はじめに
『ゼロから作るDeep Learning 2――自然言語処理編』の初学者向け【実装】攻略ノートです。『ゼロつく2』学習の補助となるように適宜解説を加えています。本と一緒に読んでください。
本の内容を1つずつ確認しながらゆっくりと組んでいきます。
この記事は、3.4節「 BOWモデルの実装」の内容です。シンプルなBOWモデルをPythonで実装して、簡単なテキストを学習を行います。
【前節の内容】
【他の節の内容】
【この節の内容】
・CBOWモデルの実装
簡単なCBOWモデルをクラスとして実装します。
レイヤやパラメータの格納方法などの基本的なモデルの実装は、「1.4:ニューラルネットワークで問題を解く【ゼロつく2のノート(実装)】 - からっぽのしょこ」と同じです。
CBOWモデルの順伝播メソッドで行う処理は、3.2節で確認しました。
逆伝播メソッドで行う処理は、後のレイヤから順番に各レイヤの逆伝播メソッドを実行します。各レイヤについて、Softmax with Lossレイヤは1.3.5.3項、MatMulレイヤは1.3.4.5項で実装しました。加算ノード・乗算ノードについては1.3.4の始め・1.3.4.1項、または「5.4:単純なレイヤの実装【ゼロつく1のノート(実装)】 - からっぽのしょこ」を参照してください。
# CBOWの実装 class SimpleCBOW: # 初期化メソッドの定義 def __init__(self, vocab_size, hidden_size): # ニューロン数を保存 V = vocab_size # 入力層と出力層 H = hidden_size # 中間層 # 重みの初期値を生成 W_in = 0.01 * np.random.randn(V, H).astype('f') W_out = 0.01 * np.random.randn(H, V).astype('f') # レイヤを生成 self.in_layer0 = MatMul(W_in) # 入力層 self.in_layer1 = MatMul(W_in) # 入力層 self.out_layer = MatMul(W_out) # 出力層 self.loss_layer = SoftmaxWithLoss() # 損失層 # 各レイヤをリストに格納 layers = [ self.in_layer0, self.in_layer1, self.out_layer, self.loss_layer ] # 各レイヤのパラメータと勾配をリストに格納 self.params = [] # パラメータ self.grads = [] # 勾配 for layer in layers: self.params += layer.params self.grads += layer.grads # 単語の分散表現を保存 self.word_vecs = W_in # 順伝播メソッドの定義 def forward(self, contexts, target): # 重み付き和を計算 h0 = self.in_layer0.forward(contexts[:, 0]) h1 = self.in_layer1.forward(contexts[:, 1]) h = (h0 + h1) * 0.5 # スコアを計算 score = self.out_layer.forward(h) # 交差エントロピー誤差を計算 loss = self.loss_layer.forward(score, target) return loss # 逆伝播メソッドの定義 def backward(self, dout=1): # Lossレイヤの勾配を計算 ds = self.loss_layer.backward(dout) # 出力層の勾配を計算 da = self.out_layer.backward(ds) da *= 0.5 # 入力層の勾配を計算 self.in_layer1.backward(da) self.in_layer0.backward(da) return None
実装したクラスを試してみましょう。
テキストを指定して、前処理を行います(2.3.1項)。
# テキストを設定 text = 'You say goodbye and I say hello.' # 前処理 corpus, word_to_id, id_to_word = preprocess(text) print(word_to_id) print(id_to_word) print(corpus)
{'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}
{0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'}
[0, 1, 2, 3, 4, 1, 5, 6]
one-hot表現のコンテキストとターゲットを作成します(3.3.1-2項)。SimpleCBOWでは2単語のコンテキストのみに対応しているため、ウィンドウサイズは1です。
# ウインドウサイズ window_size = 1 # 単語の種類数を取得 vocab_size = len(word_to_id) print(vocab_size) # コンテキストとターゲットを作成 contexts, target = create_contexts_target(corpus, window_size) print(contexts) print(contexts.shape) print(target) print(target.shape) # one-hot表現に変換 contexts = convert_one_hot(contexts, vocab_size) target = convert_one_hot(target, vocab_size) print(contexts) print(contexts.shape) print(target) print(target.shape)
7
[[0 2]
[1 3]
[2 4]
[3 1]
[4 5]
[1 6]]
(6, 2)
[1 2 3 4 1 5]
(6,)
[[[1 0 0 0 0 0 0]
[0 0 1 0 0 0 0]]
[[0 1 0 0 0 0 0]
[0 0 0 1 0 0 0]]
[[0 0 1 0 0 0 0]
[0 0 0 0 1 0 0]]
[[0 0 0 1 0 0 0]
[0 1 0 0 0 0 0]]
[[0 0 0 0 1 0 0]
[0 0 0 0 0 1 0]]
[[0 1 0 0 0 0 0]
[0 0 0 0 0 0 1]]]
