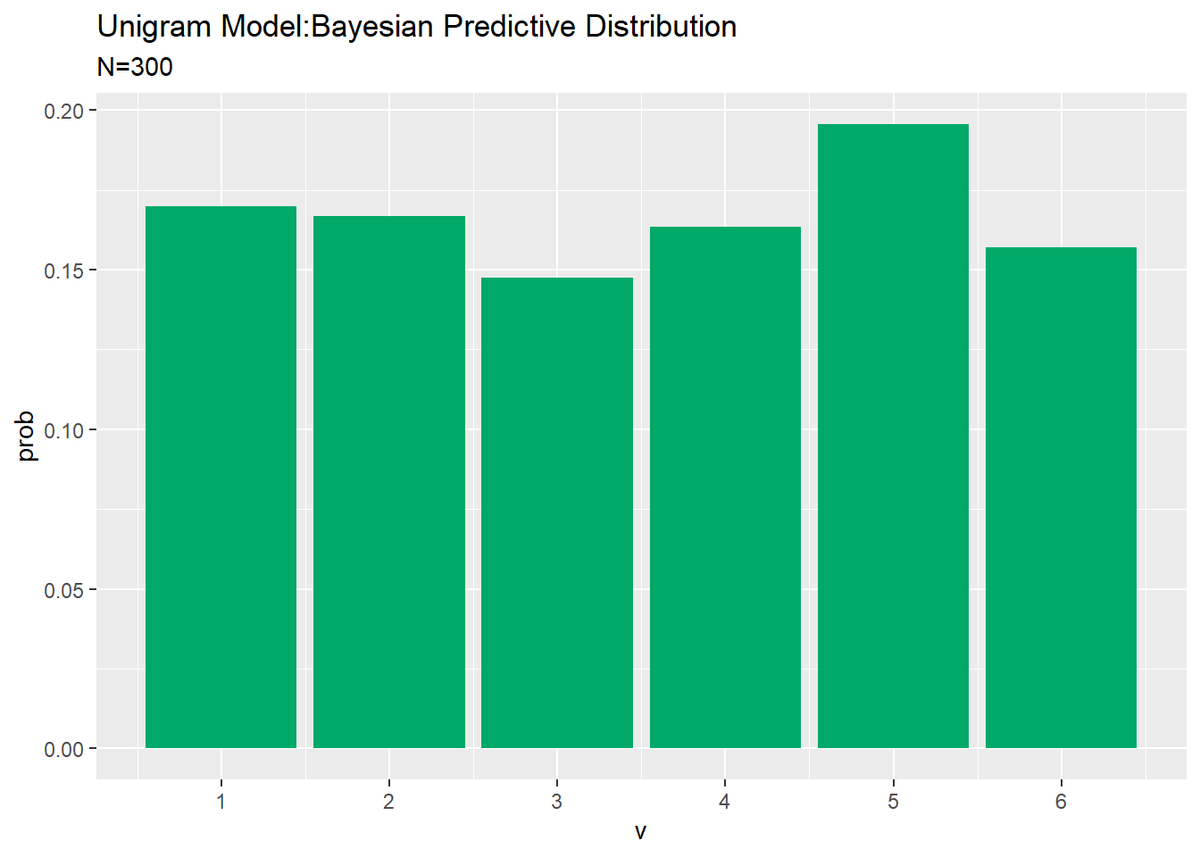
更に試行回数を増やすと真の値0.167に近づきました。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
2019.07.14:加筆修正しました。
Rで合計が1になるようにランダムに値を生成するというのをもっとスマートに実行したいです。今は合計値で割るという処理を行っています。
2020.07.01:加筆修正しました。
この記事の実装例では、うまく推定できているのかを分かりやすくするために、パラメータを一様に設定しています。しかしトピックモデルのパラメータは一様ではありません。また当然語彙数も6ではありません。変なイメージを付けないためにも、是非パラメータの値を変更して試してみてください!
【次節の内容】