はじめに
『トピックモデルによる統計的潜在意味解析』の学習時のメモです。本と併せて読んでください。
この記事では、3.3.5項のLDAの変分ベイズ法について書いています。図3.4の疑似コード(a)を基にR言語で実装していきます。
プログラムからアルゴリズムの理解を目指します。できるだけ基本的な(直感的に理解できる)関数を用いて組んでいきます。
【数理編】
【前節の内容】
【他の節一覧】
【この節の内容】
3.2.3 LDAの変分ベイズ法(1)
図3.4の疑似コードを参考にLDAに対する変分ベイズ法を実装していきます。
# 利用パッケージ library(tidyverse)
・簡易文書データ(クリックで展開)
## 簡易文書データ # 文書数 M <- 10 # 語彙数 V <- 20 # 文書ごとの各語彙の出現回数 n_dv <- matrix(sample(0:10, M * V, replace = TRUE), M, V)
・パラメータの設定
始めにパラメータ類の初期値を設定していきます。
# イタレーション数を指定 Iter <- 50 # トピック数を指定 K <- 5
試行回数をIter、トピックの数をKとします。
# 事前分布のパラメータを指定 alpha_k <- rep(2, K) beta_v <- rep(2, V)
トピック分布のパラメータ$\boldsymbol{\alpha} = (\alpha_1, \cdots, \alpha_K)$、単語分布のパラメータ$\boldsymbol{\beta} = (\beta_1, \cdots, \beta_V)$の値をそれぞれ指定します。どちらもディリクレ分布のパラメータなので、$\alpha_k > 0,\ \beta_v > 0$である必要があります。
この例では値を一様に設定します。
# 潜在トピック集合の分布の初期値 z_dv_k <- array(0, dim = c(M, V, K)) for(d in 1:M) { for(v in 1:V) { if(n_dv[d, v] > 0) { # ランダムに値を生成 tmp_q_z <- seq(0, 1, by = 0.01) %>% sample(size = K, replace = TRUE) # 正規化 z_dv_k[d, v, ] <- tmp_q_z / sum(tmp_q_z) } } }
各単語に潜在トピックを割り当てる確率$q(\boldsymbol{z})$の初期値をランダムに設定します。
$q(z_{d,i} = k)$の計算式(3.99)より同一単語の確率は同じになることから、ここではz_dv_kとして、文書・(単語$i$ではなく)語彙・トピックの3次元配列として扱うことにします。(前節では変数名を(トピック集合z_dvnと見分けやすくするため)q_z_dv_kとしたのでここでもそろえた方が分かりやすいかもしれません(tmp_q_zがその名残です)。)