(6, 2, 7)
[[0 1 0 0 0 0 0]
[0 0 1 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 0 1 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 1 0]]
(6, 7)
中間層のニューロン数を指定して、SimpleCBOWクラスのインスタンスを作成します。
# 中間層のニューロン数を指定 hidden_size = 5 # CBOWモデルのインスタンスを作成 model = SimpleCBOW(vocab_size, hidden_size)
インスタンスが作成された時点で重みが生成され、またその値がインスタンス変数word_vecsとしても格納されています。
# 重みとword_vecsを確認 print(np.round(model.params[0], 3)) # 入力層0 print(np.round(model.params[1], 3)) # 入力層1 print(np.round(model.word_vecs, 3)) # 分散表現
[[ 0.006 0.005 -0.003 0.016 0.011]
[ 0.002 0.001 0.013 -0.005 0.004]
[-0.002 -0.007 -0.007 -0.008 -0.001]
[-0.005 -0.007 0.007 0.002 -0.027]
[ 0. -0.012 -0.022 -0.01 -0.003]
[ 0.008 0.011 0.003 0.004 0. ]
[-0.001 0.001 0.002 0.004 0.007]]
[[ 0.006 0.005 -0.003 0.016 0.011]
[ 0.002 0.001 0.013 -0.005 0.004]
[-0.002 -0.007 -0.007 -0.008 -0.001]
[-0.005 -0.007 0.007 0.002 -0.027]
[ 0. -0.012 -0.022 -0.01 -0.003]
[ 0.008 0.011 0.003 0.004 0. ]
[-0.001 0.001 0.002 0.004 0.007]]
[[ 0.006 0.005 -0.003 0.016 0.011]
[ 0.002 0.001 0.013 -0.005 0.004]
[-0.002 -0.007 -0.007 -0.008 -0.001]
[-0.005 -0.007 0.007 0.002 -0.027]
[ 0. -0.012 -0.022 -0.01 -0.003]
[ 0.008 0.011 0.003 0.004 0. ]
[-0.001 0.001 0.002 0.004 0.007]]
全て同じ値になります。次項で行う学習(パラメータの更新)時に、値が更新されます。
コンテクストを入力データ、ターゲットを教師ラベルとして、SimpleCBOWクラスの順伝播メソッドを実行します。
# 順伝播(損失)を計算 loss = model.forward(contexts, target) print(loss)
1.9459441158605602
損失(交差エントロピー誤差)の値が出力されました。この節で実装したクラスでは、スコア(推論結果)を外から確認することはできません。
逆伝播メソッドを実行します。逆伝播の入力は$\frac{\partial L}{\partial L} = 1$です。デフォルト値として設定されているので、引数に指定しなくても処理できます。
# 逆伝播(勾配)を計算 model.backward(dout=1) # 勾配を確認 print(np.round(model.grads[0], 3)) # 入力層0 print(np.round(model.grads[1], 3)) # 入力層1
[[-0. 0.001 -0. 0. 0. ]
[ 0.002 0.002 -0. 0.002 -0. ]
[ 0.001 -0.001 0. -0.001 -0.001]
[-0.001 -0.001 0. -0. 0. ]
[-0. 0.001 -0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. ]]
[[ 0. 0. 0. 0. 0. ]
[-0.001 -0.001 0. -0. 0. ]
[-0. 0.001 -0. 0. 0. ]
[ 0.001 0.001 -0.001 0.001 -0. ]
[ 0.001 -0.001 0. -0.001 -0.001]
[-0. 0.001 -0. 0. 0. ]
[ 0.001 0.001 0. 0.001 -0. ]]
各層の重みに関する勾配をインスタンス変数に保存しています。この値を用いてパラメータを更新します。入力(コンテキスト)の値が異なるため、2つの入力層の勾配の値は異なります。
以上でCBOWモデルを実装できたので、次項で学習を行います。
3.4.1 学習コードの実装
CBOWモデルによる学習を行います。
1.4.4項で実装したTrainerクラスを使って、学習を行います。
これまでに実装済みのクラスや関数の定義を再実行するか、次の方法でマスターデータから読み込みます。また最適化手法として用いるAdamについては実装していないので、これも読み込みます。
# 読み込み用の設定 import sys sys.path.append('C://Users//「ユーザー名」//Documents//・・・//deep-learning-from-scratch-2-master') # 実装済みのクラスをインポート #from common.trainer import Trainer from common.optimizer import Adam
前項の最後に作成した前処理済みのコーパスを使います。
この例では、最適化手法にAdamを用います。Adamについては「6.1.6:Adam【ゼロつく1のノート(実装)】 - からっぽのしょこ」、パラメータの更新については1.3.6項、学習処理については1.4.4項を参照してください。
# 中間層のニューロン数を指定 hidden_size = 5 # 2層のCBOWのインスタンスを作成 model = SimpleCBOW(vocab_size, hidden_size) # 最適化手法のインスタンスを作成 optimizer = Adam() # 学習処理のインスタンスを作成 trainer = Trainer(model, optimizer)
バッチサイズと試行回数を指定して、学習を行います。ちなみにこの例のデータ数は6なので、バッチサイズを3とするとmax_iters(クラス内部で用いる変数でミニバッチデータに対する試行回数)は2になります。つまりミニバッチデータに対して2回学習を行うことで、1エポック分の学習を行ったことになります。max_epochには、これを繰り返す回数を指定します。
