はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、混合ユニグラムモデル(カテゴリモデル)の生成モデルをR言語でスクラッチ実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
3.1 混合ユニグラムモデルの生成モデルの実装
混合ユニグラムモデル(mixture of unigram models)の生成モデル(generative model)・生成過程(generative process)を実装して、簡易的な文書データ(トイデータ)を作成する。
混合ユニグラムモデルについては「3.1:混合ユニグラムモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
利用するパッケージを読み込む。
# 利用パッケージ library(tidyverse) library(MCMCpack)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージの読み込みは不要である。ただし、作図コードについてはパッケージ名を省略するので、ggplot2 を読み込む必要がある。
また、ネイティブパイプ演算子 |> を使う。magrittrパッケージのパイプ演算子 %>% に置き換えられるが、その場合は magrittr を読み込む必要がある。
文書データの簡易生成
まずは、混合ユニグラムモデルの生成モデルに従って、bag-of-words表現の文書データに対応する頻度データを作成する。
真の分布や真のトピックなど本来は得られない情報についてはオブジェクト名に true を付けて表す。
パラメータの設定
文書集合に関する値を設定する。
# 文書数を指定 D <- 10 # 語彙数を指定 V <- 6 # トピック数を指定 true_K <- 4
文書数 、語彙(単語の種類)数
、トピック数
を指定する。
トピック分布のハイパーパラメータを設定する。
# トピック分布のハイパーパラメータを指定 true_alpha <- 1 true_alpha_k <- rep(true_alpha, times = true_K) # 一様な値の場合 #true_alpha_k <- runif(n = true_K, min = 1, max = 2) # 多様な値の場合 true_alpha_k
[1] 1 1 1 1
個の値(ベクトル)
を指定する。各値は0より大きい値
を満たす必要がある。全て同じ値
とする場合は、1個の値(スカラ)
で表す。
単語分布のパラメータを設定する。
# トピック分布のパラメータを生成 #true_theta_k <- rep(1/true_K, times = true_K) # 一様な値の場合 true_theta_k <- MCMCpack::rdirichlet(n = 1, alpha = true_alpha_k) |> # 多様な値の場合 as.vector() true_theta_k; sum(true_theta_k)
[1] 0.25079959 0.07110367 0.43141499 0.24668175 [1] 1
トピック分布のパラメータ を作成する。パラメータは
個の値(ベクトル)
であり、各値は0から1の値
で、総和が1になる値
を満たす必要がある。
ディリクレ分布の乱数は、rdirichlet() で生成できる。サンプルサイズの引数 n に 1、パラメータの引数 alpha にハイパーパラメータ を指定する。
単語分布のハイパーパラメータを設定する。
# 単語分布のハイパーパラメータを指定 true_beta <- 1 true_beta_v <- rep(true_beta, times = V) # 一様な値の場合 #true_beta_v <- runif(n = V, min = 1, max = 2) # 多様な値の場合 true_beta_v
[1] 1 1 1 1 1 1
個の値(ベクトル)
を指定する。各値は0より大きい値
を満たす必要がある。全て同じ値
とする場合は、1個の値(スカラ)
で表す。
単語分布のパラメータを設定する。
# 単語分布のパラメータを生成 #true_phi_kv <- matrix(1/V, nrow = true_K, ncol = V) # 一様な値の場合 true_phi_kv <- MCMCpack::rdirichlet(n = true_K, alpha = true_beta_v) # 多様な値の場合 true_phi_kv; dim(true_phi_kv); rowSums(true_phi_kv)
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 0.25625139 0.07644672 0.02243639 0.09277464 0.1634189 0.38867201 [2,] 0.10379440 0.20187554 0.05026045 0.41110050 0.0100784 0.22289071 [3,] 0.12322837 0.12488464 0.08011186 0.13002659 0.4937594 0.04798916 [4,] 0.01872612 0.06757958 0.11273103 0.43155940 0.1163059 0.25309797 [1] 4 6 [1] 1 1 1 1
個の単語分布(語彙分布)のパラメータ
を作成する。パラメータは
個の値(ベクトル)
であり、各値は0から1の値
で、総和が1になる値
を満たす必要がある。
rdirichlet() の n 引数にトピック数 、
alpha 引数にハイパーパラメータ を指定する。
true_K 行 V 列のマトリクスとして扱う。
頻度データの生成
トピックモデルでは単語が出現した順番(語順)は考慮しないので、語順情報の有無によって2通り方法で頻度情報を作成する。どちらの方法でも同じ形式のオブジェクトを作成できる。
語順を記録する場合
語彙の出現順と共に語彙ごとの出現頻度を作成する。こちらの方法では、混合ユニグラムモデルの生成過程をより再現するように処理している。
設定したパラメータに従う文書データを作成する。
