はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、ユニグラムモデルにおけるMAP推定(パラメータ推定)をR言語でスクラッチ実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
2.4 ユニグラムモデルのMAP推定の実装
ユニグラムモデル(unigram model)に対する最大事後確率推定(MAP推定・maximum a posteriori estimation)を実装する。
ユニグラムモデルの定義や記号については「2.2:ユニグラムモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」、パラメータの計算式については「2.4:ユニグラムモデルのMAP推定の導出:パラメータ推定【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
利用するパッケージを読み込む。
# 利用パッケージ library(tidyverse) library(MCMCpack) library(ggpattern)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージの読み込みは不要である。ただし、作図コードについてはパッケージ名を省略するので、ggplot2 を読み込む必要がある。
また、ネイティブパイプ演算子 |> を使う。magrittrパッケージのパイプ演算子 %>% に置き換えられるが、その場合は magrittr を読み込む必要がある。
文書データの簡易生成
まずは、ユニグラムモデルの生成モデルに従って、bag-of-words表現の文書データ(語彙頻度データ)を生成する。
トイデータの作成については「生成モデルの実装」を参照のこと。
真の分布などの本来は得られない情報についてはオブジェクト名に true を付けて表す。
処理コード(クリックで展開)
パラメータ類を設定して、文書データを作成する。
# 文書数を指定 D <- 10 # 語彙数を指定 V <- 6 # 単語分布のハイパーパラメータを指定 true_beta <- 1 true_beta_v <- rep(true_beta, times = V) # 単語分布のパラメータを生成 #true_phi_v <- rep(1/V, times = V) # 一様な値の場合 true_phi_v <- MCMCpack::rdirichlet(n = 1, alpha = true_beta_v) |> # 多様な値の場合 as.vector() # 各文書の単語数を生成 N_d <- sample(x = 10:20, size = D) # 下限・上限を指定 # 文書データを生成 N_dv <- matrix(NA, nrow = D, ncol = V) for(d in 1:D) { # 各語彙の出現回数を生成 N_dv[d, ] <- rmultinom(n = 1, size = N_d[d], prob = true_phi_v) |> # (多項乱数) as.vector() # 途中経過を表示 print(paste0("document: ", d, ", words: ", N_d[d])) }
[1] "document: 1, words: 16" [1] "document: 2, words: 20" [1] "document: 3, words: 12" [1] "document: 4, words: 19" [1] "document: 5, words: 14" [1] "document: 6, words: 10" [1] "document: 7, words: 17" [1] "document: 8, words: 11" [1] "document: 9, words: 13" [1] "document: 10, words: 15"
文書数 、語彙数
、単語分布(カテゴリ分布)の真のハイパーパラメータ
を指定して、真のパラメータ
を生成する。
文書ごとに単語数 を決めて、多項分布の乱数により各語彙の出現回数
を生成する。
文書データを確認する。
# 観測データを確認 head(N_dv); head(N_d)
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 10 1 0 2 0 3 [2,] 11 3 1 2 2 1 [3,] 4 4 0 2 1 1 [4,] 5 2 1 7 2 2 [5,] 4 2 1 5 0 2 [6,] 3 0 0 5 1 1 [1] 16 20 12 19 14 10
真の単語分布をグラフで確認する。
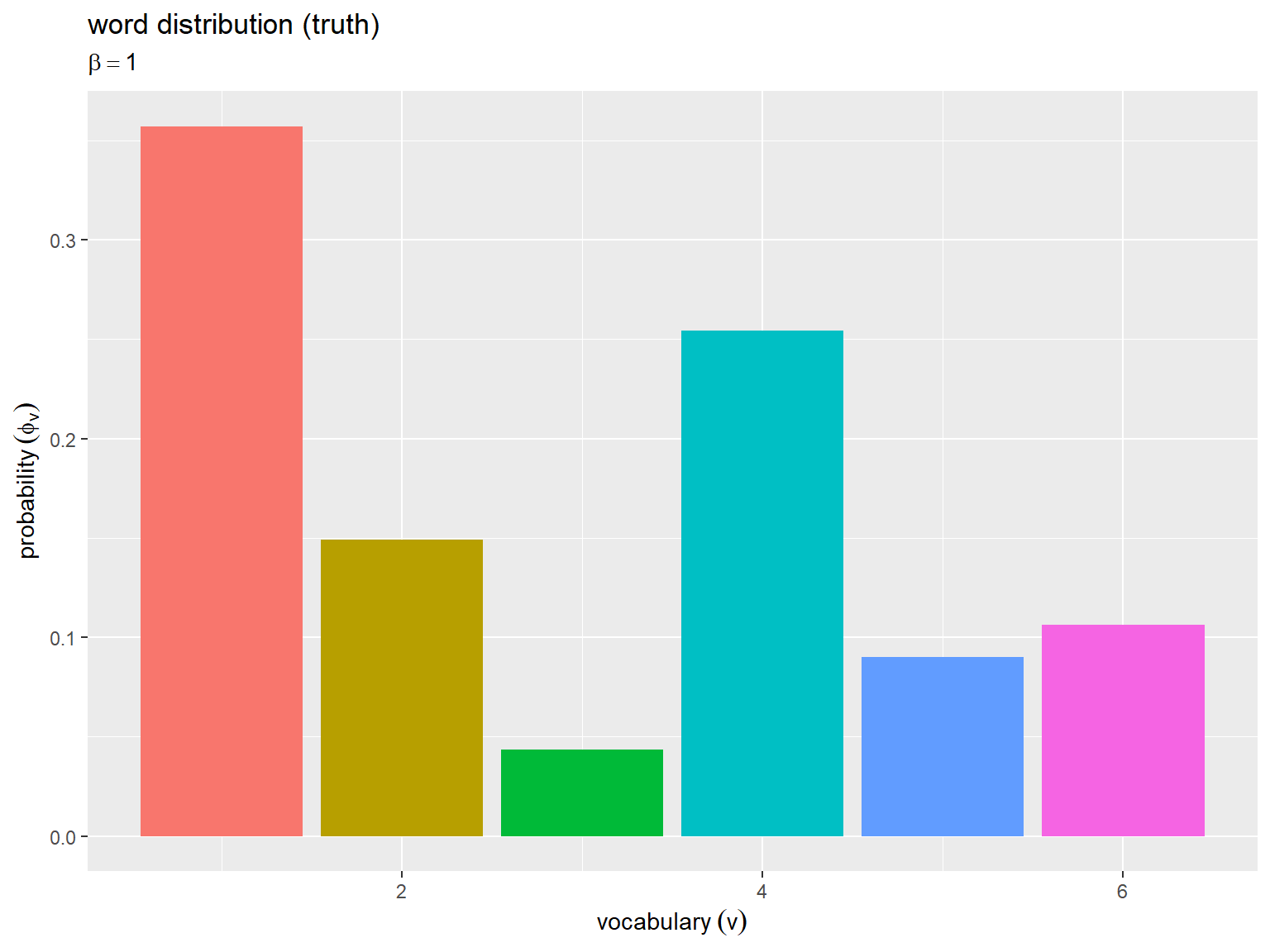
横軸は語彙番号 、縦軸は各語彙の出現(生成)確率
を表す。
文書ごとの語彙頻度をグラフで確認する。
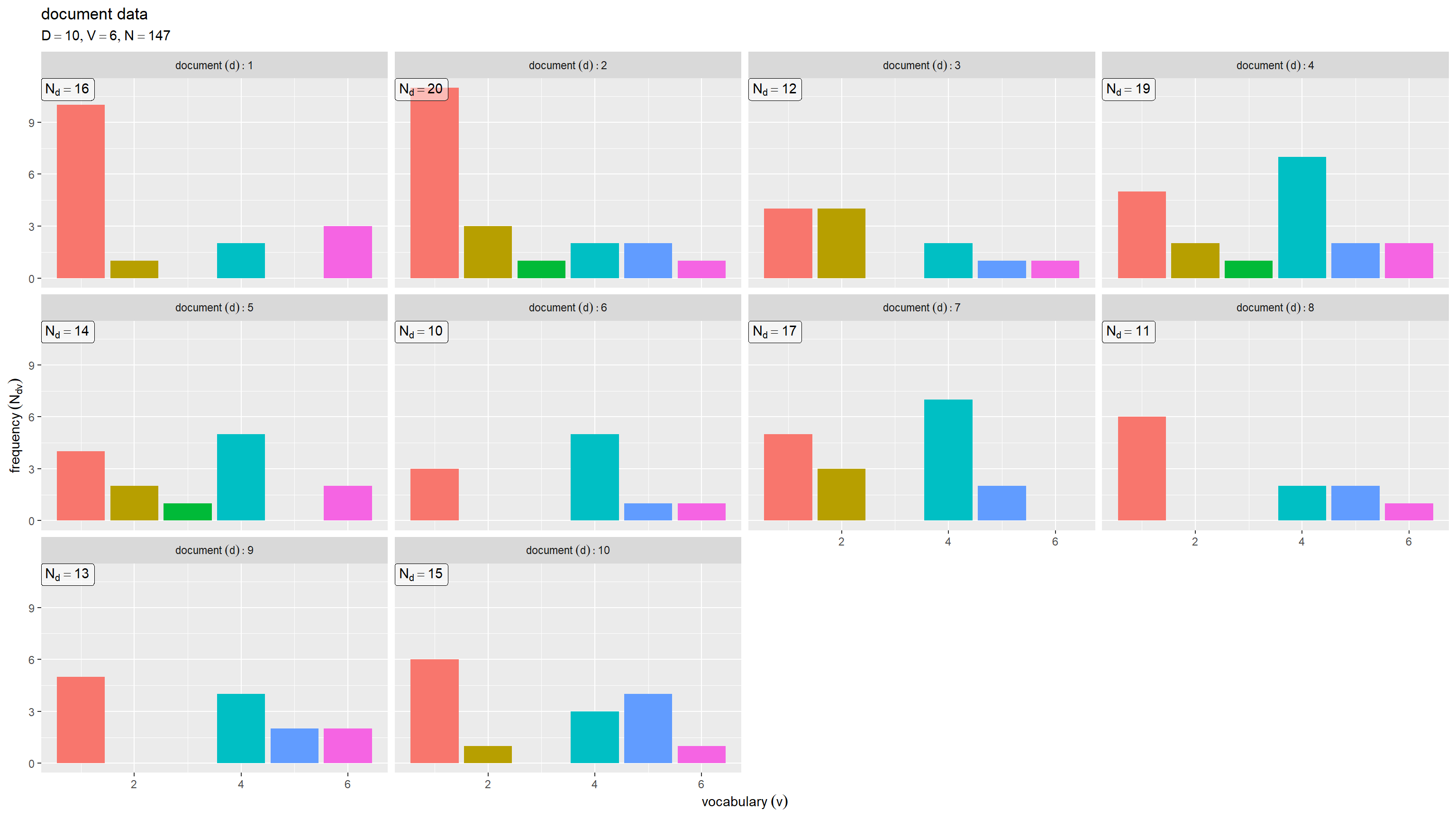
横軸は語彙番号 、縦軸は文書ごとの各語彙の出現回数
を表すグラフを文書ごとに縦横に並べる。
全文書での語彙頻度をグラフで確認する。

横軸は語彙番号 、縦軸は全文書での各語彙の出現回数
を表す。
文書集合 から得られる語彙頻度データ
のみを用いてパラメータ類を推定する。
パラメータの推定
次は、MAP推定によりパラメータを推定する。
文書集合に関する値を設定する。
