はじめに
『ベイズ推論による機械学習入門』の学習時のノートです。基本的な内容は「数式の行間を読んでみた」とそれを「Rで組んでみた」になります。「数式」と「プログラム」から理解するのが目標です。
この記事は、3.5節の内容です。線形回帰モデルの「観測モデルを1次元ガウス分布(1次元正規分布)」、「事前分布を多次元ガウス分布(多変量正規分布)」とした場合の「パラメータの事後分布」と「未観測値の予測分布」の計算をPythonで実装します。
省略してある内容等ありますので、本とあわせて読んでください。初学者な自分が理解できるレベルまで落として書き下していますので、分かる人にはかなりくどくなっています。同じような立場の人のお役に立てれば幸いです。
【数式読解編】
【他の節一覧】
【この節の内容】
・Pythonでやってみよう
人工的に生成したデータを用いて、ベイズ推論を行ってみましょう。
利用するパッケージを読み込みます。
# 3.5節で利用ライブラリ import numpy as np import matplotlib.pyplot as plt
・観測モデルの設定
この例では、ある入力$x_n$を$\mathbf{x}_n = (1, x_n, x_n^2, \cdots, x_n^{M-1})$とした$M$次元ベクトルを入力値として用いて、$y_n$を出力します。
そこでまずは、$x_n$から$\mathbf{x}_n$を作成する関数を定義しておきます。
# {x^(m-1)}ベクトル作成関数を定義 def x_vector(x_n, M): # 受け皿を作成 x_nm = np.zeros(shape=(len(x_n), M)) # m乗を計算 for m in range(M): x_nm[:, m] = np.power(x_n, m) return x_nm
$x^0 = 1$であることを利用して、$m$番目(列目)の項を$x_n^{m-1}$で計算します。(第1引数がスカラだとlen()がエラーになるので、(1, 1)の配列にする必要があります。)
$N$個のデータ$\{x_1, x_2, \cdots, x_N\}$の場合は、それぞれ$M$次元にした$N \times M$の行列
として扱うことにします((M, N)の配列とした方が実装(内積の処理)が楽ですが、これまでの章での扱いと合わせます。多くの計算で.Tで転置することになります)。
試しに、1から5の値をx_vector()で4次元ベクトルにしてみます。
# 確認 print(x_vector(np.arange(1, 5), 4))
[[ 1. 1. 1. 1.]
[ 1. 2. 4. 8.]
[ 1. 3. 9. 27.]
[ 1. 4. 16. 64.]]
1列目は全て1になり、2列目が元の値です。
続いて、真のモデルを確認していきます。
入力$\mathbf{x} = (1, x, x^2, \cdots, x^{M-1})$とパラメータ$\mathbf{w} = (w_1, w_2, \cdots, w_M)$の内積(重み付き和)
を真のモデルとします。
実際に計算して、グラフで確認しましょう。
観測モデルのパラメータ$\mathbf{w}$を設定します。
# 真の次元数を指定 M_truth = 4 # 真のパラメータを生成 w_truth_m = np.random.choice( np.arange(-1.0, 1.0, step=0.1), size=M_truth, replace=True ) # 確認 print(w_truth_m)
[-0.5 -0.8 0.3 0.2]
この例では、真のパラメータの次元数をM_truthとして値を指定して、$\mathbf{w}$の値を-1から1の範囲でランダムに生成することにします。作成した真のパラメータをw_truth_mとします。
作図用に、$x_n$がとり得る値を作成します。
# 作図用のx軸の値を作成 x_line = np.arange(-3.0, 3.0, step=0.01) # 作図用のxをM次元に拡張 x_truth_arr = x_vector(x_line, M_truth)
$x_n$がとり得る値(x軸の値)をnp.arange()で作成してx_lineとします。この例では、-3から3の範囲をグラフにすることにします(範囲を広くすると$x_n^{M-1}$の影響が強くなり、パラメータに関わらず似た形のグラフになってつまんないです)。
また、x_lineの各要素をx_vector()でM_truth次元ベクトルに変換してx_truth_arrとします。
# 確認 print(x_truth_arr[:5])
[[ 1. -3. 9. -27. ]
[ 1. -2.99 8.9401 -26.730899]
[ 1. -2.98 8.8804 -26.463592]
[ 1. -2.97 8.8209 -26.198073]
[ 1. -2.96 8.7616 -25.934336]]
2列目がx_lineの要素ですね。
真のモデルの出力を計算します。
# 真のモデルの出力を計算 y_line = np.dot(w_truth_m.reshape((1, M_truth)), x_truth_arr.T).flatten() # 確認 print(np.round(y_line[:5], 2))
[-0.8 -0.77 -0.74 -0.72 -0.69]
真のモデルを作図します。
# 真のモデルを作図 fig = plt.figure(figsize=(12, 9)) plt.plot(x_line, y_line) # 真のモデル plt.suptitle('Observation Model', fontsize=20) plt.title('w=[' + ', '.join([str(w) for w in np.round(w_truth_m, 2).flatten()]) + ']', loc='left', fontsize=20) plt.xlabel('x') plt.ylabel('y') plt.grid() # グリッド線 plt.show()
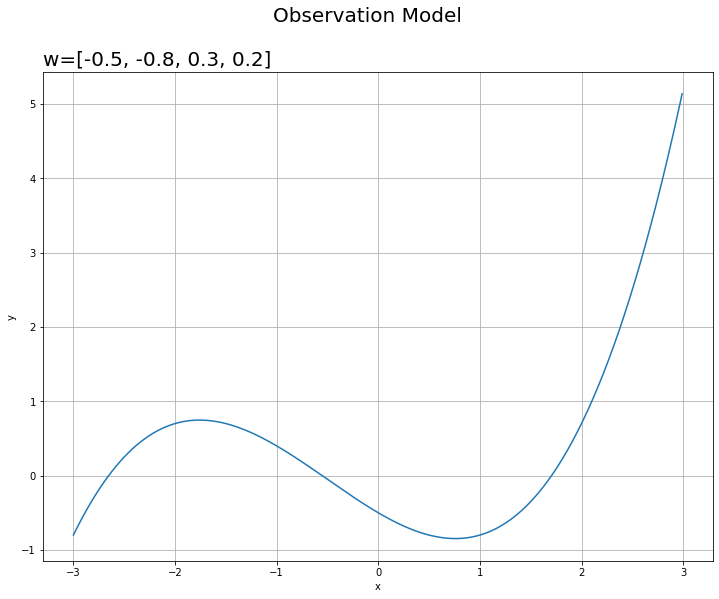