この確率値z_dv_kを用いて、各トピックに関する統計量の初期値を計算します。
## 割り当てられたトピックに関する統計量を計算 tmp_n <- array(0, dim = c(M, V, K)) for(k in 1:K) { tmp_n[, , k] <- z_dv_k[, , k] * n_dv } # 各文書において各トピックが割り当てられる単語数の期待値 E_n_dk <- apply(tmp_n, c(1, 3), sum) # 全文書の各語彙において各トピックが割り当てられた語数の期待値 E_n_kv <- apply(tmp_n, c(3, 2), sum)
$\mathbb{E}_{q(\boldsymbol{z}_d)}[n_{d,k}],\ \mathbb{E}_{q(\boldsymbol{z})}[n_{k,v}]$の定義式は
です。
上で説明した通り、語彙として扱っているため各語彙の出現回数n_dvと掛けてから計算します。(上のif(n_dv[d, v] > 0)処理は出現回数0の語彙に確率値を与えないためですが、この処理を抜いてもここで掛けるn_dvの値が0なので問題ないです。)(for()を使わずスマートに計算したい…)
この2つの統計量を用いて、事後分布のパラメータを計算します。
# 事後分布パラメータの初期値 xi_dk <- t(t(E_n_dk) + alpha_k) xi_kv <- t(t(E_n_kv) + beta_v)
$\xi_{d,k}^{\theta},\ \xi_{k,v}^{\phi}$の計算式は
です。
変数名をxi.theta_dk, xi.phi_kvとした方が分かりやすいかもしれません。
・変分ベイズ法(1)
続いて推論部分を実装していきます。
・コード全体(クリックで展開)
# 推移の確認用 trace_xi_theta <- array(0, dim = c(M, K, Iter + 1)) trace_xi_phi <- array(0, dim = c(K, V, Iter + 1)) # 初期値を代入 trace_xi_theta[, , 1] <- xi_dk trace_xi_phi[, , 1] <- xi_kv for(I in 1:Iter) { ## (イタレーション) # 動作確認用 start_time <- Sys.time() for(d in 1:M) { ## (各文書) for(v in 1:V) { ## (各語彙) if(n_dv[d, v] > 0) { # 潜在トピック集合の事後分布を計算:式(3.99) term_phi <- digamma(xi_kv[, v]) - digamma(apply(xi_kv, 1, sum)) term_theta <- digamma(xi_dk[d, ]) - digamma(apply(xi_dk, 2, sum)) tmp_q_z <- exp(term_phi + term_theta) z_dv_k[d, v, ] <- tmp_q_z / sum(tmp_q_z) # 正規化 } } ## (/各語彙) # 各文書において各トピックが割り当てられる単語数の期待値を更新 E_n_dk[d, ] <- apply(z_dv_k[d, , ] * n_dv[d, ], 2, sum) # 事後分布のパラメータを計算:式(3.89) xi_dk[d, ] <- E_n_dk[d, ] + alpha_k } ## (/各文書) for(k in 1:K) { ## (各トピック) # 全文書の各語彙において各トピックが割り当てられた語数の期待値 E_n_kv[k, ] <- apply(z_dv_k[, , k] * n_dv, 2, sum) # 事後分布のパラメータ:式(3.95) xi_kv[k, ] <- E_n_kv[k, ] + beta_v } ## (/各トピック) # 推移の確認用 trace_xi_theta[, , I + 1] <- xi_dk trace_xi_phi[, , I + 1] <- xi_kv # 動作確認 #print(paste0(I, "th try...", round(Sys.time() - start_time, 3))) }
・$q(\boldsymbol{z})$の更新
# 潜在トピック集合の事後分布を計算:式(3.99) term_phi <- digamma(xi_kv[, v]) - digamma(apply(xi_kv, 1, sum)) term_theta <- digamma(xi_dk[d, ]) - digamma(apply(xi_dk, 2, sum)) tmp_q_z <- exp(term_phi + term_theta) z_dv_k[d, v, ] <- tmp_q_z / sum(tmp_q_z) # 正規化
語彙ごとに、式(3.99)の計算を行います。
総和が1となるように正規化します。
更新したz_dv_k[d, , ]を用いて、残りの事後分布も更新します。
・$q(\boldsymbol{\theta})$の更新
# 各文書において各トピックが割り当てられる単語数の期待値を更新 E_n_dk[d, ] <- apply(z_dv_k[d, , ] * n_dv[d, ], 2, sum)
初期値のときは全ての要素を1度に計算しましたが、文書1つずつ更新します。
次にこの統計量E_n_dk[d, ]を用いて、ハイパーパラメータxi_dk[d, ]を更新します。
# 事後分布のパラメータを計算:式(3.89) xi_dk[d, ] <- E_n_dk[d, ] + alpha_k
$q(\boldsymbol{\theta}_d)$のパラメータの更新式(3.89)の計算を行い、ハイパーパラメータを更新します。
これを文書1からMまで繰り返し、$q(\boldsymbol{\theta})$を全て更新します。
・$q(\boldsymbol{\phi})$の更新