# 文書集合を初期化 w_lt <- list() # 各文書のトピックを初期化 true_z_d <- rep(NA, times = D) # 各文書の単語数を初期化 N_d <- rep(NA, times = D) # 文書ごとの各語彙の単語数を初期化 N_dv <- matrix(0, nrow = D, ncol = V) # 文書データを生成 for(d in 1:D) { # 文書ごと # トピックを生成 onehot_k <- rmultinom(n = 1, size = 1, prob = true_theta_k) |> # (カテゴリ乱数) as.vector() # one-hot符号 k <- which(onehot_k == 1) # トピック番号 # トピックを割当 true_z_d[d] <- k # 単語数を生成 N_d[d] <- sample(x = 10:20, size = 1) # 下限:上限を指定 # 各単語の語彙を初期化 w_n <- rep(NA, times = N_d[d]) for(n in 1:N_d[d]) { # 単語ごと # 語彙を生成 onehot_v <- rmultinom(n = 1, size = 1, prob = true_phi_kv[k, ]) |> # (カテゴリ乱数) as.vector() # one-hot符号 v <- which(onehot_v == 1) # 語彙番号 # 語彙を割当 w_n[n] <- v # 単語集合 # 頻度をカウント N_dv[d, v] <- N_dv[d, v] + 1 } # 単語集合を格納 w_lt[[d]] <- w_n # 文書集合 # 途中経過を表示 print(paste0("document: ", d, ", topic: ", k, ", words: ", N_d[d])) }
[1] "document: 1, topic: 1, words: 11" [1] "document: 2, topic: 1, words: 14" [1] "document: 3, topic: 3, words: 11" [1] "document: 4, topic: 3, words: 13" [1] "document: 5, topic: 3, words: 12" [1] "document: 6, topic: 4, words: 19" [1] "document: 7, topic: 3, words: 17" [1] "document: 8, topic: 3, words: 12" [1] "document: 9, topic: 4, words: 14" [1] "document: 10, topic: 4, words: 11"
個の文書
について、順番に単語集合を生成していく。
- トピック分布(カテゴリ分布)
に従い、文書のトピック
に
個のトピック
からトピック番号を割り当てる。
- 文書
の単語数
をランダムに決める。この例では、下限数・上限数を指定して一様乱数を生成する。
について、順番に語彙を生成していく。
- 割り当てられたトピック
の単語分布(カテゴリ分布)
に従い、単語
に
個の語彙
から語彙番号を割り当てる。
- 生成した語彙
に応じて出現回数
をカウントする。
- 割り当てられたトピック
- トピック分布(カテゴリ分布)
文書間で単語数が異なる(マトリクスとして扱えない)ので、文書集合(単語集合の集合) をリストとして、単語集合
のベクトルを格納する。
カテゴリ分布の乱数は、rmultinom() で生成できる。サンプルサイズの引数 n に 1、試行回数の引数 size に 1、生成確率の引数 prob にトピック分布のパラメータ または各トピックの単語分布のパラメータ
を指定する。
one-hotベクトルが生成されるので、which() で値が 1 の要素番号を得る。
作成したデータを確認する。
# 観測データを確認 head(w_lt) head(N_dv)
[[1]] [1] 5 3 1 5 5 5 4 6 6 5 6 [[2]] [1] 6 2 6 2 1 1 4 4 1 6 6 6 6 6 [[3]] [1] 4 5 2 4 6 4 5 1 5 5 5 [[4]] [1] 1 1 4 1 1 5 3 5 5 2 5 4 6 [[5]] [1] 5 3 4 4 3 5 5 4 4 1 3 3 [[6]] [1] 4 5 4 6 4 6 2 3 4 3 5 4 4 6 4 6 6 4 5
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 0 1 1 5 3 [2,] 3 2 0 2 0 7 [3,] 1 1 0 3 5 1 [4,] 4 1 1 2 4 1 [5,] 1 0 4 4 3 0 [6,] 0 1 2 8 3 5
w_lt[[d]] が 、
w_lt[[d]][n] が 、
N_dv[d, v] が に対応する。
語順を記録しない場合
語順情報(文書集合)を作成せずに語彙ごとの出現頻度を作成する。こちらの方法では、より簡易的に処理している。
設定したパラメータに従う文書データを作成する。
# 各文書のトピックを生成 true_z_d <- sample(x = 1:true_K, size = D, replace = TRUE, prob = true_theta_k) # (カテゴリ乱数) # 各文書の単語数を生成 N_d <- sample(x = 10:20, size = D, replace = TRUE) # 下限:上限を指定 # 文書ごとの各語彙の単語数を初期化 N_dv <- matrix(0, nrow = D, ncol = V) # 文書データを生成 for(d in 1:D) { # 文書ごと # 各語彙の単語数を生成 N_dv[d, ] <- rmultinom(n = 1, size = N_d[d], prob = true_phi_kv[true_z_d[d], ]) |> # (多項乱数) as.vector() # 途中経過を表示 print(paste0("document: ", d, ", topic: ", true_z_d[d], ", words: ", N_d[d])) }
[1] "document: 1, topic: 1, words: 19" [1] "document: 2, topic: 3, words: 20" [1] "document: 3, topic: 2, words: 13" [1] "document: 4, topic: 3, words: 17" [1] "document: 5, topic: 2, words: 16" [1] "document: 6, topic: 3, words: 11" [1] "document: 7, topic: 2, words: 10" [1] "document: 8, topic: 1, words: 20" [1] "document: 9, topic: 4, words: 18" [1] "document: 10, topic: 1, words: 16"