これがノイズを含めない観測モデルです。
・データの生成
実際に観測される出力値$y_n$にはノイズ成分$\epsilon_n$が含まれているとします。
ノイズ成分は、平均$0$、分散$\sigma^2 = \lambda^{-1}$の1次元のガウス分布に従うと仮定します。分散の逆数$\lambda = \frac{1}{\sigma^2}$を精度と呼びます。
ノイズ成分のパラメータを設定します。
# ノイズ成分の標準偏差を指定 sigma = 1.5 # ノイズ成分の精度を計算 lmd = 1.0 / sigma**2 # 確認 print(lmd)
0.4444444444444444
1次元ガウス分布の標準偏差$\sigma$をsigmaとして値を指定し、精度を計算してlmdとします(lambdaは予約語で使えないので)。これは作図時に標準偏差を利用するためです。
試しに、ノイズ成分を1つ生成してみます。
# ノイズ成分を1つ生成 print(np.random.normal(loc=0.0, scale=np.sqrt(1 / lmd), size=1))
[0.15750895]
1次元ガウス分布に従う乱数は、np.random.normal()で生成できます。データ数の引数sizeにはデータ数、平均の引数locに0、標準偏差の引数scaleにnp.sqrt(1 / lmd))を指定します。精度$\lambda$を標準偏差$\sigma = \sqrt{\frac{1}{\lambda}}$に戻しています(勿論sigmaを指定すればいいのですが、式(3.142)に合わせておきます)。
以上で観測モデルのパラメータを設定できたので、入力値$\mathbf{X}$を作成して、出力値$\mathbf{y} = \{y_1, y_2, \cdots, y_N\}$を求めます。
$N$個の入力値を生成します。
# (観測)データ数を指定 N = 50 # 入力値を生成 x_n = np.random.choice( np.arange(min(x_line), max(x_line), step=0.01), size=N, replace=True ) # 入力値をM次元に拡張 x_truth_nm = x_vector(x_n, M_truth)
生成するデータ数$N$をNとして値を指定します。
データの生成に関して分布の仮定をおいていないため、np.random.choice()で一様な確率に従いランダムに値を生成します。ただし$x_n$がとり得る範囲は、グラフの描画範囲x_lineにしておきます。生成したN個のデータをx_nとします。
また、x_nの各要素をx_vector()でM_truth次元ベクトルに変換してx_truth_nmとします。
1次元ガウス分布に従う$N$個のノイズ成分を生成して、出力値$\mathbf{y}$を計算します。
# ノイズ成分を生成 epsilon_n = np.random.normal(loc=0.0, scale=np.sqrt(1 / lmd), size=N) # 出力値を計算:式(3.141) y_n = np.dot(w_truth_m.reshape((1, M_truth)), x_truth_nm.T).flatten() + epsilon_n # 確認 print(np.round(y_n[:5], 2))
[-0.76 0.16 -1.1 0.14 2.22]
観測モデル(3.141)に従い、出力値$\mathbf{y}$を計算してy_nとします。
観測データの散布図を真のモデルのグラフと重ねて確認します。
# 観測データの散布図を作成 fig = plt.figure(figsize=(12, 9)) plt.scatter(x_n, y_n) # 観測データ plt.plot(x_line, y_line) # 真のモデル plt.suptitle('Observation Data', fontsize=20) plt.title('$N=' + str(N) + ', w=[' + ', '.join([str(w) for w in np.round(w_truth_m, 2).flatten()]) + ']' + ', \lambda=' + str(np.round(lmd, 2)) + '$', loc='left', fontsize=20) plt.xlabel('x') plt.ylabel('y') plt.grid() # グリッド線 plt.show()
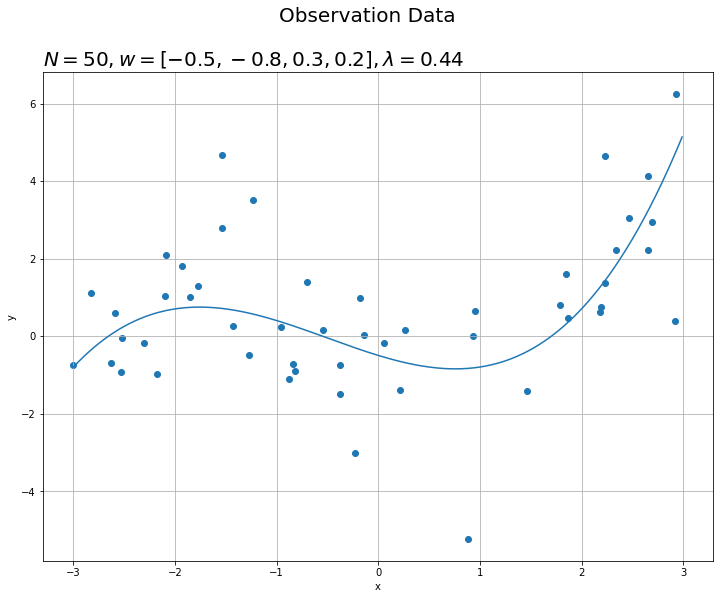
'w'の要素数が真の次元数$M$を表します。
以上が観測モデルに関する処理です。
・事前分布の設定
次に、観測モデルのパラメータ$\mathbf{w}$の事前分布$p(\mathbf{w})$として、多次元ガウス分布$\mathcal{N}(\mathbf{w} | \mathbf{m}, \boldsymbol{\Lambda}^{-1})$を設定します。
$\mathbf{w}$の事前分布のパラメータ(超パラメータ)を設定します。
# 事前分布の次元数を指定 M = 5 # 事前分布の平均を指定 m_m = np.zeros(M) # 事前分布の精度行列を指定 sigma_mm = np.identity(M) * 10 lambda_mm = np.linalg.inv(sigma_mm**2) # 確認 print(lambda_mm)
[[ 0.01 0. 0. 0. 0. ]