# 全文書の各語彙において各トピックが割り当てられた語数の期待値 E_n_kv[k, ] <- apply(z_dv_k[, , k] * n_dv, 2, sum)
初期値のときは全ての要素を1度に計算しましたが、トピック1つずつ更新します。
次にこの統計量E_n_kv[k, ]を用いて、ハイパーパラメータxi_kv[k, ]を更新します。
# 事後分布のパラメータ:式(3.95) xi_kv[k, ] <- E_n_kv[k, ] + beta_v
$q(\boldsymbol{\phi}_k)$のパラメータの更新式(3.95)の計算を行い、ハイパーパラメータを更新します。
これをトピック1からKまで繰り返し、$q(\boldsymbol{\phi})$を全て更新します。
・推定結果の確認
ggplot2パッケージを利用して、推定結果を可視化しましょう。
ディリクレ分布の期待値(2.10)の計算を行いパラメータの期待値を作図します。
・トピック分布(クリックで展開)
## トピック分布(期待値) # thetaの期待値を計算:式(2.10) theta_dk <- xi_dk / apply(xi_dk, 1, sum) # 作図用のデータフレームを作成 theta_df_wide <- cbind( as.data.frame(theta_dk), doc = as.factor(1:M) # 文書番号 ) # データフレームをlong型に変換 theta_df_long <- pivot_longer( theta_df_wide, cols = -doc, # 変換せずにそのまま残す現列名 names_to = "topic", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(topic = factor()), # 現列名を要素とする際の型 values_to = "prob"# 現要素を格納する新しい列の名前 ) # 作図 ggplot(theta_df_long, aes(x = topic, y = prob, fill = topic)) + geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap( ~ doc, labeller = label_both) + # グラフの分割 labs(title = "Variational Bayes for LDA (1)", subtitle = expression(Theta)) # ラベル
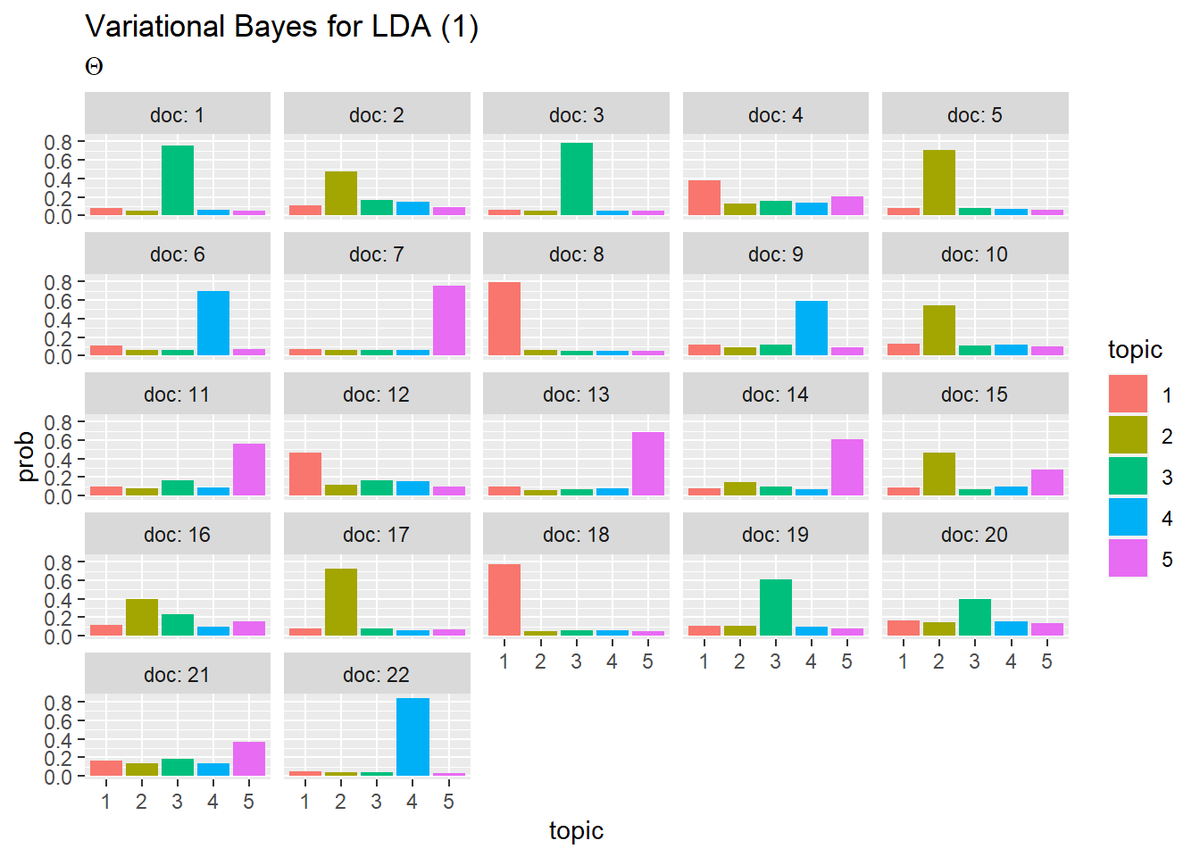
・単語分布(クリックで展開)
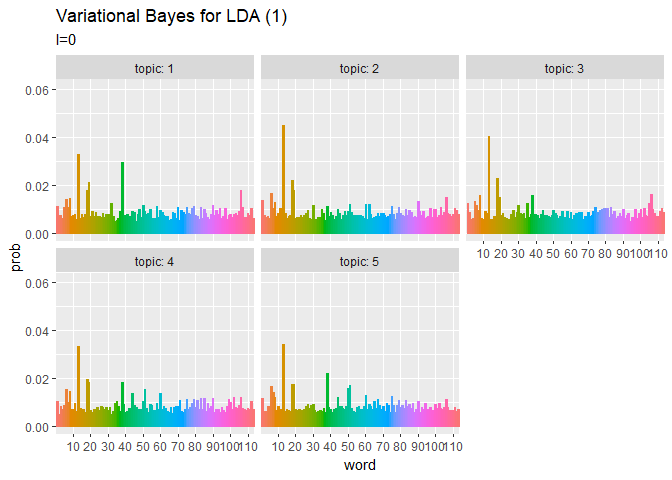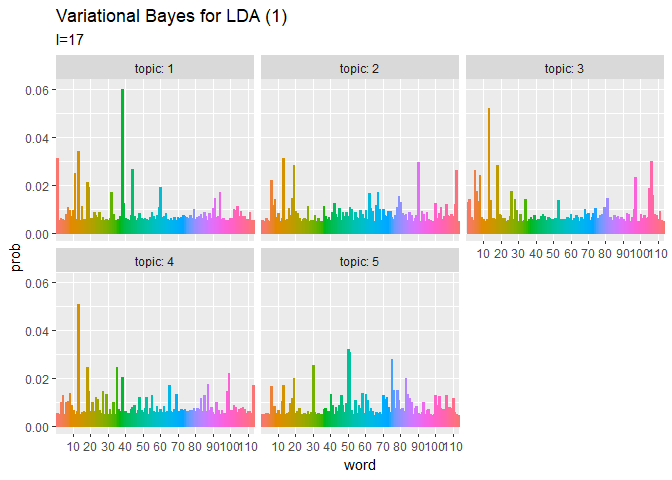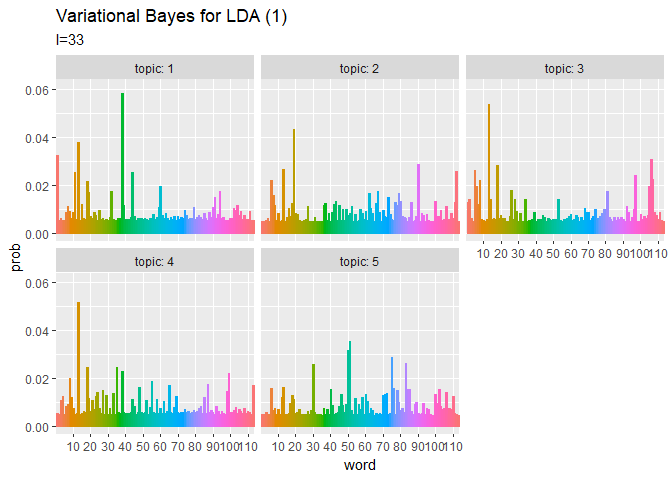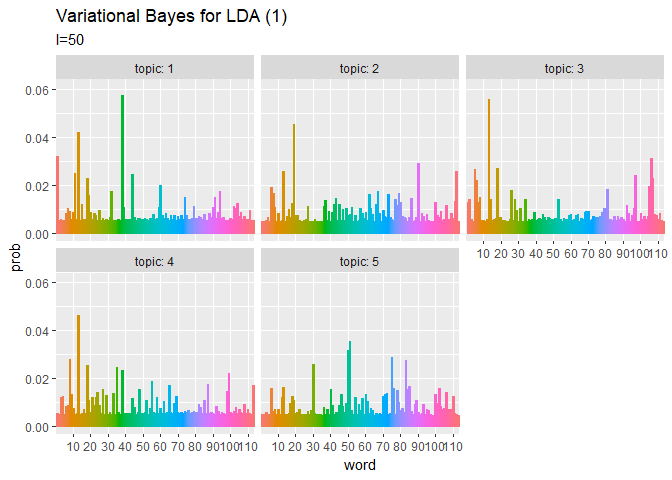
