はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、トピックモデル(階層混合カテゴリモデル)の生成モデルをPythonでスクラッチ実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
4.1 トピックモデルの生成モデルの実装
トピックモデル(topic model)・LDA(Latent Dirichlet Allocation・潜在的ディリクレ配分法)の生成モデル(生成過程)を実装して、簡易的な文書データ(トイデータ)を作成する。
トピックモデルについては「4.1:トピックモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
利用するライブラリを読み込む。
# 利用ライブラリ import numpy as np import matplotlib.pyplot as plt
文書データの簡易生成
まずは、トピックモデルの生成モデルに従って、文書集合に対応するデータを生成する。
真の分布や真のトピックなど本来は得られない情報についてはオブジェクト名に true を付けて表す。
パラメータの設定
文書集合に関する値を設定する。
# 文書数を指定 D = 30 # 語彙数を指定 V = 100 # トピック数を指定 true_K = 10
文書数 、語彙(単語の種類)数
、トピック数
を指定する。
トピック分布のハイパーパラメータを設定する。
# トピック分布のハイパーパラメータを指定 true_alpha = 1.0 true_alpha_k = np.repeat(true_alpha, repeats=true_K) # 一様なパラメータの場合 #true_alpha_k = np.random.uniform(low=1, high=2, size=true_K) # 多様なパラメータの場合 print(true_alpha_k[:5]) # 非負の値 print(true_alpha_k.shape) # トピック数
[1. 1. 1. 1. 1.]
(10,)
個の値(ベクトル)
を指定する。各値は0より大きい値
を満たす必要がある。全てを同じ値
とする場合は、1個の値(スカラ)
で表す。
トピック分布のパラメータを生成する。
# トピック分布のパラメータを生成 true_theta_dk = np.random.dirichlet(alpha=true_alpha_k, size=D) print(true_theta_dk[:5, :5].round(2)) # 0から1の値 print(true_theta_dk[:5].sum(axis=1)) # 総和が1の値 print(true_theta_dk.shape) # 文書数, トピック数
[[0.19 0.02 0.09 0.2 0.31]
[0.01 0.09 0.06 0.13 0.21]
[0.01 0.07 0.02 0.01 0.05]
[0.02 0.2 0.07 0.02 0.25]
[0.04 0.06 0.02 0.28 0.11]]
[1. 1. 1. 1. 1.]
(30, 10)
個のトピック分布のパラメータ
を作成する。各パラメータは
個の値(ベクトル)
であり、各値は0から1の値
で、総和が1になる値
を満たす必要がある。
ディリクレ分布の乱数は、np.random.dirichlet() で生成できる。パラメータの引数 alpha にハイパーパラメータ 、サンプルサイズの引数
size に文書数 を指定する。
単語分布のハイパーパラメータを設定する。
# 語彙分布のハイパーパラメータを指定 true_beta = 1.0 true_beta_v = np.repeat(true_beta, repeats=V) # 一様なパラメータの場合 #true_beta_v = np.random.uniform(low=1, high=2, size=V) # 多様なパラメータの場合 print(true_beta_v[:5]) # 非負の値 print(true_beta_v.shape) # 語彙数
[1. 1. 1. 1. 1.]
(100,)
個の値(ベクトル)
を指定する。各値は0より大きい値
を満たす必要がある。全てを同じ値
とする場合は、1個の値(スカラ)
で表す。
単語分布のパラメータを生成する。
# 語彙分布のパラメータを生成 true_phi_kv = np.random.dirichlet(alpha=true_beta_v, size=true_K) print(true_phi_kv[:5, :5].round(2)) # 0から1の値 print(true_phi_kv[:5].sum(axis=1)) # 総和が1の値 print(true_phi_kv.shape) # トピック数, 語彙数
[[0. 0.03 0.01 0.01 0.02]
[0.02 0.01 0. 0. 0.01]
[0.02 0. 0.04 0.01 0. ]
[0.01 0.01 0.01 0.01 0.01]
[0. 0. 0.01 0.01 0.01]]
[1. 1. 1. 1. 1.]