[ 0. 0.01 0. 0. 0. ]
[ 0. 0. 0.01 0. 0. ]
[-0. -0. -0. 0.01 -0. ]
[ 0. 0. 0. 0. 0.01]]
事前分布の次元数$M$をMとして値を指定します。(ところで入力値は$x_n$と$\mathbf{x}_n$のどちらの状態で得られるものなのでしょうかね。$M$次元ベクトル$\mathbf{x}_n$が手元にある場合は、真の$M$を事前分布の次元数とします。この例では、真の次元数が分からない$x_n$しか手元にないものとして、任意の値を指定することにします。)
多次元ガウス分布の平均パラメータ$\mathbf{m} = (m_1, \cdots, m_M)$をm\_m、標準偏差$\sigma_{i,i}$と相関係数$\sigma_{i,j}$の行列$(\sigma_{1,1}, \cdots, \sigma_{M,M})$をsigma_mmとして値を指定します。sigma_mmから分散共分散行列$\boldsymbol{\Sigma} = (\sigma_{1,1}^2, \cdots, \sigma_{M,M}^2)$の逆行列である精度行列(精度パラメータ)$\boldsymbol{\Lambda} = \boldsymbol{\Sigma}^{-1}$を計算してlambda_mmとします。逆行列はnp.linalg.inv()で計算します。lambda_mmを直接指定してもかまいません。np.identity()は単位行列を作成する関数です。
また、入力値に関するデータx_n, x_lineをM次元ベクトルに変換します。
# 入力値をM次元に拡張 x_nm = x_vector(x_n, M) # 作図用のxをM次元に拡張 x_arr = x_vector(x_line, M)
それぞれx_nm, x_arrとします。
事前分布から$\mathbf{w}$をサンプリングしたモデルを確認しましょう。
# サンプリング数を指定 smp_size = 5 # 事前分布からサンプリングしたwを用いたモデルを比較 prior_list = [] for i in range(smp_size): # パラメータを生成 prior_w_m = np.random.multivariate_normal( mean=m_m, cov=np.linalg.inv(lambda_mm), size=1 ) # 出力値を計算:式(3.141) tmp_y_line = np.dot(prior_w_m.reshape((1, M)), x_arr.T).flatten() # 結果を格納 prior_list.append(list(tmp_y_line))
真のパラメータはnp.random.choice()で生成しましたが、事前分布からのサンプリングでは仮定した$M$次元ガウス分布から生成します。多次元ガウス分布に従う乱数は、np.random.multivariate_normal()で生成できます。平均の引数meanにm_m、分散共分散行列の引数covにnp.linalg.inv(lambda_mm)、データ数の引数sizeに1を指定します。
生成したパラメータprior_w_mを用いて出力を計算して、append()でリストに格納します。
サンプリングした$\mathbf{w}$を用いたモデルを作図します。
# 事前分布からサンプリングしたパラメータによるモデルを作図 fig = plt.figure(figsize=(12, 9)) for i in range(smp_size): plt.plot(x_line, prior_list[i], label='smp:' + str(i+1)) # サンプリングしたwを用いたモデル plt.plot(x_line, y_line, color='blue', linestyle='dashed', label='model') # 真のモデル plt.suptitle('Sampling from Prior Distribution', fontsize=20) plt.title('m=[' + ', '.join([str(m) for m in m_m]) + ']', loc='left', fontsize=20) plt.xlabel('x') plt.ylabel('y') plt.ylim((min(y_line) - 3 * sigma, max(y_line) + 3 * sigma)) # y軸の表示範囲 plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
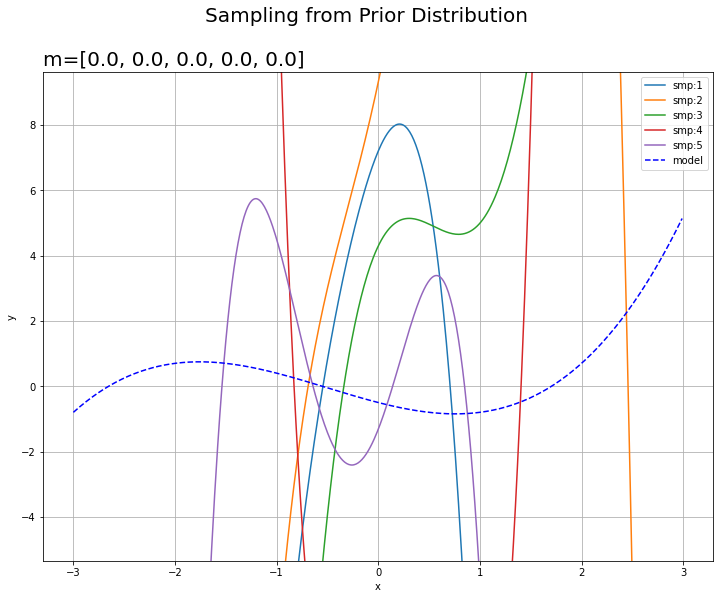
この時点では当然観測モデルとは程遠いグラフになります。'm'の要素数が事前分布の次元数$M$を表します。
・事後分布の計算
観測データ$\mathbf{y},\ \mathbf{X}$からパラメータ$\mathbf{w}$の事後分布$p(\mathbf{w} | \mathbf{y}, \mathbf{X})$を求めます(パラメータ$\mathbf{w}$を分布推定します)。事後分布は多次元ガウス分布$\mathcal{N}(\mathbf{w} | \hat{\mathbf{m}}, \hat{\boldsymbol{\Lambda}}^{-1})$になります。
観測データy_n、x_nmを用いて、$\mathbf{w}$の事後分布のパラメータを計算します。