## 単語分布(期待値) # phiの期待値を計算:式(2.10) phi_kv <- xi_kv / apply(xi_kv, 1, sum) # 作図用のデータフレームを作成 phi_df_wide <- cbind( as.data.frame(phi_kv), topic = as.factor(1:K) # トピック番号 ) # データフレームをlong型に変換 phi_df_long <- pivot_longer( phi_df_wide, cols = -topic, # 変換せずにそのまま残す現列名 names_to = "word", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(word = factor()), # 現列名を要素とする際の型 values_to = "prob" # 現要素を格納する新しい列の名前 ) # 作図 ggplot(phi_df_long, aes(x = word, y = prob, fill = word, color = word)) + geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap( ~ topic, labeller = label_both) + # グラフの分割 scale_x_discrete(breaks = seq(0, V, by = 10)) + # x軸目盛 theme(legend.position = "none") + # 凡例 labs(title = "Variational Bayes for LDA (1)", subtitle = expression(Phi)) # ラベル
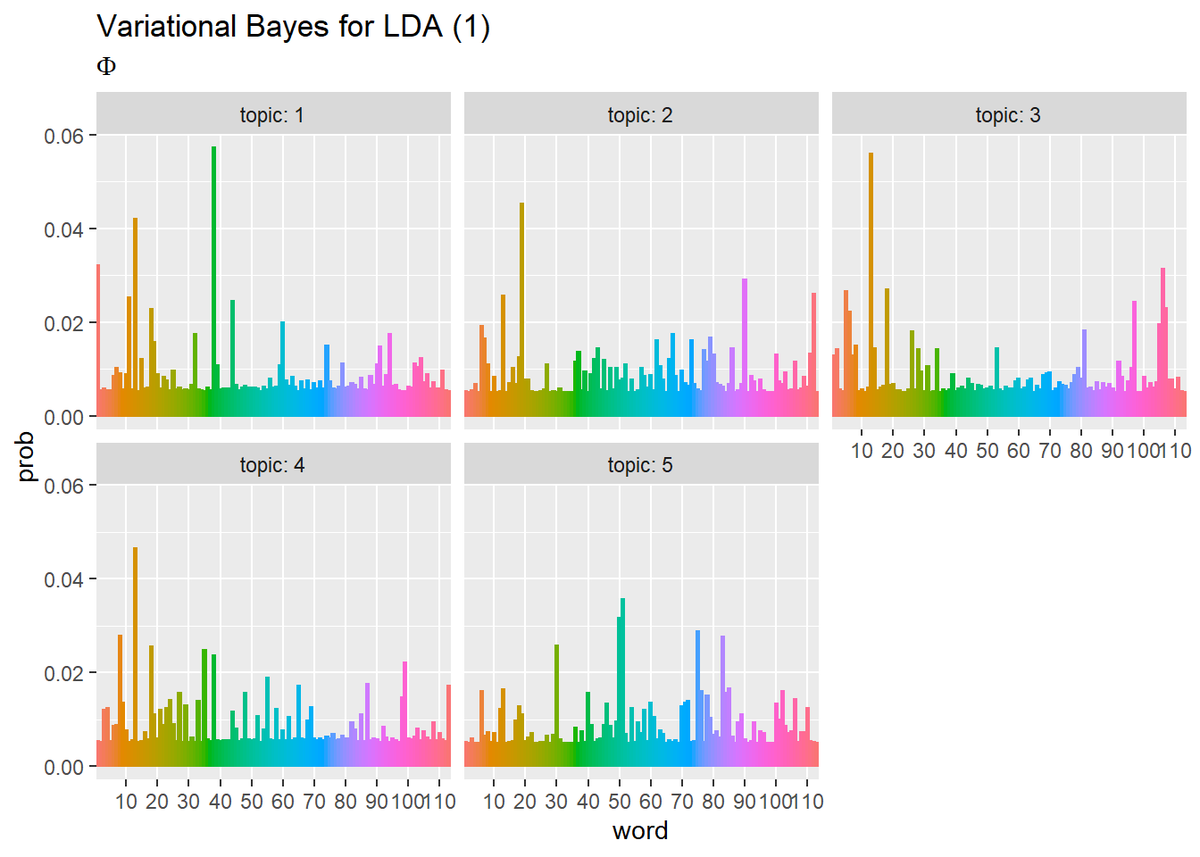
・更新値の推移の確認
・トピック分布(クリックで展開)
## トピック分布のパラメータ # 作図用のデータフレームを作成 trace_xi_theta_df_wide <- data.frame() for(I in 1:(Iter + 1)) { # データフレームに変換 tmp_trace_xi_theta <- cbind( as.data.frame(trace_xi_theta[, , I]), doc = as.factor(1:M), # 文書番号 iteration = I - 1 # 試行回数 ) # 結合 trace_xi_theta_df_wide <- rbind(trace_xi_theta_df_wide, tmp_trace_xi_theta) } # データフレームをlong型に変換 trace_xi_theta_df_long <- pivot_longer( trace_xi_theta_df_wide, cols = -c(doc, iteration), # 