(10, 100)
個の単語分布(語彙分布)のパラメータ
を生成する。各パラメータは
個の値(ベクトル)
であり、各値は0から1の値
で、総和が1になる値
を満たす必要がある。
np.random.dirichlet() の alpha 引数にハイパーパラメータ 、
size 引数にトピック数 を指定する。
文書データの生成
設定したパラメータに従う文書集合を作成する。
# 文書ごとの各単語の語彙を初期化 w_dic = {} # 文書ごとの各単語のトピックを初期化 true_z_dic = {} # 各文書の単語数を初期化 N_d = np.zeros(shape=D, dtype='int') # 文書ごとの各語彙の単語数を初期化 N_dv = np.zeros(shape=(D, V), dtype='int') # 文書データを生成 for d in range(D): # 文書ごと # 単語数を生成 N_d[d] = np.random.randint(low=100, high=200, size=1) # 下限・上限を指定 # 各単語の語彙を初期化 tmp_w_n = np.repeat(np.nan, repeats=N_d[d]) # 各単語のトピックを初期化 tmp_z_n = np.repeat(np.nan, repeats=N_d[d]) for n in range(N_d[d]): # 単語ごと # トピックを生成 onehot_k = np.random.multinomial(n=1, pvals=true_theta_dk[d], size=1).reshape(true_K) # one-hot符号 k, = np.where(onehot_k == 1) # トピック番号 k = k.item() # トピックを割当 tmp_z_n[n] = k # 語彙を生成 onehot_v = np.random.multinomial(n=1, pvals=true_phi_kv[k], size=1).reshape(V) # one-hot符号 v, = np.where(onehot_v == 1) # 語彙番号 v = v.item() # 語彙を割当 tmp_w_n[n] = v # 頻度をカウント N_dv[d, v] += 1 # データを記録 w_dic[d] = tmp_w_n.astype('int').copy() true_z_dic[d] = tmp_z_n.astype('int').copy() # 途中経過を表示 print(f'document: {d+1}, words: {N_d[d]}, topics: {np.unique(true_z_dic[d])}')
document: 1, words: 192, topics: [0 1 2 3 4 5 6 7 8]
document: 2, words: 116, topics: [1 2 3 4 5 6 7 8 9]
document: 3, words: 110, topics: [0 1 2 3 4 6 7 8 9]
document: 4, words: 189, topics: [0 1 2 3 4 5 6 7 8 9]
document: 5, words: 170, topics: [0 1 2 3 4 5 6 7 8 9]
(省略)
document: 26, words: 147, topics: [0 1 2 3 4 5 6 8 9]
document: 27, words: 140, topics: [0 1 2 3 4 5 6 7 8 9]
document: 28, words: 122, topics: [0 1 2 5 6 7 8 9]
document: 29, words: 144, topics: [0 1 2 3 4 5 6 7 9]
document: 30, words: 127, topics: [0 1 2 3 4 6 7 8 9]
個の文書
について、順番に単語を生成していく。
- 文書
の単語数
をランダムに決める。この例では、上限数・下限数を指定して一様乱数を生成する。
について、順番にトピックと語彙を生成していく。
番目の単語
のトピック
に、文書
に従い、
個のトピック
からトピック番号を割り当てる。
- 割り当てられたトピック
の語彙分布(カテゴリ分布)
に従い、
個の語彙
から語彙番号を割り当てる。
- 文書
文書間で単語数が異なる(2次元配列として扱えない)ので、文書集合 とトピック集合
については、ディクショナリで扱う。
カテゴリ分布の乱数は、np.random.multinomial() で生成できる。試行回数の引数 n に 1、パラメータの引数 pvals にトピック分布 または語彙分布
、サンプルサイズの引数
size に 1 を指定する。
one-hotベクトルが生成されるので、np.where() で値が 1 の要素番号を得る。np.argmax() でも抽出できる。
または、np.random.choice() で直接番号を得られる。
文書ごとに全ての語彙で和をとると各文書の単語数に一致する。
# 単語数を確認 print(N_d[:5]) # 各文書の単語数 print(N_dv[:5].sum(axis=1)) # 各文書の単語数
[192 116 110 189 170]
[192 116 110 189 170]
データの可視化
次は、生成した文書データと真の分布のグラフを作成する。
アニメーションの作図コードについては「generative_process.py at anemptyarchive/Topic-Models-AO · GitHub」を参照のこと。
カラーマップを設定する。
# 配色の共通化用のカラーマップを作成 cmap = plt.get_cmap('tab10') # カラーマップの色数を設定:(カラーマップに応じて固定) color_num = 10
トピックごとに共通の配色をするために、カラーマップを指定して配色用のオブジェクト cmap を作成する。また、カラーマップで扱える色数を color_num とする。
この記事では、トピック番号 k に応じて色付けする。その際に、トピック番号を色数で割った整数 k % color_num を使うことで、トピック番号が色数を超える場合にカラーマップの色順でサイクルして割り当てられる。
文書データの作図
文書ごとに各トピックの割り当て単語数を集計する。
# 文書ごとの各トピックの単語数を集計 true_N_dk = np.zeros(shape=(D, true_K)) for d in range(D): for n in range(N_d[d]): k = true_z_dic[d][n] true_N_dk[d, k] += 1 print(true_N_dk[:5, :5])
[[48. 4. 17. 39. 56.]