# 文書数を取得 D <- nrow(N_dv) # 語彙数を取得 V <- ncol(N_dv) # 全文書の単語数を取得 N <- sum(N_dv) # 各文書の単語数を取得 N_d <- rowSums(N_dv) # 各語彙の出現回数を取得 N_v <- colSums(N_dv) D; V; N; N_d; N_v
[1] 10 [1] 6 [1] 147 [1] 16 20 12 19 14 10 17 11 13 15 [1] 59 16 3 39 16 14
観測データ N_dv から文書数 、語彙数
、単語数
、各文書の単語数
、
、各語彙の単語数
、
を取得する。
ハイパーパラメータを設定する。
# 単語分布のハイパーパラメータを指定 beta <- 2
単語分布の事前分布(ディリクレ分布)のパラメータの初期値 を指定する。
単語分布のパラメータのMAP解を計算する。
# 単語分布のパラメータを計算 phi_v <- (N_v + beta - 1) / (N + V * (beta - 1)) phi_v; sum(phi_v)
[1] 0.39215686 0.11111111 0.02614379 0.26143791 0.11111111 0.09803922 [1] 1
単語分布のパラメータ の各項を、次の式で計算する。
以上で、MAP推定によりパラメータを推定した。
推定結果の可視化
続いて、推定したパラメータや分布のグラフを作成する。
分布の図
単語分布の描画用のデータフレームを作成する。
# 推定した単語分布を格納 phi_df <- tibble::tibble( v = 1:V, prob = phi_v ) phi_df
# A tibble: 6 × 2
v prob
<int> <dbl>
1 1 0.392
2 2 0.111
3 3 0.0261
4 4 0.261
5 5 0.111
6 6 0.0980
語彙番号 とパラメータ
を格納する。
ハイパーパラメータの影響範囲の描画用のデータフレームを作成する。
# ハイパーパラメータによる基準値を格納 beta_df <- tibble::tibble( v = 1:V, base = (beta - 1) / (N + V * (beta - 1)) ) beta_df
# A tibble: 6 × 2
v base
<int> <dbl>
1 1 0.00654
2 2 0.00654
3 3 0.00654
4 4 0.00654
5 5 0.00654
6 6 0.00654
語彙番号 と
におけるハイパーパラメータが占める値
を格納する。
単語分布のグラフを作成する。
