〇はじめに
歌詞をテキスト分析することを目標に勉強しているのですが、歌詞には英語のテキストが頻繁に出てきます。MeCabだと英単語に品詞タグをうまく付けられないようです。その回避策として組んだものです。
日本語と英語の混合文から英語のみを抜き出し、英文形態素解析ツールのTreeTggerとRで用いるためのパッケージkoRpusを使って解析します。その結果から分析に不要な単語を絞り込み、元データのMeCab解析結果から取り除き、出現頻度表を作成します。
ありがたいことにこの記事は検索に引っかかるようでそれなりにアクセスがあります。ただ1年以上前に書いたもので、自分でも拙く感じるようになりました。書き直すつもりではいます。その一環で、(おそらく)この記事の核となる部分の内容を別記事にまとめました。こちらも参考にしてください。
〇日英混合文の処理
・使用パッケージ
library(RMeCab) library(dplyr) library(stringr)
・テキストファイルの確認
folder_name1 <- "フォルダ名" #テキストファイル保存場所を指定 file_name1 <- "テキストファイル名.txt" #テキストファイルを指定 file_path1 <- paste(folder_name1, file_name1, sep = "/") #入力用 dir.create("tmp") #加工中データの書き出し先ディレクトリを作成 folder_name2 <- "tmp" file_path2 <- paste(folder_name2, file_name1, sep = "/") #加工中のテキストの入出力用
分析するテキストを変更する際に手間にならないように、書き換える場所を1つに絞り変数として処理するようにしておく。
MeCabにかけるために一旦書き出さなければいけないので、一時保存先を用意する。
・記号類をテキストから取り除く
まず、MeCabで処理する際に邪魔になる記号等を消す。
#削除ワード(記号類)を指定する delete_word1 <- c("[\\-,.!?_…・×、。「」]") #不要な記号類 delete_word2 <- c("\\'s|\\'m|\\'re|\\'t|\\'ll") #MeCabがうまく扱えなかったもの
消したいものを指定する。
#記号類をテキストから消す tmp1 <- scan(file_path1, what = "char", sep = "\n") tmp2 <- gsub("\\(.*?\\)|≪.*?≫", "", tmp1) #括弧を中身ごと削除 tmp3 <- tmp2 %>% str_to_lower() %>% #アルファベットを全て小文字化 str_replace_all(delete_word1, " ") %>% #空白に置き換える str_replace_all(delete_word2, " ") %>% str_squish() #連続した空白を1つだけにする write(tmp3, file_path2) #MeCabにかける為に一旦書き出す tmp1 tmp3

消さないと解析時に、この例だと読みを示しているだけの"とき"を出現単語としてカウントしてしまったり、"時間"―"止まれ"という単語の繋がりを切ってしまったりすることになる。
アルファベットを小文字化して表記を整えることで、同じ単語と認識させる。
MeCabはテキストファイルの状態で解析するため、テキストを整えたら一旦書き出す。
・テキストから英文のみを抜き出す
まずはMeCabで形態素解析を行う。
#MeCabで解析する mixed_text1 <- RMeCabText(file_path2) mixed_text1[[1]][8]



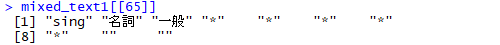
#英文を抜き出す mixed_df <- as.data.frame(mixed_text1) %>% t() #リストからデータフレームに変換後、列操作するために転置 token_lemma <- data.frame(token = unname(mixed_df[, 1]), lemma = unname(mixed_df[, 8])) #文中の単語列(token)と原形に直された単語列(lemma)からなるデータフレームを作成 token <- token_lemma$token[token_lemma$lemma == "*"] %>% as.character() #原形(lemma列)が"*"なのを英単語と判断してtoken列から文字列ベクトルを作成 english_text1 <- paste(token, collapse = " ") #単語間をくっつけて文章形式にする english_text1[english_text1 == ""] <- "からっぽ" #オブジェクトがc("")なら何かしら入れて、taggedText()のエラー回避 english_text1