[ 0. 10. 6. 15. 21.]
[ 1. 10. 1. 3. 7.]
[ 3. 36. 21. 4. 37.]
[ 6. 14. 8. 53. 22.]]
各単語に割り当てられたトピック からトピック番号
を取り出して、文書ごとの各トピックの単語数
をカウントする(対応する要素に
1 を加えていく)。
文書ごとに全てのトピックで和をとると各文書の単語数に一致する。
# 単語数を確認 print(N_d[:5]) # 各文書の単語数 print(true_N_dk[:5].sum(axis=1)) # 各文書の単語数
[192 116 110 189 170]
[192. 116. 110. 189. 170.]
描画する文書の数を指定して、文書データのグラフを作成する。
# 描画する文書数を指定 #doc_num = D doc_num = 5 # グラフサイズを設定 u = 5 axis_Ndv_max = (np.ceil(N_dv[:doc_num].max() /u)*u).astype('int') # u単位で切り上げ axis_Ndk_max = (np.ceil(true_N_dk[:doc_num].max() /u)*u).astype('int') # u単位で切り上げ # 文書データを作図 fig, axes = plt.subplots(nrows=doc_num, ncols=2, constrained_layout=True, figsize=(20, 25), dpi=100, facecolor='white') for d in range(doc_num): # 各語彙の単語数を集計・各単語のトピックを格納 tmp_z_mv = np.tile(np.nan, reps=(axis_Ndv_max, V)) for n in range(N_d[d]): v = w_dic[d][n] m = np.sum(w_dic[d][:n+1] == v) k = true_z_dic[d][n] tmp_z_mv[m-1, v] = k % color_num # (配色の共通化用) # 単語データを描画 ax = axes[d, 0] ax.pcolor(tmp_z_mv, cmap=cmap, vmin=0, vmax=color_num-1) # 頻度・トピック ax.set_xlabel('vocabulary ($v$)') ax.set_ylabel('frequency ($N_{dv}$)') ax.set_title(f'$d = {d+1}, N_d = {N_d[d]}$', loc='left') ax.grid() # 語彙の出現順を描画 for n in range(N_d[d]): v = w_dic[d][n] m = np.sum(w_dic[d][:n+1] == v) ax.text(x=v+0.5, y=m-0.5, s=str(n+1), size=5, ha='center', va='center') # 単語番号 # トピックの割当を描画 ax = axes[d, 1] ax.bar(x=np.arange(stop=true_K)+1, height=true_N_dk[d], color=[cmap(k%color_num) for k in range(true_K)]) # 単語数 ax.set_ylim(ymin=0, ymax=axis_Ndk_max) ax.set_xlabel('topic ($k$)') ax.set_ylabel('frequency ($N_{dk}$)') ax.set_title(f'$d = {d+1}, N_d = {N_d[d]}$', loc='left') ax.grid() fig.supylabel('document ($d$)') fig.suptitle('document data (true topic)', fontsize=20) plt.show()
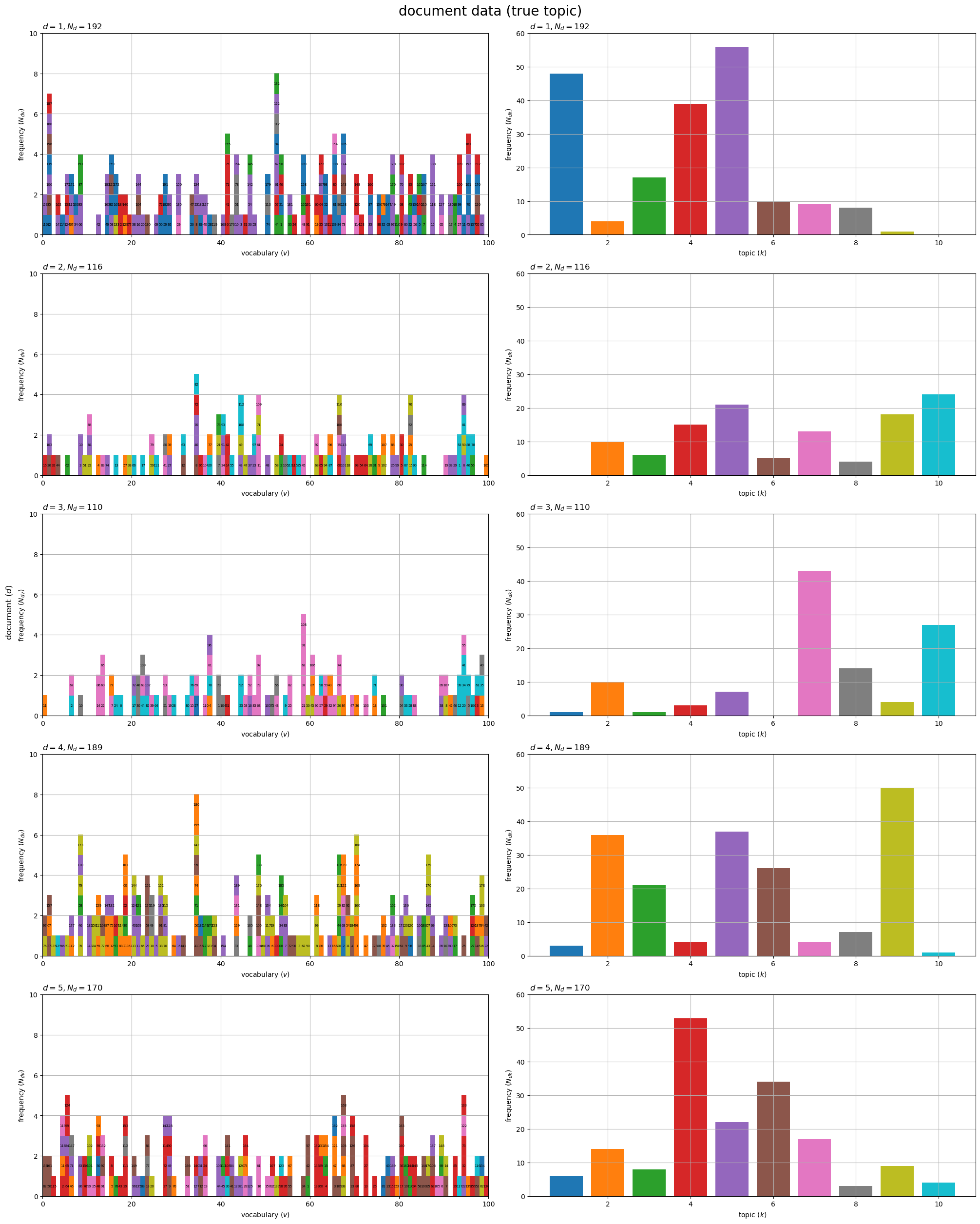
文書ごとにグラフを縦に並べて描画する。
左図は、各語彙の出現回数 を棒グラフで表す。ただし、ヒートマップを使って棒グラフを再現している。各タイルが単語
を表し、割り当てられたトピック
で色付けする。対応する単語がないタイルの要素(位置)に
nan を格納しておくと表示されない。
タイル上のラベルは単語番号(出現順) を示している。トピック番号なども表示できる。
各グラフの値(バーの高さ)の総和は、それぞれの文書の単語数 になる。
右図は、各トピックが割り当てられた単語数 を棒グラフで表す。
こちらも総和は単語数になる。
データ数が増えると、右図はトピック分布、左図はトピック分布による単語分布の混合分布の形状に近付く。
真の分布の作図
描画する文書の数を指定して、文書ごとにトピック分布のグラフを作成する。