変換せずにそのまま残す現列名 names_to = "topic", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(topic = factor()), # 現列名を要素とする際の型 values_to = "value" # 現要素を格納する新しい列の名前 ) # 文書番号を指定 doc_num <- 16 # 作図 trace_xi_theta_df_long %>% filter(doc == doc_num) %>% ggplot(aes(x = iteration, y = value, color = topic)) + geom_line() + labs(title = "Variational Bayes for LDA (1)", subtitle = expression(xi^theta)) # ラベル
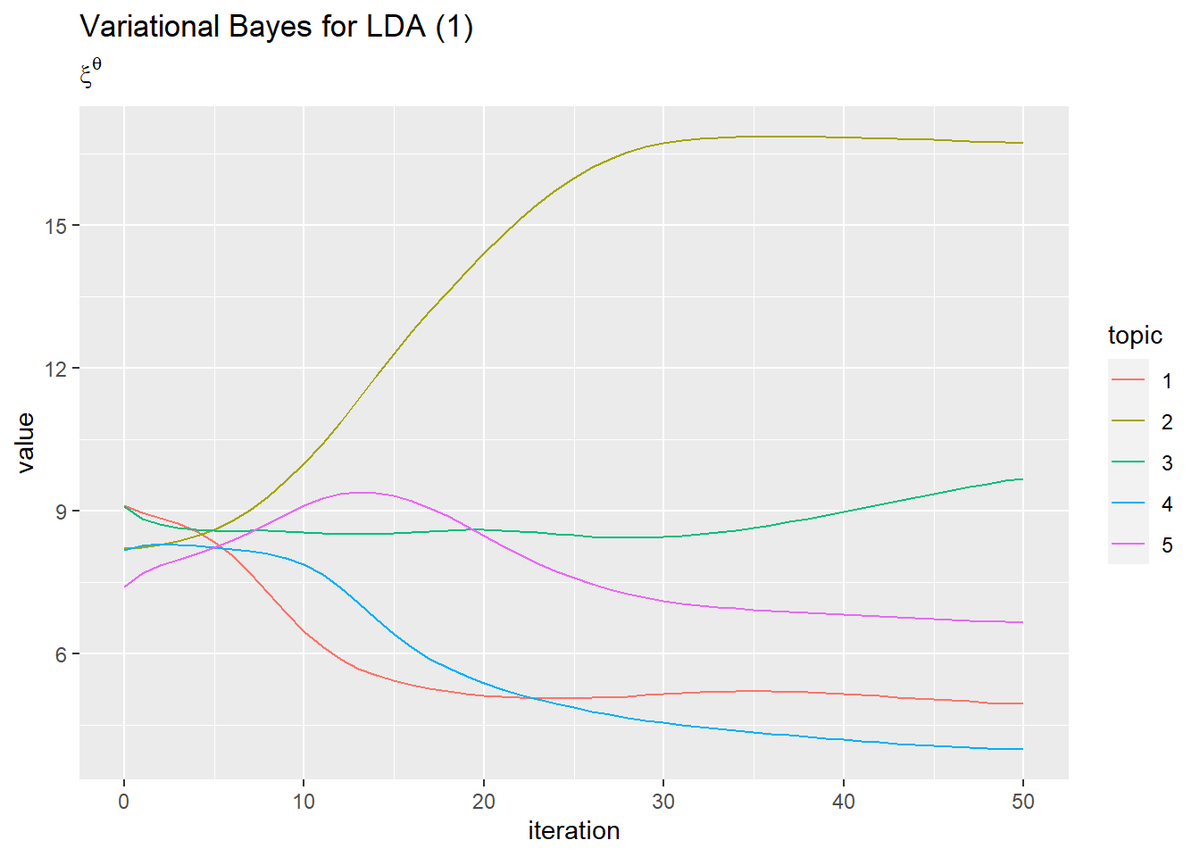
・単語分布(クリックで展開)
## トピック分布のパラメータ # 作図用のデータフレームを作成 trace_xi_phi_df_wide <- data.frame() for(I in 1:(Iter + 1)) { # データフレームに変換 tmp_trace_xi_phi <- cbind( as.data.frame(trace_xi_phi[, , I]), topic = as.factor(1:K), iteration = I - 1 ) # 結合 trace_xi_phi_df_wide <- rbind(trace_xi_phi_df_wide, tmp_trace_xi_phi) } # データフレームをlong型に変換 trace_xi_phi_df_long <- pivot_longer( trace_xi_phi_df_wide, cols = -c(topic, iteration), # 変換せずにそのまま残す現列名 names_to = "word", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(word = factor()), # 現列名を要素とする際の型 values_to = "value" # 現要素を格納する新しい列の名前 ) # トピック番号を指定 topic_num <- 4 # 作図 trace_xi_phi_df_long %>% filter(topic == topic_num) %>% ggplot(aes(x = iteration, y = value, color = word)) + geom_line(alpha = 0.5) + theme(legend.position = "none") + # 凡例 labs(title = "Variational Bayes for LDA (1)", subtitle = expression(xi^phi)) # ラベル
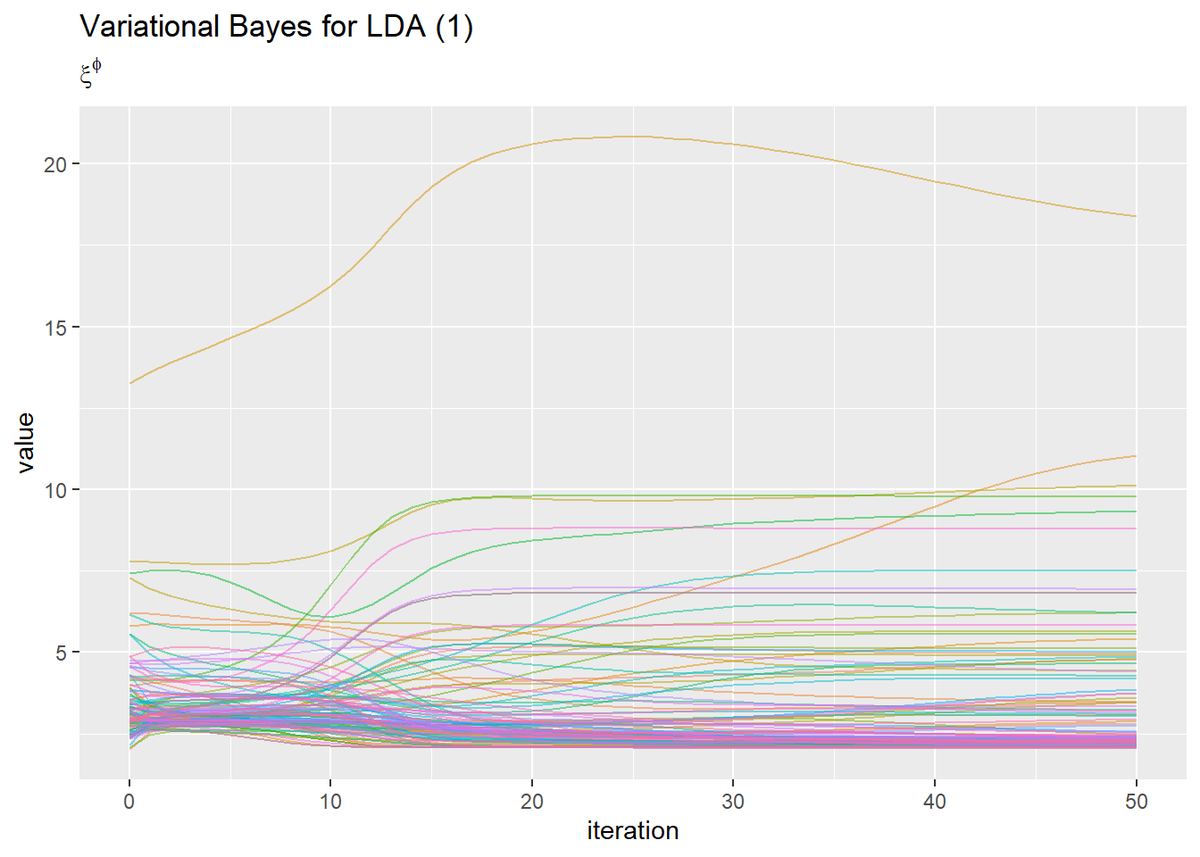