# 事後分布のパラメータを計算:式(3.148) lambda_hat_mm = lmd * np.dot(x_nm.T, x_nm) + lambda_mm term_m_m = lmd * np.dot(y_n.reshape((1, N)), x_nm).T term_m_m += np.dot(lambda_mm, m_m.reshape((M, 1))) m_hat_m = np.dot(np.linalg.inv(lambda_hat_mm), term_m_m).flatten()
事後分布パラメータを
を計算して、結果をlambda_hat_mm、m_hat_mとします。ただし効率よく処理するために、$\sum_{n=1}^N \mathbf{x}_n \mathbf{x}_n^{\top}$の計算を$\mathbf{X}^{\top} \mathbf{X}$で、$\sum_{n=1}^N y_n \mathbf{x}_n$の計算を$\mathbf{y} \mathbf{X}$で計算しています。
# 確認 print(np.round(lambda_hat_mm, 2)) print(np.round(m_hat_m, 2))
[[ 2.223000e+01 -2.510000e+00 7.603000e+01 2.980000e+00 4.301900e+02]
[-2.510000e+00 7.604000e+01 2.980000e+00 4.301900e+02 4.821000e+01]
[ 7.603000e+01 2.980000e+00 4.302000e+02 4.821000e+01 2.798190e+03]
[ 2.980000e+00 4.301900e+02 4.821000e+01 2.798200e+03 3.921800e+02]
[ 4.301900e+02 4.821000e+01 2.798190e+03 3.921800e+02 1.962731e+04]]
[-0.89 -0.87 0.75 0.2 -0.06]
事後分布からも$\mathbf{w}$をサンプリングしてモデルを確認しましょう。
# 事後分布からサンプリングしたwを用いたモデルを比較 posterior_list = [] for i in range(smp_size): # パラメータを生成 posterior_w_m = np.random.multivariate_normal( mean=m_hat_m, cov=np.linalg.inv(lambda_hat_mm), size=1 ) # 出力値を計算:式(3.141) tmp_y_line = np.dot(posterior_w_m.reshape((1, M)), x_arr.T).flatten() # 結果を格納 posterior_list.append(list(tmp_y_line))
更新した超パラメータm_m, lambda_hat_mmを用いて、事前分布のときと同様に処理します。
サンプリングした$\mathbf{w}$を用いたモデルを作図します。
# 事後分布からサンプリングしたパラメータによるモデルを作図 fig = plt.figure(figsize=(12, 9)) for i in range(smp_size): plt.plot(x_line, posterior_list[i], label='smp' + str(i+1)) # サンプリングしたwを用いたモデル plt.plot(x_line, y_line, color='blue', linestyle='dashed', label='model') # 真のモデル plt.scatter(x_n, y_n) # 観測データ plt.suptitle('Sampling from Posterior Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \hat{m}=[' + ', '.join([str(m) for m in np.round(m_hat_m, 2)]) + ']$', loc='left', fontsize=20) plt.xlabel('x') plt.ylabel('y') plt.ylim((min(y_line) - 3 * sigma, max(y_line) + 3 * sigma)) # y軸の表示範囲 plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
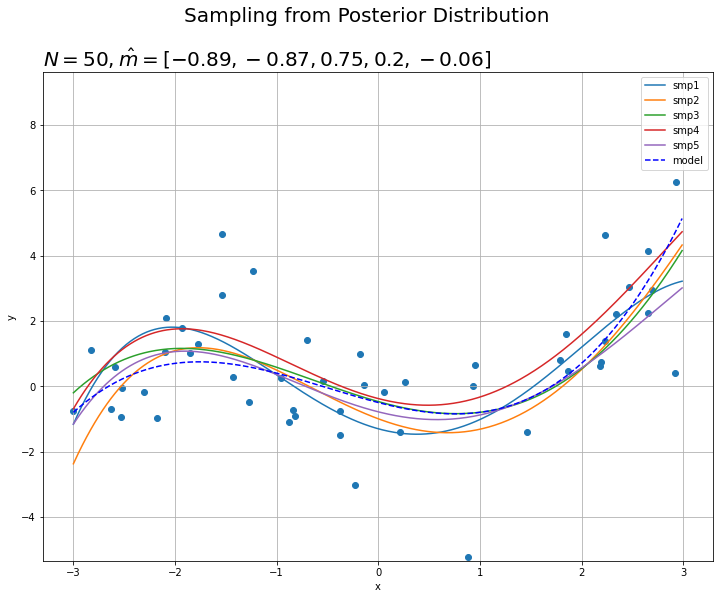
真のモデルに近い形になっているのを確認できます。
パラメータ$\mathbf{w}$の期待値($\mathbf{w}$の事後分布の期待値)$\mathbb{E}[\mathbf{w}]$を確認しましょう。
# 真のパラメータを確認 print(w_truth_m) # パラメータの期待値を確認 print(np.round(m_hat_m, 2))
[-0.5 -0.8 0.3 0.2]
[-0.89 -0.87 0.75 0.2 -0.06]
パラメータの期待値は多次元ガウス分布の期待値(2.76)より、$\mathbb{E}[\mathbf{w}] = \hat{\mathbf{m}}$です。
真のパラメータw_truth_mとパラメータの期待値m_hat_mを比べると、真の値に近い値を推定できているのが分かります。真のパラメータにはない5次元目についても0に近い値になっています。
・予測分布の計算
最後に、観測データ$\mathbf{y},\ \mathbf{X}$と新規の入力値$\mathbf{x}_{*}$から未観測値$y_{*}$の予測分布$p(y_{*} | \mathbf{x}_{*}, \mathbf{y}, \mathbf{X})$を求めます。予測分布は1次元ガウス分布$\mathcal{N}(y_{*} | \hat{\mu}_{*}, \hat{\lambda}_{*})$になります。