# 描画する文書数を指定 #doc_num = D doc_num = 9 # グラフサイズを設定 u = 0.1 axis_size = np.ceil(true_theta_dk[:doc_num].max() /u)*u # u単位で切り上げ # サブプロットの列数を指定:(1 < 列数 < D) col_num = 3 # サブプロットの行数を計算:(1行or1列だとエラー) row_num = np.ceil(doc_num / col_num).astype('int') # トピック分布を作図 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(24, 18), dpi=100, facecolor='white') for d in range(doc_num): # サブプロットのインデックスを計算 r = d // col_num c = d % col_num # サブプロットを抽出 ax = axes[r, c] # トピック分布を描画 ax.bar(x=np.arange(stop=true_K)+1, height=true_theta_dk[d], color=[cmap(k%color_num) for k in range(true_K)]) # 確率 ax.set_ylim(ymin=0, ymax=axis_size) ax.set_xlabel('topic ($k$)') ax.set_ylabel('probability ($\\theta_{dk}$)') ax.set_title(f'$d = {d+1}, \\alpha = {true_alpha}$', loc='left') # (一様パラメータ用) #ax.set_title('$d = {}, \\alpha_k = ({})$'.format(d+1, ', '.join([str(val.round(2)) for val in true_alpha_k])), loc='left') # (多様パラメータ用) ax.grid() # 残りのサブプロットを非表示 for c in range(c+1, col_num): axes[r, c].axis('off') fig.supxlabel('document ($d$)') fig.supylabel('document ($d$)') fig.suptitle('topic distribution (truth)', fontsize=20) plt.show()
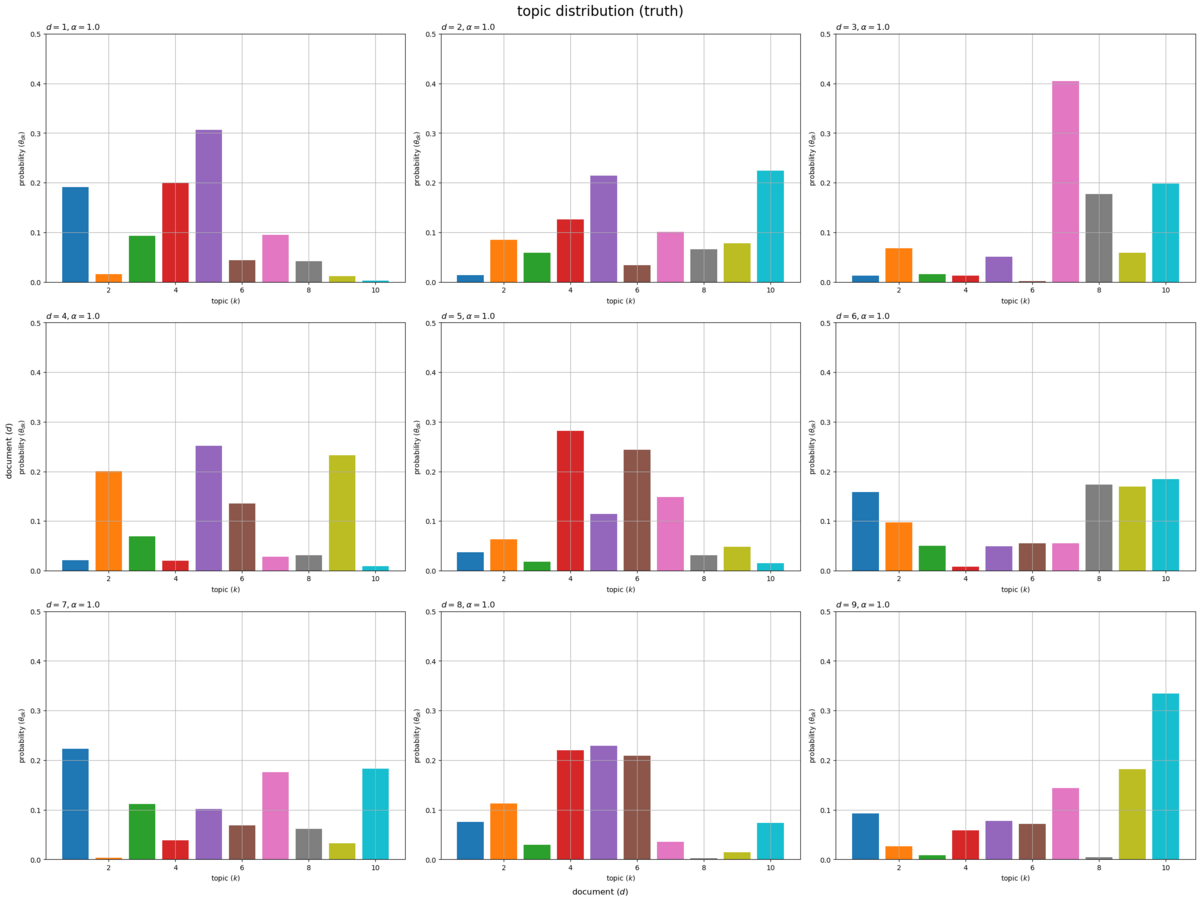
文書ごとのトピック分布 をそれぞれ棒グラフとして縦横に並べて描画する。各文書における各トピックの割り当て確率
がバーに対応する。
各グラフの値(バーの高さ)の総和が1になる。