・gif画像を作成
更新ごとの分布の変化をgif画像でみるためのコードです。gganimateパッケージを利用してgif画像を作成します。
・コード(クリックで展開)
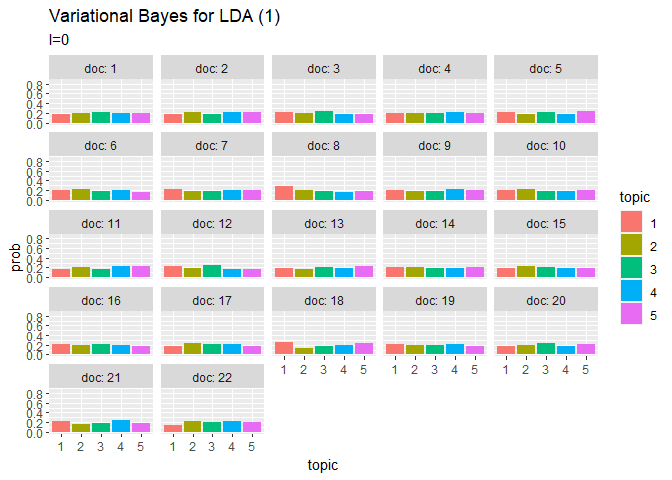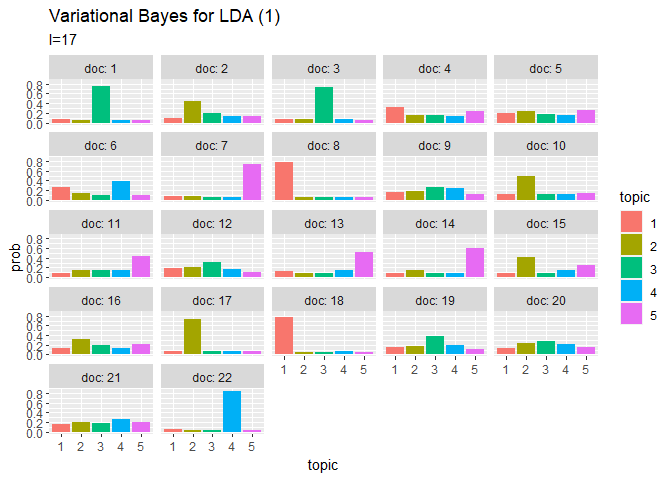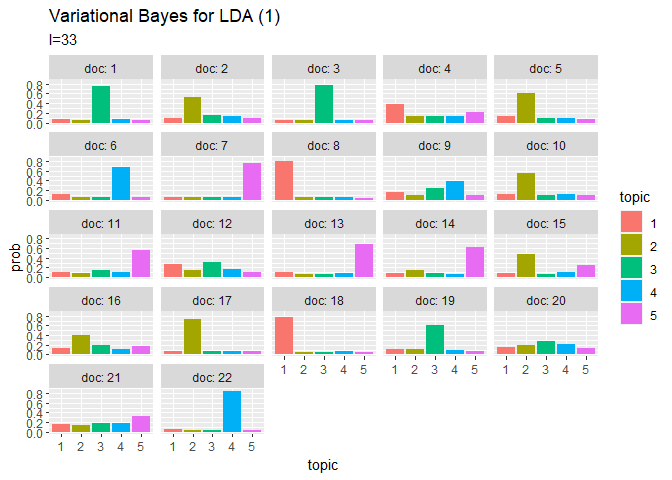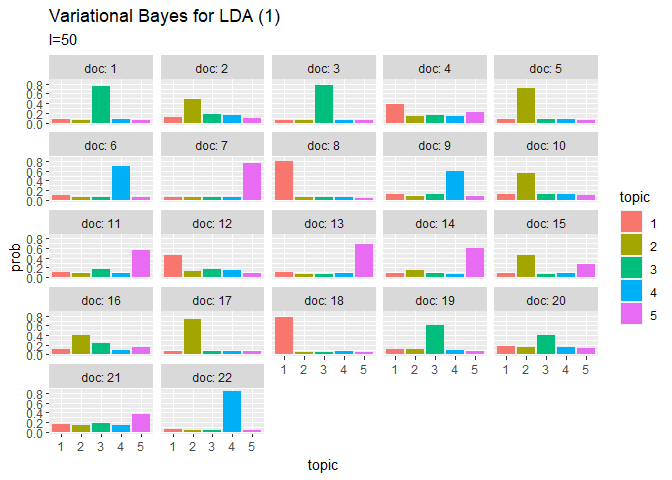
# 利用パッケージ library(gganimate) ## トピック分布(期待値) # 作図用のデータフレームを作成 trace_theta_df_wide <- data.frame() for(I in 1:(Iter + 1)) { # データフレームに変換 tmp_trace_theta <- cbind( as.data.frame(trace_xi_theta[, , I] / apply(trace_xi_theta[, , I], 1, sum)), # 期待値計算 doc = as.factor(1:M), iteration = I - 1 ) # 結合 trace_theta_df_wide <- rbind(trace_theta_df_wide, tmp_trace_theta) } # データフレームをlong型に変換 trace_theta_df_long <- pivot_longer( trace_theta_df_wide, cols = -c(doc, iteration), # 変換せずにそのまま残す現列名 names_to = "topic", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(topic = factor()), # 現列名を要素とする際の型 values_to = "prob" # 現要素を格納する新しい列の名前 ) # 作図 graph_theta <- ggplot(trace_theta_df_long, aes(x = topic, y = prob, fill = topic)) + geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap( ~ doc, labeller = label_both) + # グラフの分割 transition_manual(iteration) + labs(title = "Variational Bayes for LDA (1)", subtitle = "I={current_frame}") # ラベル # gif画像を作成 animate(graph_theta, nframes = (Iter + 1), fps = 10) ## 