# 真の単語分布を格納 true_phi_df <- tibble::tibble( v = 1:V, prob = true_phi_v ) # ラベル用の文字列を作成 param_label <- paste0( "list(", "beta == ", beta, ", ", "N == ", N, ")" ) # 凡例用の設定を格納 linetype_lt <- list( fill = c("gray", NA, NA), color = c(NA, "red", "navyblue"), linewidth = 0.5, pattern = c("none", "none", "crosshatch") ) # 単語分布を作図 ggplot() + geom_bar(data = phi_df, mapping = aes(x = v, y = prob, fill = factor(v), linetype = "estimated"), stat = "identity", show.legend = FALSE) + # 推定した分布 ggpattern::geom_bar_pattern( data = beta_df, mapping = aes(x = v, y = base, linetype = "hyparam"), stat = "identity", fill = NA, color = "navyblue", pattern_fill = "navyblue", pattern_color = NA, pattern = "crosshatch", pattern_density = 0.05, pattern_spacing = 0.08 ) + # ハイパラによる基準値 geom_bar(data = true_phi_df, mapping = aes(x = v, y = prob, linetype = "true"), stat = "identity", show.legend = FALSE, fill = NA, color = "red", linewidth = 1) + # 真の分布 scale_linetype_manual(breaks = c("estimated", "true", "hyparam"), values = c("solid", "dashed", "dotted"), labels = c("estimated", "true", "hyperparameter"), name = "distribution") + # 凡例の表示用 guides(linetype = guide_legend(override.aes = linetype_lt)) + # 凡例の体裁 labs(title = "word distribution (maximum a posteriori estimation)", subtitle = parse(text = param_label), x = expression(vocabulary ~ (v)), y = expression(probability ~ (phi[v])))

横軸は語彙番号 、縦軸は各語彙の出現確率