$\mathbf{w}$の事後分布パラメータを用いて、予測分布のパラメータを計算します。
# 予測分布のパラメータを計算:式(3.155') mu_star_hat_line = np.dot(m_hat_m.reshape((1, M)), x_arr.T).flatten() sigma2_star_hat_line = np.diag( x_arr.dot(np.linalg.inv(lambda_hat_mm)).dot(x_arr.T) ) + 1 / lmd
x_lineの要素ごとに、予測分布パラメータ
を計算します。
入力(x軸)の各値に対する出力(y軸)の平均$\hat{\mu}_{*}$をmu_star_hat_lineとします。$\hat{\mu}_{*}$の計算式を見ると、真のパラメータ$\mathbf{w}$の代わりにパラメータの期待値$\mathbb{E}[\mathbf{w}] = \hat{\mathbf{m}}$を用いて、ノイズのない出力の計算$\mathbb{E}[\mathbf{w}]^{\top} \mathbf{x}_{*}$をしているのが分かります。また1次元ガウス分布の期待値(2.66)より、出力の期待値$\mathbb{E}[y_{*}] = \hat{\mu}_{*}$なので、$\mathbf{w}$の期待値を用いて$y_{*}$の期待値を求めています。
また、精度の逆数は分散$\hat{\sigma}_{*}^2 = \hat{\lambda}_{*}^{-1}$なのでsigma2_star_hat_lineとします。
# 確認 print(np.round(mu_star_hat_line[:5], 2)) print(np.round(sigma2_star_hat_line[:5], 2))
[-1.54 -1.48 -1.42 -1.36 -1.3 ]
[3.25 3.21 3.17 3.14 3.1 ]
予測分布を真のモデルと重ねて作図します。
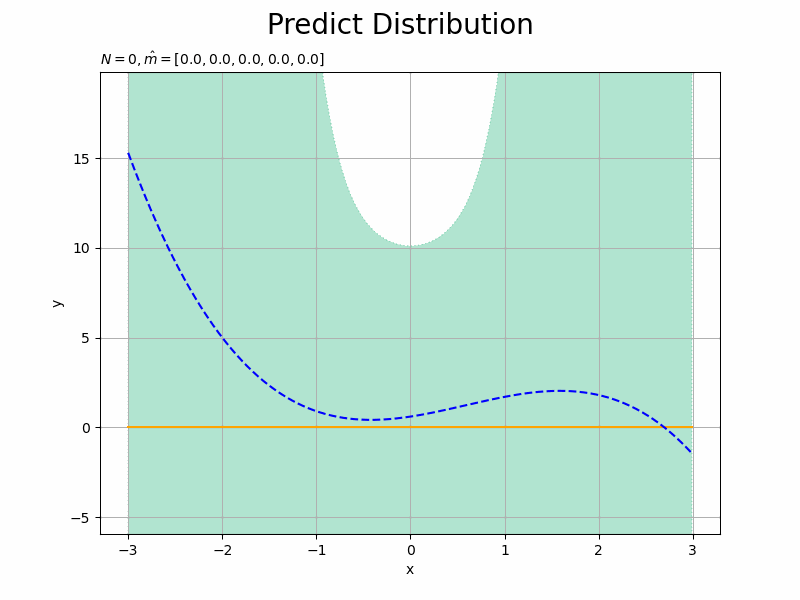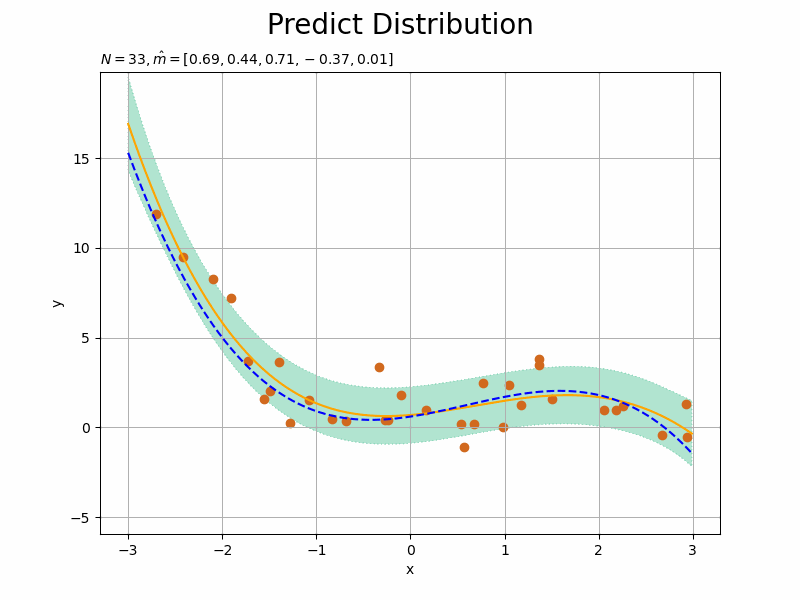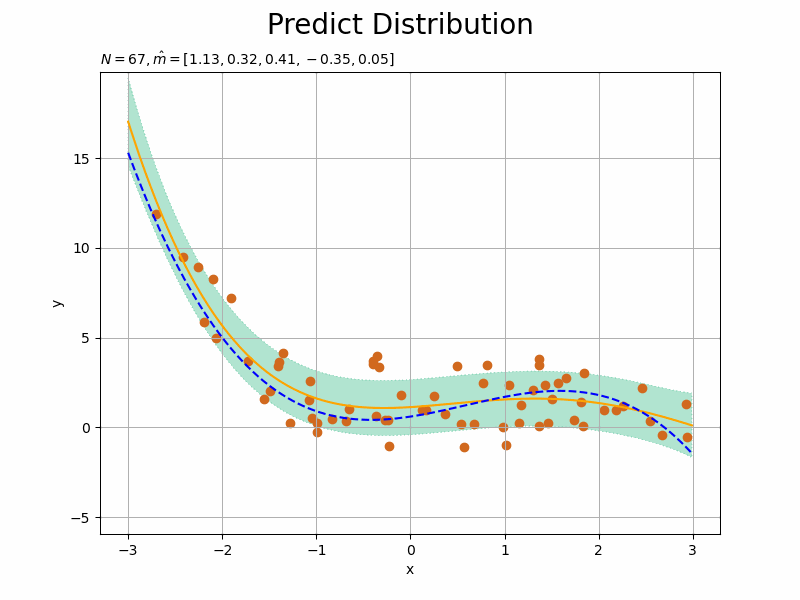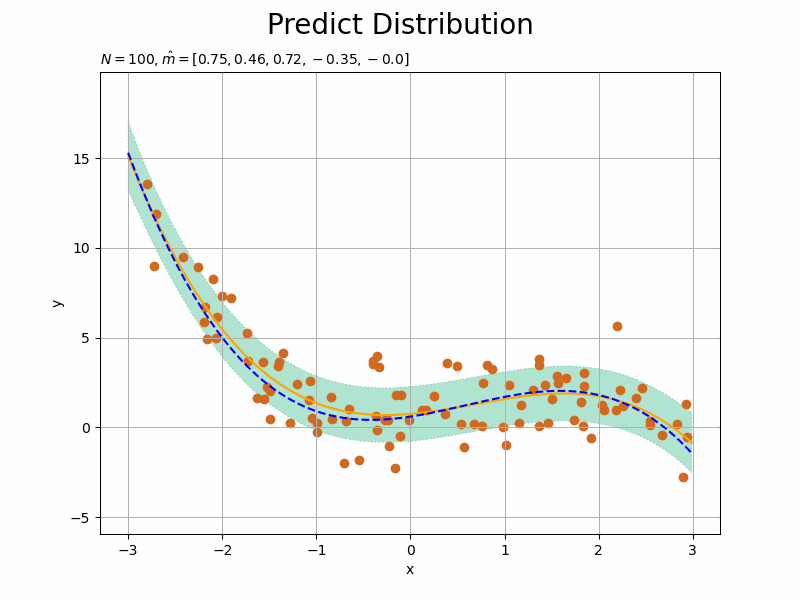
# 予測分布を作図 fig = plt.figure(figsize=(12, 9)) plt.plot(x_line, mu_star_hat_line, color='orange', label='predict') # 予測分布の期待値 plt.fill_between(x=x_line, y1=mu_star_hat_line - np.sqrt(sigma2_star_hat_line), y2=mu_star_hat_line + np.sqrt(sigma2_star_hat_line), color='#00A968', alpha=0.3, linestyle='dotted', label='$\mu \pm \sigma$') # 予測分布の標準偏差 plt.plot(x_line, y_line, linestyle='dashed', color='blue', label='model') # 真のモデル plt.scatter(x_n, y_n, color='chocolate') # 観測データ plt.suptitle('Predict Distribution', fontsize=20) plt.title('$N=' + str(N) + ', \hat{m}=[' + ', '.join([str(m) for m in np.round(m_hat_m, 2)]) + ']$', loc='left', fontsize=20) plt.xlabel('x') plt.ylabel('y') plt.ylim((min(y_line) - 3 * sigma, max(y_line) + 3 * sigma)) # y軸の表示範囲 plt.legend() # 凡例 plt.grid() # グリッド線 plt.show()
標準偏差の範囲をplt.fill_between()で表示します。
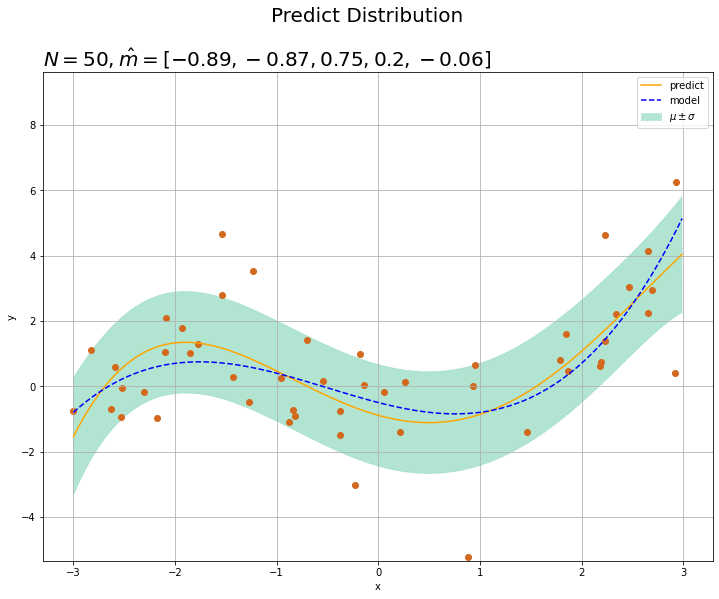
観測データが増えると予測分布の平均(オレンジの実線)が真のモデル(青の破線)に近付き、また精度の範囲(緑の塗りつぶし)が狭まります。
x軸の各点$x_{*}$において、y軸方向に平均$\hat{\mu}_{*}$、精度$\hat{\lambda}_{*}$の1次元ガウス分布になっています。
・過学習の確認
いくつか値を変えて試してみましょう。
まずは、データ数$N$を減らして次元数$M$を増やした場合を見てみましょう。真の次元数4に対して、$N = 10$、$M = 10$とします。
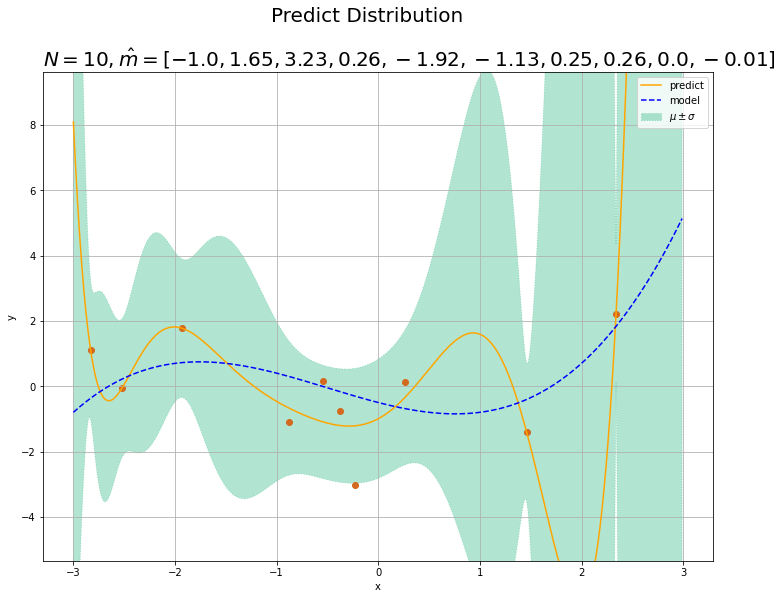
観測モデル(青の破線)への当てはまりが悪くなり、また精度も悪くなっています(標準偏差の範囲が広くなっています)。パラメータ数(次元数)が増えたことでモデル(オレンジの実線)の表現力が上がり、データへの当てはまりが過剰に良くなっています。
次は、x軸の描画範囲を広くして、観測データのない範囲に対する予測分布を確認してみましょう。$N = 50$、$M = 10$として、またx_nの作成時の範囲をx_lineの範囲よりも狭くします。
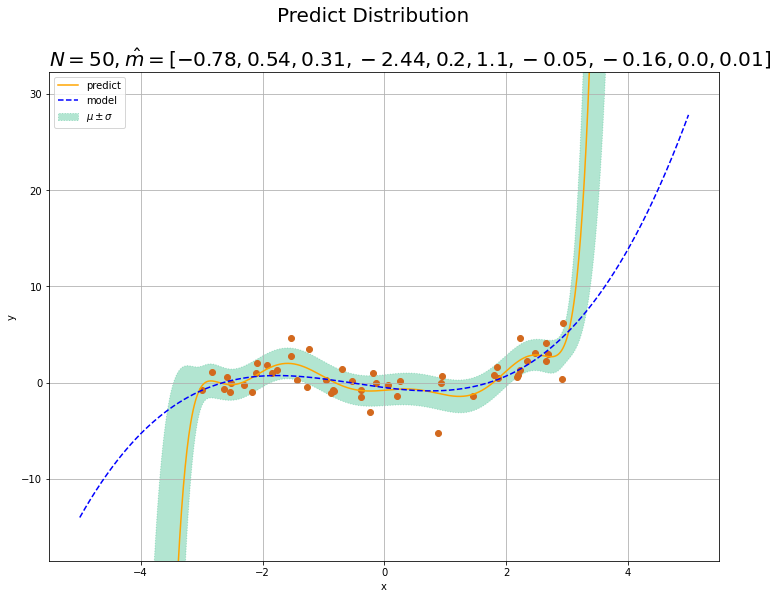
$M$の値が真の値よりも大きいと、観測データの範囲を越えたとたんに予測できていません。
真の値と同じ$M = 4$とします。
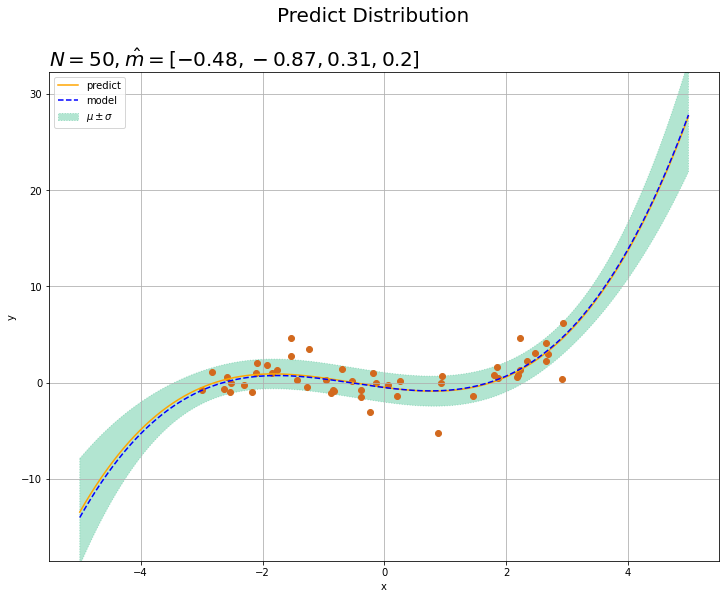