描画するトピックの数を指定して、単語分布のグラフを作成する。
# 描画するトピック数を指定 topic_num = true_K #topic_num = 9 # グラフサイズを設定 u = 0.01 axis_size = np.ceil(true_phi_kv[:topic_num].max() /u)*u # u単位で切り上げ # サブプロットの列数を指定:(1 < 列数 < K) col_num = 3 # サブプロットの行数を計算:(1行or1列だとエラー) row_num = np.ceil(topic_num / col_num).astype('int') # 語彙分布を作図 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(30, 20), dpi=100, facecolor='white') for k in range(topic_num): # サブプロットのインデックスを計算 r = k // col_num c = k % col_num # サブプロットを抽出 ax = axes[r, c] # 語彙分布を描画 ax.bar(x=np.arange(stop=V)+1, height=true_phi_kv[k], color=cmap(k%color_num)) # 確率 ax.set_ylim(ymin=0, ymax=axis_size) ax.set_xlabel('vocabulary ($v$)') ax.set_ylabel('probability ($\phi_{kv}$)') ax.set_title(f'$k = {k+1}, \\beta = {true_beta}$', loc='left') # (一様パラメータ用) #ax.set_title('$k = {}, \\beta_v = ({}, ...)$'.format(k+1, ', '.join([str(true_beta_v[v].round(2)) for v in range(5)])), loc='left') # (多様パラメータ用) ax.grid() # 残りのサブプロットを非表示 for c in range(c+1, col_num): axes[r, c].axis('off') fig.supxlabel('topic ($k$)') fig.supylabel('topic ($k$)') fig.suptitle('word distribution (truth)', fontsize=20) plt.show()
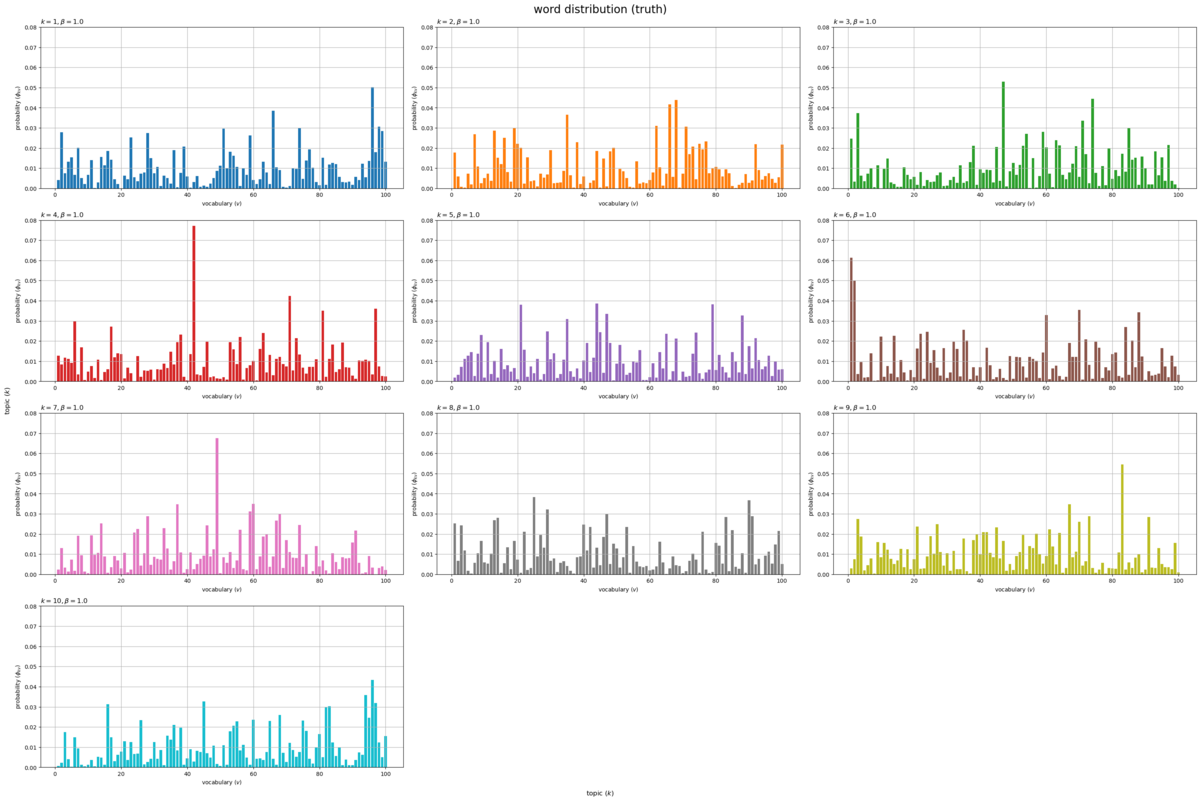