Trainerクラスの学習メソッド.fit()で学習を行えます。eval_intervalにmax_itersと同じ2を指定することで、1エポックごとの平均損失を記録と途中経過として表示します。
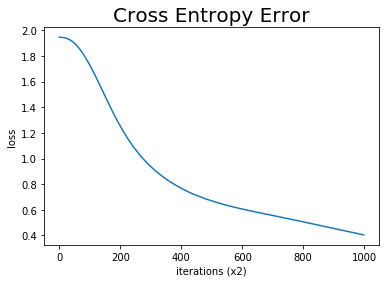
# バッチサイズを指定 batch_size = 3 # 試行回数を指定 max_epoch = 1000 # 学習 trainer.fit(contexts, target, max_epoch, batch_size, eval_interval=2)
| epoch 1 | iter 2 / 2 | time 0[s] | loss 1.95
| epoch 2 | iter 2 / 2 | time 0[s] | loss 1.95
| epoch 3 | iter 2 / 2 | time 0[s] | loss 1.95
(省略)
| epoch 999 | iter 2 / 2 | time 0[s] | loss 0.41
| epoch 1000 | iter 2 / 2 | time 0[s] | loss 0.40
グラフ作成メソッド.plot()で、損失の推移をグラフ化して、学習の進行具合を確認します。
# 損失の推移をグラフ化
trainer.plot()
あ、Trainerクラスに関して本(マスターデータ)とは少しだけ実装を変えています。元は
# 評価 if (eval_interval is not None) and (iters % eval_interval) == 0: print(省略)
となっている部分を、2つ目の条件について(iters + 1) % eval_intervalとしています。本の通りだと1エポック分のランダムなデータごとの平均損失を計算するのに対して、このレジュメだとそのままのエポックデータごとに平均損失を計算するため「確率的でない」勾配降下法になります(?)。そのため滑らかに推移するのだと思われます(?)。
なのでbatch_size=2、eval_interval=2を指定すると、データサイズ6に対して4データごとに学習を行うので、似たような推移をするようになります。
# 2層のCBOWのインスタンスを作成 model = SimpleCBOW(vocab_size, hidden_size) # 最適化手法のインスタンスを作成 optimizer = Adam() # 学習処理のインスタンスを作成 trainer = Trainer(model, optimizer) # 学習 trainer.fit(contexts, target, max_epoch, batch_size=2, eval_interval=2) # 損失の推移をグラフ化 trainer.plot()
| epoch 1 | iter 2 / 3 | time 0[s] | loss 1.95
| epoch 2 | iter 2 / 3 | time 0[s] | loss 1.95
| epoch 3 | iter 2 / 3 | time 0[s] | loss 1.95
(省略)
| epoch 999 | iter 2 / 3 | time 0[s] | loss 0.27
| epoch 1000 | iter 2 / 3 | time 0[s] | loss 0.27

iter m / nの値が異なることがポイントです。実装済みのクラスをインポートした場合は、図3-21になります。
インスタンス変数word_vecsとして格納されている単語ベクトル(分散表現)を、単語ごとに表示して確認しましょう。
# 単語ベクトルを表示 word_vecs = model.word_vecs for word_id, word in id_to_word.items(): print(word, word_vecs[word_id])
you [-1.10261 -1.0269005 1.0508274 -1.8287948 -0.9188457]
say [-1.2173952 1.5790888 -1.5974151 0.17116202 0.35756773]
goodbye [-0.81904256 -1.2311023 1.2151331 0.64199305 -1.0075108 ]
and [-0.08892915 1.4543467 -1.4873011 -1.7322725 -1.9171607 ]
i [-0.79735 -1.1985191 1.194357 0.63963884 -1.0185876 ]
hello [-1.099235 -1.0437735 1.0563935 -1.8364193 -0.9207778]
. [-1.3006138 0.91300577 -0.9189685 1.439913 1.4208736 ]
この単語ベクトルを用いて、単語間のコサイン類似度を確認しましょう。2.3.5-6項で実装したcos_similarity()とmost_similar()を使用します。
# クエリを指定 query = 'you' # 共起行列を用いた類似度の上位単語を表示 most_similar(query, word_to_id, id_to_word, model.word_vecs, top=6)
[query] you
hello: 0.9999852180480957
goodbye: 0.5150696039199829
i: 0.5119754076004028
and: 0.21600431203842163
say: -0.3655865788459778
.: -0.5867670178413391
重みの初期値やミニバッチデータの取得時にランダムな処理を行うため、この値は処理の度に異なります。
「hello」の類似度が一番高くほぼ1になり、次いで「I」と「goodbye」が0.4から0.9の値になるようです。
以上で簡単なCBOWモデルの実装と学習を行い、word2vecを得られました!次章では、より本格的な実装を行います。その前に次節では、word2vecについていくつか補足します。
参考文献

おわりに
早く本格的なコーパスで試したい。
【次節の内容】