単語分布(期待値) # 作図用のデータフレームを作成 trace_phi_df_wide <- data.frame() for(I in 1:(Iter + 1)) { # データフレームに変換 tmp_trace_phi <- cbind( as.data.frame(trace_xi_phi[, , I] / apply(trace_xi_phi[, , I], 1, sum)), # 期待値計算 topic = as.factor(1:K), iteration = I - 1 ) # 結合 trace_phi_df_wide <- rbind(trace_phi_df_wide, tmp_trace_phi) } # データフレームをlong型に変換 trace_phi_df_long <- pivot_longer( trace_phi_df_wide, cols = -c(topic, iteration), # 変換せずにそのまま残す現列名 names_to = "word", # 現列名を格納する新しい列の名前 names_prefix = "V", # 現列名から取り除く文字列 names_ptypes = list(word = factor()), # 現列名を要素とする際の型 values_to = "prob" # 現要素を格納する新しい列の名前 ) # 作図 graph_phi <- ggplot(trace_phi_df_long, aes(x = word, y = prob, fill = word, color = word)) + geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap( ~ topic, labeller = label_both) + # グラフの分割 scale_x_discrete(breaks = seq(0, V, by = 10)) + # x軸目盛 theme(legend.position = "none") +# 凡例 transition_manual(iteration) + labs(title = "Variational Bayes for LDA (1)", subtitle = "I={current_frame}") # ラベル # gif画像を作成 animate(graph_phi, nframes = (Iter + 1), fps = 10)
transition_manual()に時系列値の列を指定します。
参考文献
- 佐藤一誠『トピックモデルによる統計的潜在意味解析』(自然言語処理シリーズ 8)奥村学監修,コロナ社,2015年.
おわりに
当然なのでしょうけど、ギブスサンプリングのときとは違って滑らかに推移しますね。
これは青本でも組んだやつなので、比較的すんなりできました。
【次節の内容】
正確には次節ではなくこの節の別バージョンです。まぁそもそも単位は節ではなく項だし。。。