$M$が真の値と一致していると、予測ができていますね。m_hat_mの値がw_truth_mに近付いています。
・おまけ:アニメーションで推移の確認
animationモジュールを利用して、gif画像を作成するコードです。
・コード(クリックで展開)
異なる点のみを簡単に解説します。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation
# {x^(m-1)}ベクトル作成関数を定義 def x_vector(x_n, M): # 受け皿を作成 x_nm = np.zeros(shape=(len(x_n), M)) # m乗を計算 for m in range(M): x_nm[:, m] = np.power(x_n, m) return x_nm
・観測データ数が予測精度へ与える影響
まずは、観測データの増加が予測精度へ与える影響を確認します。
・コード(クリックで展開)
・観測モデルの設定
# 真の次元数を指定 M_truth = 4 # ノイズ成分の標準偏差を指定 sigma = 1.5 # ノイズ成分の精度を計算 lmd = 1.0 / sigma**2 # 真のパラメータを生成 w_truth_m = np.random.choice( np.arange(-1.0, 1.0, step=0.1), size=M_truth, replace=True ) # 作図用のx軸の値を作成 x_line = np.arange(-3.0, 3.0, step=0.01) # 真のモデルの出力を計算 y_line = np.dot(w_truth_m.reshape((1, M_truth)), x_vector(x_line, M_truth).T).flatten()
・事前分布の設定
# 事前分布の次元数を指定 M = 5 # 事前分布のパラメータを指定 m_m = np.zeros(M) lambda_mm = np.identity(M) * 0.01 # 作図用のxをM次元に拡張 x_arr = x_vector(x_line, M) # 初期値による予測分布のパラメータを計算:式(3.155) mu_star_line = np.dot(m_m.reshape((1, M)), x_arr.T).flatten() sigma2_star_line = np.diag( x_arr.dot(np.linalg.inv(lambda_mm)).dot(x_arr.T) ) + 1 / lmd
・推論処理
各試行の結果をリストに格納していく必要があります。パラメータについてそれぞれtrace_***として、初期値の結果を持つように作成しておきます。
# データ数を指定:(試行回数) N = 100 # 推移の記録用の受け皿を初期化 x_n = np.empty(N) y_n = np.empty(N) trace_m = [list(m_m)] trace_mu_star = [list(mu_star_line)] trace_sigma_star = [list(np.sqrt(sigma2_star_line))] # ベイズ推論 for n in range(N): # 入力値を生成 x_n[n] = np.random.choice( np.arange(min(x_line), max(x_line), step=0.01), size=1, replace=True ) # 出力値を計算:式(3.141) term_y = np.dot(w_truth_m.reshape((1, M_truth)), x_vector(x_n[n].reshape((1, 1)), M_truth).T) term_eps = np.random.normal(loc=0.0, scale=np.sqrt(1 / lmd), size=1) # ノイズ成分 y_n[n] = term_y + term_eps # 入力値をM次元に拡張 x_1n = x_vector(x_n[n].reshape((1, 1)), M) # 事後分布のパラメータを更新:式(3.148) old_lambda_mm = lambda_mm.copy() lambda_mm += lmd * np.dot(x_1n.T, x_1n) term_m_m = lmd * y_n[n] * x_1n.T term_m_m += np.dot(old_lambda_mm, m_m.reshape((M, 1))) m_m = np.dot(np.linalg.inv(lambda_mm), term_m_m).flatten() # 予測分布のパラメータを更新:式(3.155) mu_star_line = np.dot(m_m.reshape((1, M)), x_arr.T).flatten() sigma2_star_line = np.diag( x_arr.dot(np.linalg.inv(lambda_mm)).dot(x_arr.T) ) + 1 / lmd # パラメータを記録 trace_m.append(list(m_m)) trace_mu_star.append(list(mu_star_line)) trace_sigma_star.append(list(np.sqrt(sigma2_star_line)))
観測された各データによってどのように学習する(分布が変化する)のかを確認するため、for文で1データずつ処理します。よって、データ数Nがイタレーション数になります。
一度の処理で事後分布のパラメータを計算するのではなく、事前分布(1ステップ前の事後分布)に対して繰り返し観測データの情報を与えることでパラメータを更新(上書き)していきます。