トピックごとの単語分布(語彙分布) をそれぞれ棒グラフとして縦横に並べて描画する。各トピックにおける各語彙の出現確率
がバーに対応する。
各グラフの値(バーの高さ)の総和が1になる。
この記事ではトピックモデルの生成モデルを実装して、各種アルゴリズムに用いる人工データを作成した。次からの記事では、推論処理を実装する。
参考書籍
")
おわりに
青トピ本シリーズのPython版をやっていきます。緑ベイズ本をPythonで組んでからずっとトピックモデルもPythonで組みたいと思いつつ手を付けられなかったのですが、先日LDAについて質問が来たことをきっかけにやり手を出し始めました。
ユニグラムモデルも全部実装するつもりですが、Rでも書いていなかったトピックモデルの生成モデルから記事を書きました。実装自体は既にいくつか書き殴っています。特に可視化を充実させたいとアレコレ図を作っています。図が増えて文量が増えすぎたので、生成モデルだけの記事に独立させる必要があったという事情もあります。他の節の記事が書き進めば、この記事をすぐ書き直すことになるんだろうなー。
R版を書いていたころは(分析というわけではないですが)歌詞データを使っていたので、トイデータの必要性というか存在を知らず、生成モデル(生成過程)を組もうという発想がなかったです。緑ベイズ本を読んでた頃に気付いたんだと思います。
復習のつもりで実装し始めたのですが、試行錯誤しているうちにR版のギブスサンプリングの実装と理論の理解でそれぞれ大きく間違っていることに気付きました。いやー実装については当時から怪しいなと思ってはいたのですが、検証手段がなくヨシとしたところがやっぱりおかしかったです。人工データや真の分布で確かめるのは重要ですね。
それとは別にたしか去年、n周目の全面加筆修正作業を進めていて3章の途中でぱったり止まって1年が経ったような気がします。どの道さっさと書き直さないといけなかったのですが、この度さらに風呂敷を広げることになりました。さてどうなることやら。
なんやかや言ってもやっぱりトピックモデルは楽しいなー!
2024年3月20日は、エビ中こと私立恵比寿中学の小久保柚乃さんの17歳のお誕生日です。
ゆのぴをきっかけにエビ中にハマって1年が過ぎ、先月FCに入りました。春ツアーのチケットも取れました。私にとって1年半近く振りのライブかつエビ中の初単独ライブが楽しみな今日この頃です。
【次節の内容】
- スクラッチ実装編
書けてない。
- 数式読解編
トピックモデルに対する最尤推定を数式で確認します。