そこから、出現単語をtoken列、見出し語をlemma列とするデータフレームを作成する。
lemma列の各要素が"*"なのかを調べる。
TRUEかFALSEで返ってくるので、それをtoken列の添え字として使う。
添え字がTRUEの要素だけが返ってくるので、tokenオブジェクトとして残す。
Factor形式のベクトルとなってしまうため、as.character()で文字列ベクトルにする。
最後に、1つの文章とするためにpaste()する。english_text1の中身が""だけの状態で、次のtaggedText()に渡すとエラーを起こすので、"からっぽ"(ネタ)を入れておく。
ただし、上の「日本語2」"フラリ"の結果のように、日本語が紛れ込む余地がある。
・TreeTaggerによる形態素解析と不要な英単語を抽出する
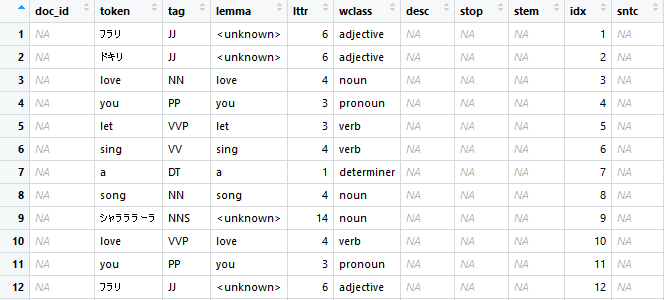
library(koRpus) library(koRpus.lang.en) kRp.env <- set.kRp.env(TT.cmd = "C:/TreeTagger/bin/tree-tagger.exe", lang = "en") #TreeTaggerを使うための設定 english_text2 <- taggedText(treetag(english_text1, treetagger = "manual", format = "obj", lang = "en", TT.options = list(path = "c:/TreeTagger", preset = "en"))) #TreeTaggerによる形態素解析
不要な英単語の絞り込み方法が2パターンできたのですが、どちらの方が優れているのか判断できないので両方載せておきます。
tagは品詞の事で、概ねNが名詞、Vが動詞となっている。lemmaは見出し語の事で動詞ならば原形の状態に変化している。(詳しくはTreeTaggerの記事で…)
#パターン1 english_text3 <- english_text2 %>% filter(!grepl("<unknown>|@card@", lemma)) %>% #"lemma"列に記号類のある行を削除 filter(!grepl("NN|PP|NP|VB|VD|VH|VV|JJ", tag)) #"tag"列に名詞,動詞,形容詞のある行を削除 del_english <- english_text3 %>% distinct(token, .keep_all = TRUE) #重複を削除
grepl()で消したい要素を抽出して、filter()と「!」でそれ以外の要素を返す。部分一致で検索している。
#パターン2 del_lemma <- english_text2$lemma %in% c("<unknown>", "@card@") #"lemma"列から記号類の位置(行数)を検索 english_text3 <- english_text2[!del_lemma, ] #検索した行を削除 del_tag <- english_text3$tag %in% c("NN", "PP", "NP", "VB", "VD", "VH", "VV", "JJ", "VVP", "VVD") #"tag"列から名詞,動詞,形容詞の位置(行数)を検索 english_text4 <- english_text3[!del_tag, ] #検索した行を削除 del_english <- english_text4 %>% distinct(token, .keep_all = TRUE) #重複を削除
データフレームの列指定と添え字で極力処理したもの。
「%in%」の左側(lemma列)の各要素が指定した右側の要素に含まれているかを調べる。含まれていればTRUE、なければFALSEを論理値ベクトルとして返す。それをdel_lemmaとして代入する。
del_lemmaを添え字として使い、パターン1と同じく「!」によってTRUE以外の行を抽出する。完全一致で検索しているので、tagで指定した要素がパターン1よりも多くなっている。
最後に、どちらのパターンもtokenの重複を削除した。
紛れ込んだ日本語もここで消えてもらう(lemmaの"
削除の基準は分析内容によって変更してください。(詳しくは今後の検討課題)
・混合文から不要の英単語を削除
#不要な英単語を削除する delete_word3 <- paste(del_english$token, sep = "", collapse = "$|^") delete_word3 <- paste(paste("^", delete_word3, "$", sep = "", collapse = "")) mixed_text2 <- docDF(file_path2, type = 1, pos = "名詞", "動詞", "形容詞") mixed_text3 <- filter(mixed_text2, !grepl(delete_word3, TERM))
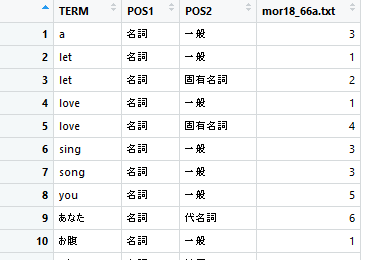
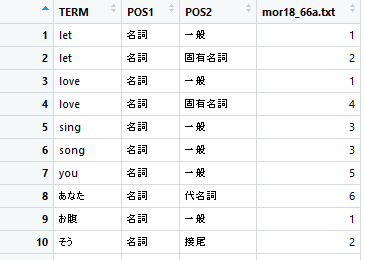
・頻度表の調整
mixed_text4 <- mixed_text3 %>% select(TERM, POS1, FREQ = file_name1) %>% #列名を"FREQ"にする group_by(TERM, POS1) %>% #POS列を落とすので重複する単語を統合 summarise(FREQ = sum(FREQ)) #統合する単語の出現頻度を加算
その際に、summarise()で頻度を加算する。
以上です。ちょっと例として選んだテキストが悪く"a"1つの変化となってしまいました。
〇おわりに
Rについての知識はこれが全てというくらいの現在の自分の集大成です。というかこれをするための勉強しかまだできていないという感じです。今後も改良されていくことでしょう。次は、ディレクトリ単位で全文書に対して一気にこの処理を行うシステムにするためこれに少し手を加えます。
www.anarchive-beta.com
最後まで読んでいただきありがとうございました。何かあれば教えてね!
2018.12.15.『RStudioで始めるRプログラミング入門』で得た知識をもとに加筆修正しました。ついでに、色々アプデしたらkoRpusパッケージの仕様が変わっててエラー吐かれて慌てたり、どれも勉強勉強!