それに伴い、事後分布のパラメータの計算式(3.148)の$\sum_{n=1}^N \mathbf{x}_n$の計算は、ループ処理によって$N$回繰り返しx_nd[n]を加えることで行います。$n$回目のループ処理のときには、$n-1$回分のx_nd[n]が既にlambda_mmとm_mに加えられているわけです。
ただし、事後分布のパラメータの計算において、更新前(1ステップ前)のパラメータ$\boldsymbol{\Lambda}$を使うため、old_lambda_mmとして値を一時的に保存しておきます。
・作図処理
# 画像サイズを指定 fig = plt.figure(figsize=(12, 9)) # 作図処理を関数として定義 def update_predict(n): # 前フレームのグラフを初期化 plt.cla() # nフレーム目の予測分布を作図 plt.plot(x_line, trace_mu_star[n], color='orange', label='predict') # 予測分布の期待値 plt.fill_between(x=x_line, y1=np.array(trace_mu_star[n]) - np.array(trace_sigma_star[n]), y2=np.array(trace_mu_star[n]) + np.array(trace_sigma_star[n]), color='#00A968', alpha=0.3, linestyle='dotted', label='$\mu \pm \sigma$') # 予測分布の標準偏差 plt.plot(x_line, y_line, linestyle='dashed', color='blue', label='model') # 真のモデル plt.scatter(x_n[0:n], y_n[0:n], color='chocolate') # 観測データ plt.xlabel('x') plt.ylabel('y') plt.suptitle('Predict Distribution', fontsize=20) plt.title('$N=' + str(n) + ', \hat{m}=[' + ', '.join([str(m) for m in np.round(trace_m[n], 2)]) + ']$', loc='left', fontsize=20) plt.ylim((min(y_line) - 3 * sigma, max(y_line) + 3 * sigma)) # y軸の表示範囲 plt.grid() # グリッド線 # gif画像を作成 predict_anime = animation.FuncAnimation(fig, update_predict, frames=N + 1, interval=100) predict_anime.save("ch3_5_Predict_N.gif")
初期値(事前分布)を用いた結果を含むため、フレーム数の引数nframesはN + 1です。
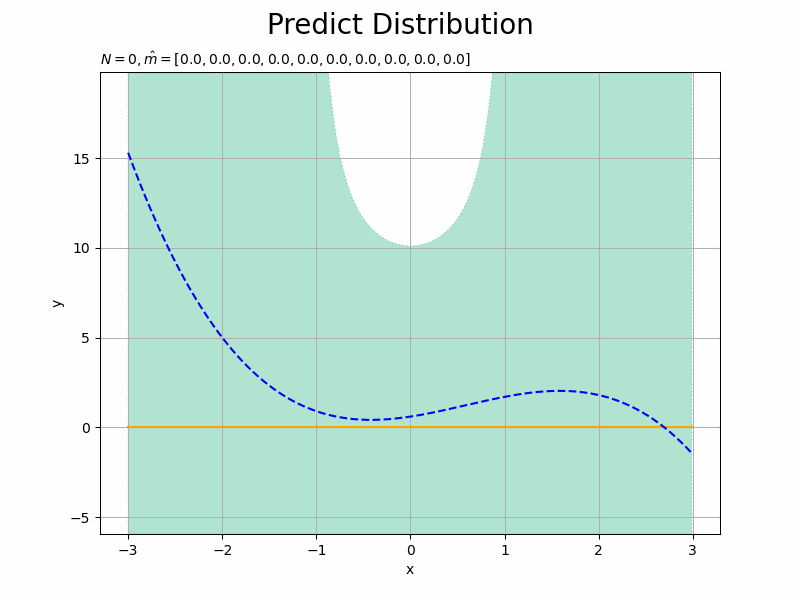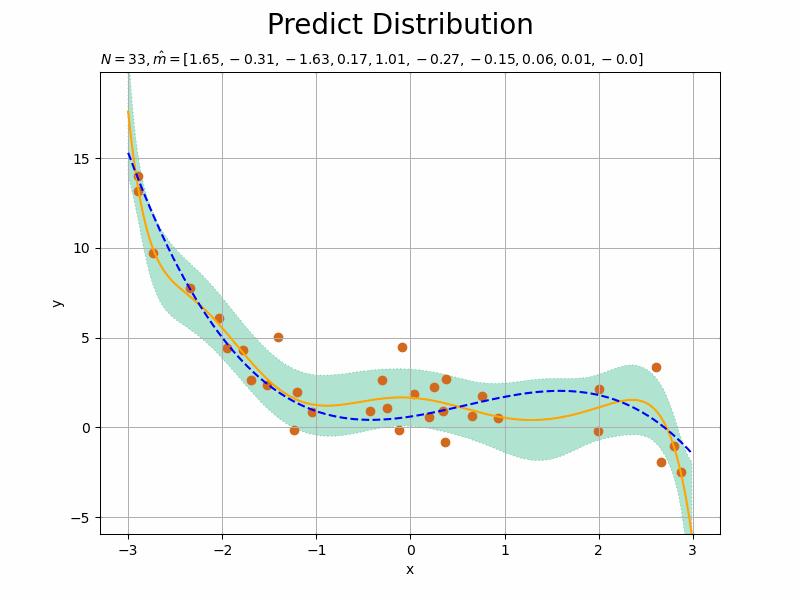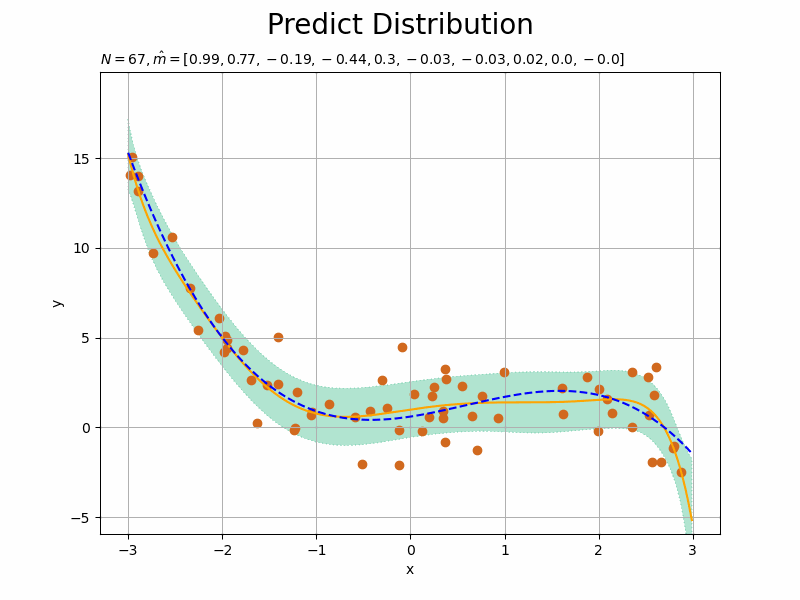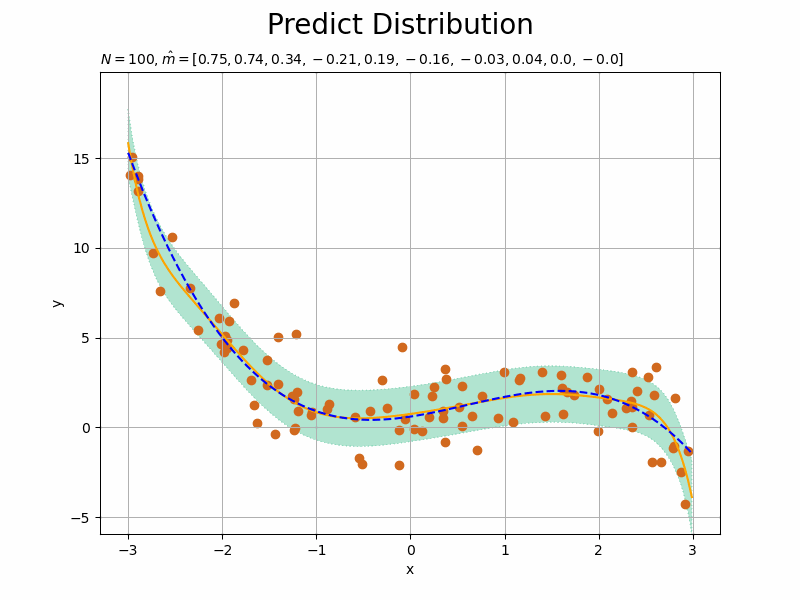
・事前分布の次元数が予測精度へ与える影響
次に、同じ観測データを用いたとき、パラメータの数(事前分布の次元数)の違いが予測精度へ与える影響を確認します。
・コード(クリックで展開)
・観測モデルの設定
# 真の次元数を指定 M_truth = 4 # ノイズ成分の標準偏差を指定 sigma = 1.5 # ノイズ成分の精度を計算 lmd = 1.0 / sigma**2 # 真のパラメータを生成 w_truth_m = np.random.choice( np.arange(-1.0, 1.0, step=0.1), size=M_truth, replace=True ) # 作図用のx軸の値を作成 x_line = np.arange(-3.0, 3.0, step=0.01) # 真のモデルの出力を計算 y_line = np.dot(w_truth_m.reshape((1, M_truth)), x_vector(x_line, M_truth).T).flatten()
・観測データの生成
# (観測)データ数を指定 N = 10 # 入力値を生成 x_n = np.random.choice( np.arange(min(x_line), max(x_line), step=0.01), size=N, replace=True ) # ノイズ成分を生成 epsilon_n = np.random.normal(loc=0.0, scale=np.sqrt(1 / lmd), size=N) # 出力値を計算:式(3.141) y_n = np.dot(w_truth_m.reshape(1, M_truth), x_vector(x_n, M_truth).T) + epsilon_n
・推論処理