を表す。
真の分布を赤色の破線、推定した分布を塗りつぶしで示す。また、ハイパーパラメータの影響範囲を紺色の点線と斜線で示す。
ハイパーパラメータ は全ての語彙に一定の影響を与え、各語彙は出現回数
の影響を受けるのが図や
の計算式から分かる。
推定への影響の可視化
最後は、パラメータなどの推定結果への影響をグラフで確認する。
アニメーションなどの作図コードは「map_estimation.R · anemptyarchive/Topic-Models-AO · GitHub」を参照のこと。
ハイパーパラメータの影響
ハイパーパラメータの影響をアニメーションで確認する。
が大きくなるほど出現回数
による各語彙への影響が小さくなる(一様分布に近付く)を確認できる。
KLダイバージェンスの推移をグラフで確認する。

横軸はハイパーパラメータ 、縦軸は真のパラメータ
とデータ数
のときのMAP推定値
のKLダイバージェンスを表す。
KLダイバージェンスについては「1.1.8-10:カルバック・ライブラー・ダイバージェンスとイェンゼンの不等式【『トピックモデル』の勉強ノート】 - からっぽのしょこ」を参照のこと。
データ数の影響
データ数の影響をアニメーションで確認する。
新たに観測された語彙をオレンジ色の点で示す。
が大きくなるほど真の分布の形状に近付いていき、また
の影響が小さくなるを確認できる。
KLダイバージェンスの推移をグラフで確認する。
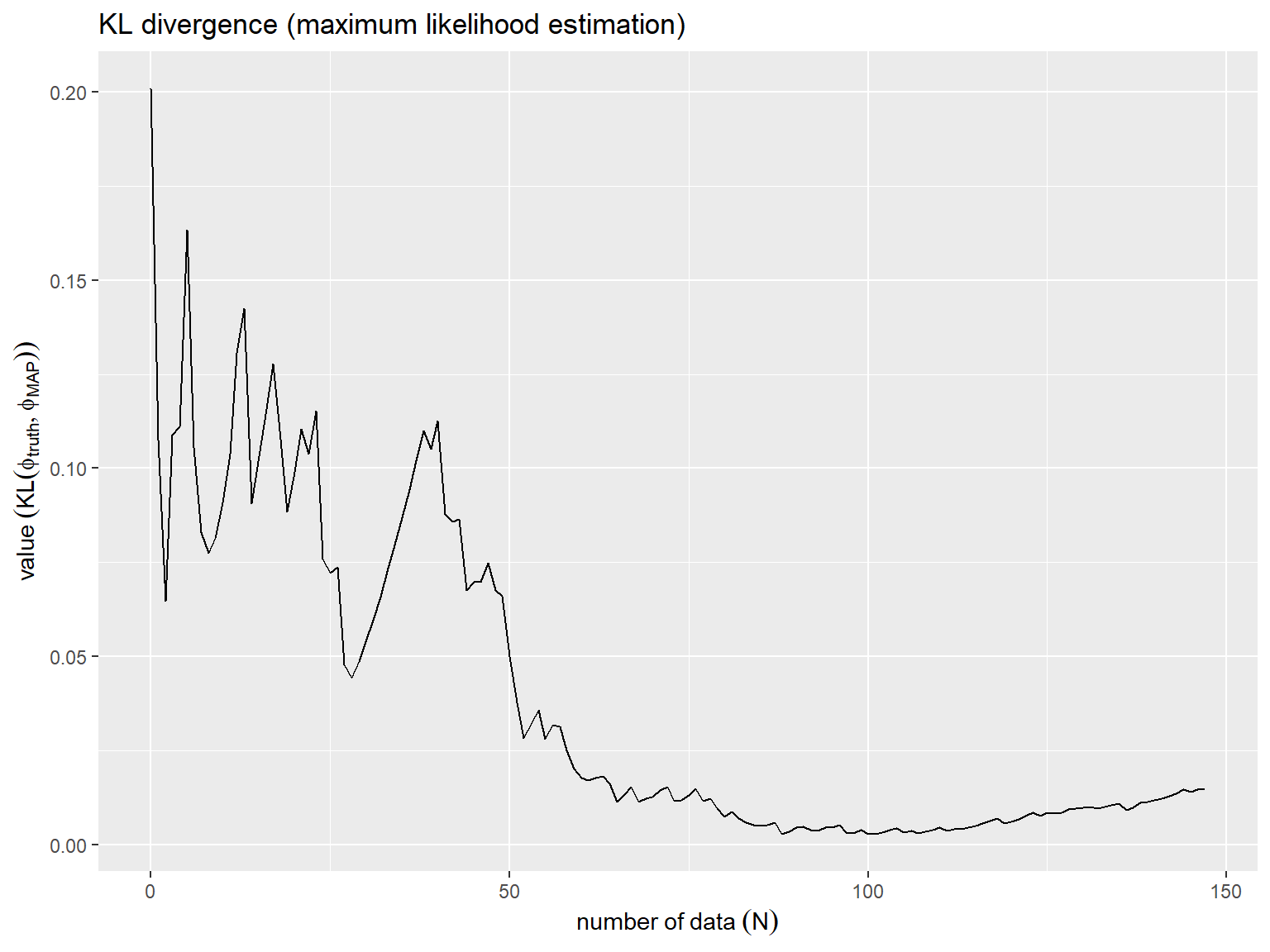
横軸はデータ数(全文書の単語数) 、縦軸は真のパラメータ
とデータ数
のときのMAP推定値
のKLダイバージェンスを表す。
この記事では、ユニグラムモデルに対するMAP推定を実装してパラメータを推定した。次の記事では、ベイズ推定によるパラメータの計算式を導出する。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
- 2024.05.21:加筆修正の際に「ユニグラムモデルのMAP推定の導出」から記事を分割しました。
前回に引き続き、実質1行の内容を膨らませて1記事になってます。
修正前は、最尤推定との比較の図も作っていたのですが意図的に落としました。本を読んでください。
【次節の内容】
- 数式読解編
ユニグラムモデルに対するベイズ推定を数式と数式で確認します。
- スクラッチ実装編
ユニグラムモデルに対するベイズ推定をプログラムで確認します。
MAP推定(ハイパーパラメータ推定)をプログラムで確認します。