# 事前分布の次元数の最大値(試行回数)を指定 M_max = 15 # 推移の記録用の受け皿を初期化 trace_m = [] trace_mu_star = [] trace_sigma_star = [] # ベイズ推論 for m in range(1, M_max + 1): # 事前分布のパラメータをm次元に初期化 m_m = np.zeros(m) lambda_mm = np.identity(m) * 0.01 # 入力値をm次元に拡張 x_nm = x_vector(x_n, m) # 作図用のxをm次元に拡張 x_arr = x_vector(x_line, m) # 事後分布のパラメータを更新:式(3.148) lambda_hat_mm = lmd * np.dot(x_nm.T, x_nm) + lambda_mm term_m_m = lmd * np.dot(y_n.reshape((1, N)), x_nm).T term_m_m += np.dot(lambda_mm, m_m.reshape((m, 1))) m_hat_m = np.dot(np.linalg.inv(lambda_hat_mm), term_m_m).flatten() # 予測分布のパラメータを計算:式(3.155') mu_star_hat_line = np.dot(m_hat_m.reshape((1, m)), x_arr.T).flatten() sigma2_star_hat_line = np.diag( x_arr.dot(np.linalg.inv(lambda_hat_mm)).dot(x_arr.T) ) + 1 / lmd # パラメータを記録 trace_m.append(list(m_hat_m)) trace_mu_star.append(list(mu_star_hat_line)) trace_sigma_star.append(list(np.sqrt(sigma2_star_hat_line)))
こちらはM_maxをイタレーション数として、推論処理をM_max回繰り返します。
イタレーションごとに事前分布の次元数(パラメータ数)が変わるので、事前分布のパラメータを初期化します。また、x_nとx_lineの次元数も更新します。
・作図処理
# 画像サイズを指定 fig = plt.figure(figsize=(12, 9)) # 作図処理を関数として定義 def update_predict(i): # 前フレームのグラフを初期化 plt.cla() # nフレーム目の予測分布を作図 plt.plot(x_line, trace_mu_star[i], color='orange', label='predict') # 予測分布の期待値 plt.fill_between(x=x_line, y1=np.array(trace_mu_star[i]) - np.array(trace_sigma_star[i]), y2=np.array(trace_mu_star[i]) + np.array(trace_sigma_star[i]), color='#00A968', alpha=0.3, linestyle='dotted', label='$\mu \pm \sigma$') # 予測分布の標準偏差 plt.plot(x_line, y_line, linestyle='dashed', color='blue', label='model') # 真のモデル plt.scatter(x_n, y_n, color='chocolate') # 観測データ plt.xlabel('x') plt.ylabel('y') plt.suptitle('Predict Distribution', fontsize=20) plt.title('$N=' + str(N) + ', M=' + str(i + 1) + ', \hat{m}=[' + ', '.join([str(m) for m in np.round(trace_m[i], 2)]) + ']$', loc='left', fontsize=20) plt.ylim((min(y_line) - 3 * sigma, max(y_line) + 3 * sigma)) # y軸の表示範囲 plt.grid() # グリッド線 # gif画像を作成 predict_anime = animation.FuncAnimation(fig, update_predict, frames=M_max, interval=100) predict_anime.save("ch3_5_Predict_M.gif")
$M$が大きくなるにしたがって、観測データに過剰適合していくのが確認できます。
(よく理解していないので、animationの解説は省略…とりあえずこれで動きます……)
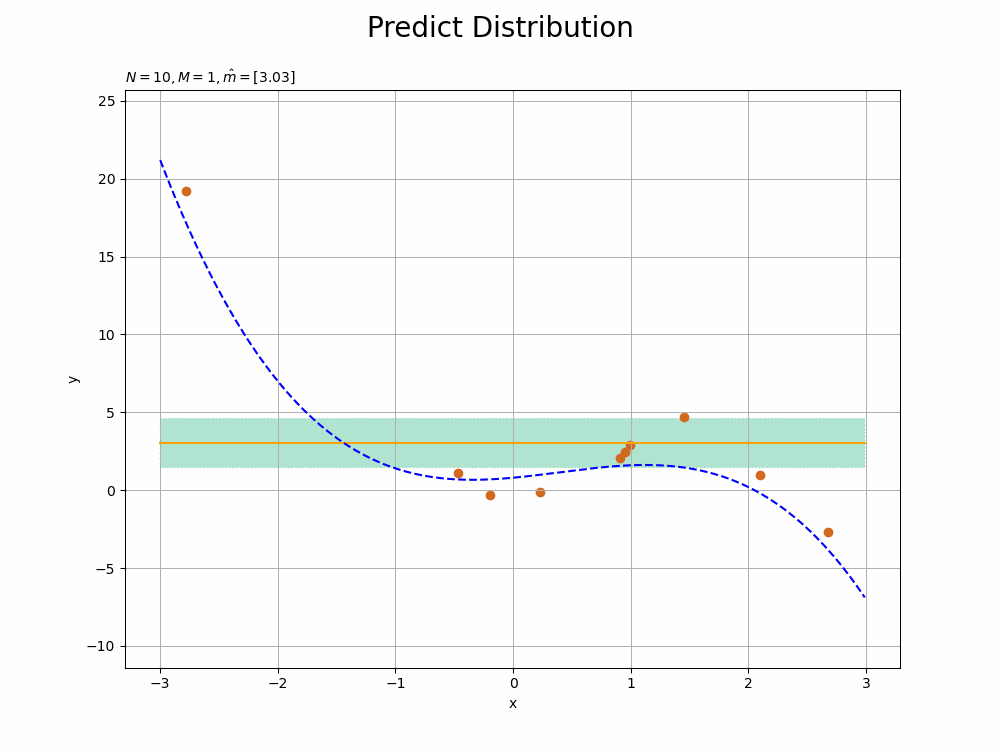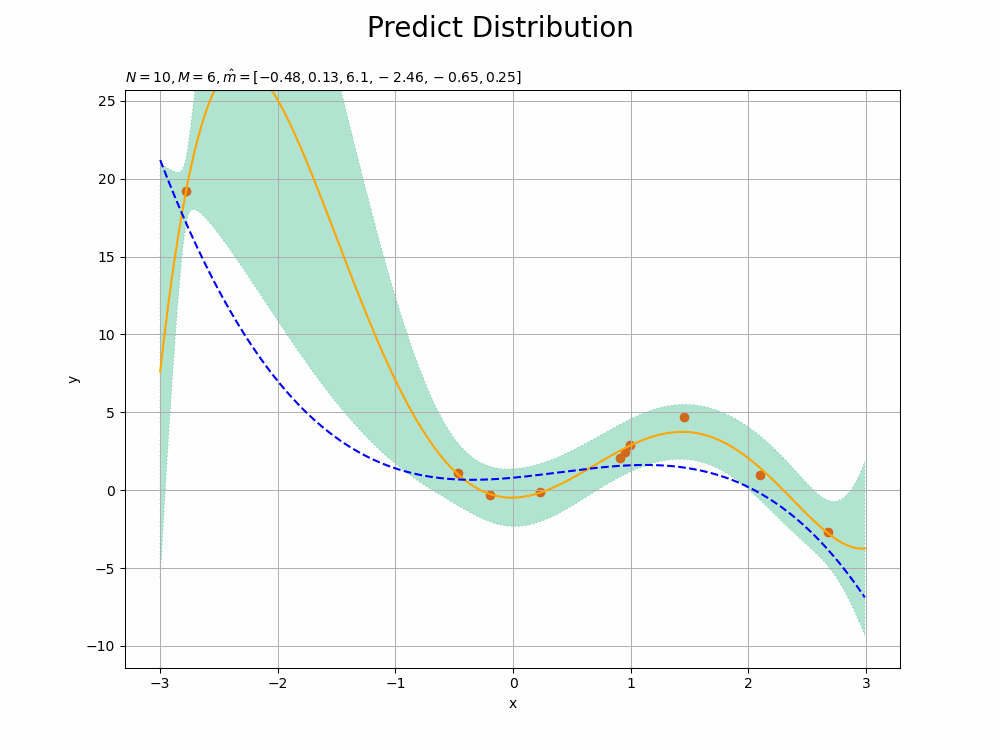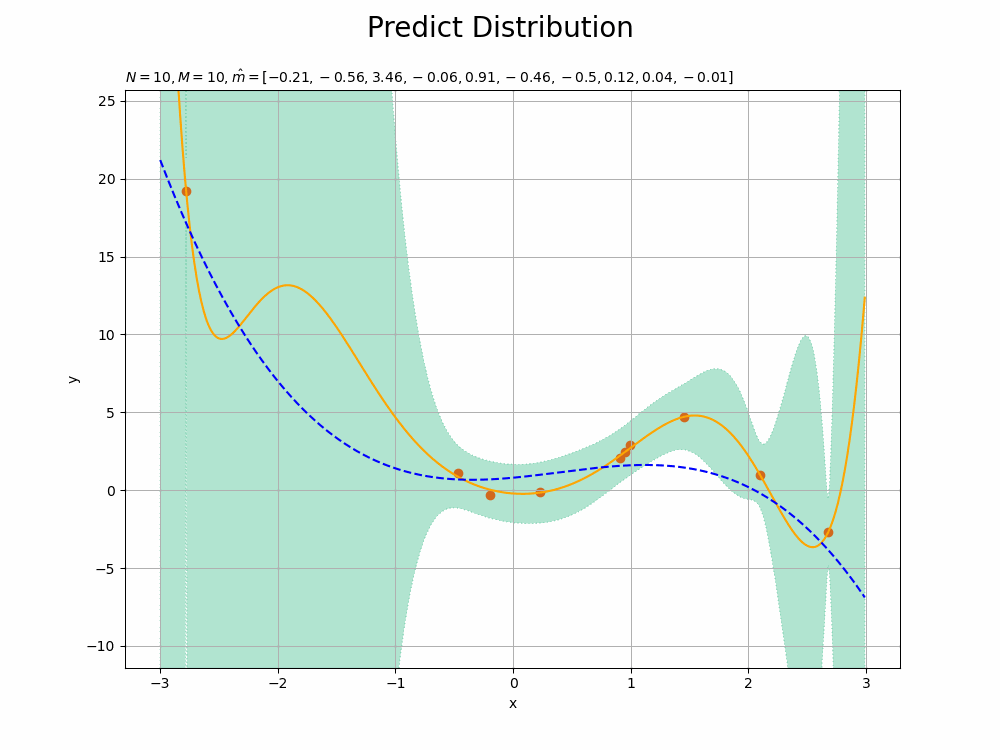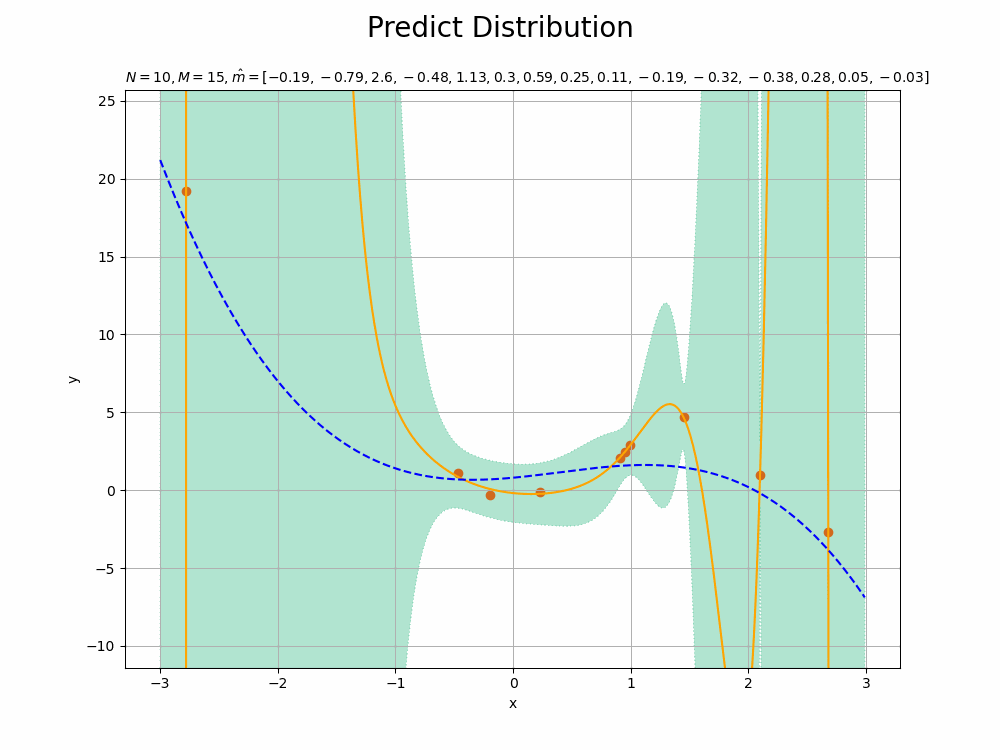
$M$が大きくなるにしたがって、観測データに過剰適合していくのが確認できます。
参考文献
- 須山敦志『ベイズ推論による機械学習入門』(機械学習スタートアップシリーズ)杉山将監修,講談社,2017年.
おわりに
Rで書いたものをPythonに翻訳した形です。Pythonの勉強のためにベイズ推論を扱った、という方が近いかもしれません。まだPythonらしさのようなものを全然掴めていないので、色々アレなところがあるのだろうと思います。何か気になるところがあれば、ご指摘いただければとても嬉しいです。
せめてclassとして実装すればPythonらしかろうと試してみましたが、この例だと$x_n$を$(x_n^0, x_n^1, \cdots, x_n^{M-1})$に変換する処理を組み込むのが面倒なうえに分かりにくくなったので止めました、、
しかし大半はコピペで済むだろうし水増しっぽくなってしまうかなと書く前には危惧していたのですが、全然そんなことなくて普通に一記事分疲れました。これまでの記事もPythonでも実装してみたいけど、まだ手が出ないかなぁ。
【次節の内容】
- 2021/04/19:加筆修正しました。
他の節の内容もPythonで実装しました。