- トピック分布(カテゴリ分布)
を生成する。
- 各文書の単語数
をランダムに決める。この例では、下限数・上限数を指定して一様乱数を生成する。
- 割り当てられたトピック
に従い、
を生成する。
- 割り当てられたトピック
カテゴリ分布の乱数のインデックスは、sample() で生成できる。確率変数の引数 x にトピック番号 、試行回数の引数
size に単語数 、生成確率の引数
prob にトピック分布のパラメータ を指定する。
多項分布の乱数は、rmultinom() で生成できる。サンプルサイズの引数 n に 1、試行回数の引数 size に 、生成確率の引数
prob に各トピックの単語分布のパラメータ を指定する。
生成したデータを確認する。
# 観測データを確認 head(N_dv)
[,1] [,2] [,3] [,4] [,5] [,6] [1,] 3 1 0 1 6 8 [2,] 6 0 1 2 9 2 [3,] 1 0 1 6 0 5 [4,] 2 1 2 2 8 2 [5,] 3 2 1 8 0 2 [6,] 3 1 2 0 4 1
作図などで語順を使う場合は、ランダムに語順を決める。
# 文書集合を初期化 w_lt <- list() # 文書ごとに単語集合を作成 for(d in 1:D) { # 語彙番号を作成 v_vec <- mapply( FUN = \(v, n) {rep(v, times = n)}, # 語彙番号を複製 1:V, # 語彙番号 N_dv[d, ] # 出現回数 ) |> unlist() # 語彙を割当 w_n <- sample(x = v_vec, size = N_d[d], replace = FALSE) # 単語集合 # 単語集合を格納 w_lt[[d]] <- w_n } head(w_lt)
[[1]] [1] 6 6 1 2 5 5 5 5 1 4 1 6 6 6 5 6 6 6 5 [[2]] [1] 4 5 5 4 3 5 1 5 5 1 5 1 5 1 5 1 6 5 1 6 [[3]] [1] 6 4 4 4 6 6 4 6 6 4 4 1 3 [[4]] [1] 4 4 1 6 5 5 6 5 1 5 2 5 5 3 5 3 5 [[5]] [1] 1 4 4 4 6 2 4 6 4 1 3 4 2 1 4 4 [[6]] [1] 5 1 5 1 6 2 5 5 3 3 1
mapply() を使って 1 から V の語彙番号を出現回数 N_dv[d, ] に応じてそれぞれ複製する。リストが出力されるので unlist() でベクトルに変換する。
N_d[d] 個の語彙番号を sample() でランダムに入れ替えて単語集合のベクトルとする。
文書ごとに単語集合のベクトルを作成して、文書集合のリストに格納していく。
各種推論アルゴリズムでは、文書集合 から得られる語彙頻度データ
のみを用いてパラメータ類を推定する。
データの可視化
次は、生成した真の分布や文書データのグラフを作成する。
データの集計
文書や語彙に関する単語数を集計する。
# 各文書の単語数を取得 N_d <- rowSums(N_dv) N_d
[1] 19 20 13 17 16 11 10 20 18 16
各文書の単語数 、
は
N_dv の行ごとの和に対応する。
文書集合に関する値を集計する。
# 文書数を取得 D <- nrow(N_dv) D <- length(N_d) # 語彙数を取得 V <- ncol(N_dv) # 全文書の単語数を取得 N <- sum(N_dv) N <- sum(N_d) D; V; N
[1] 10 [1] 6 [1] 160
文書数 は
N_dv の行数または N_d の要素数、語彙数 は
N_dv の列数に対応する。
全文書の単語数(総単語数) は
N_dv, N_d それぞれの全ての要素の和に対応する。
真の分布の図
真の分布(パラメータ)をグラフで確認する。
トピック分布
トピック分布の描画用のデータフレームを作成する。
# トピック分布を格納 true_theta_df <- tibble::tibble( k = 1:true_K, # トピック番号 prob = true_theta_k # 生成確率 ) true_theta_df
# A tibble: 4 × 2
k prob
<int> <dbl>
1 1 0.251
2 2 0.0711
3 3 0.431
4 4 0.247
トピック番号 とパラメータ
を格納する。
トピック分布のグラフを作成する。
# ラベル用の文字列を作成 param_label <- paste0( "alpha == ", true_alpha ) # 一様な値の場合 param_label <- paste0( "alpha == (list(", paste0(true_alpha_k, collapse = ", "), "))" ) # 多様な値の場合 # トピック分布を作図 ggplot() + geom_bar(data = true_theta_df, mapping = aes(x = k, y = prob, fill = factor(k)), stat = "identity", show.legend = FALSE) + # 確率 labs(title = "topic distribution (unigram model)", subtitle = parse(text = param_label), x = expression(topic ~ (k)), y = expression(probability ~ (theta[k])))
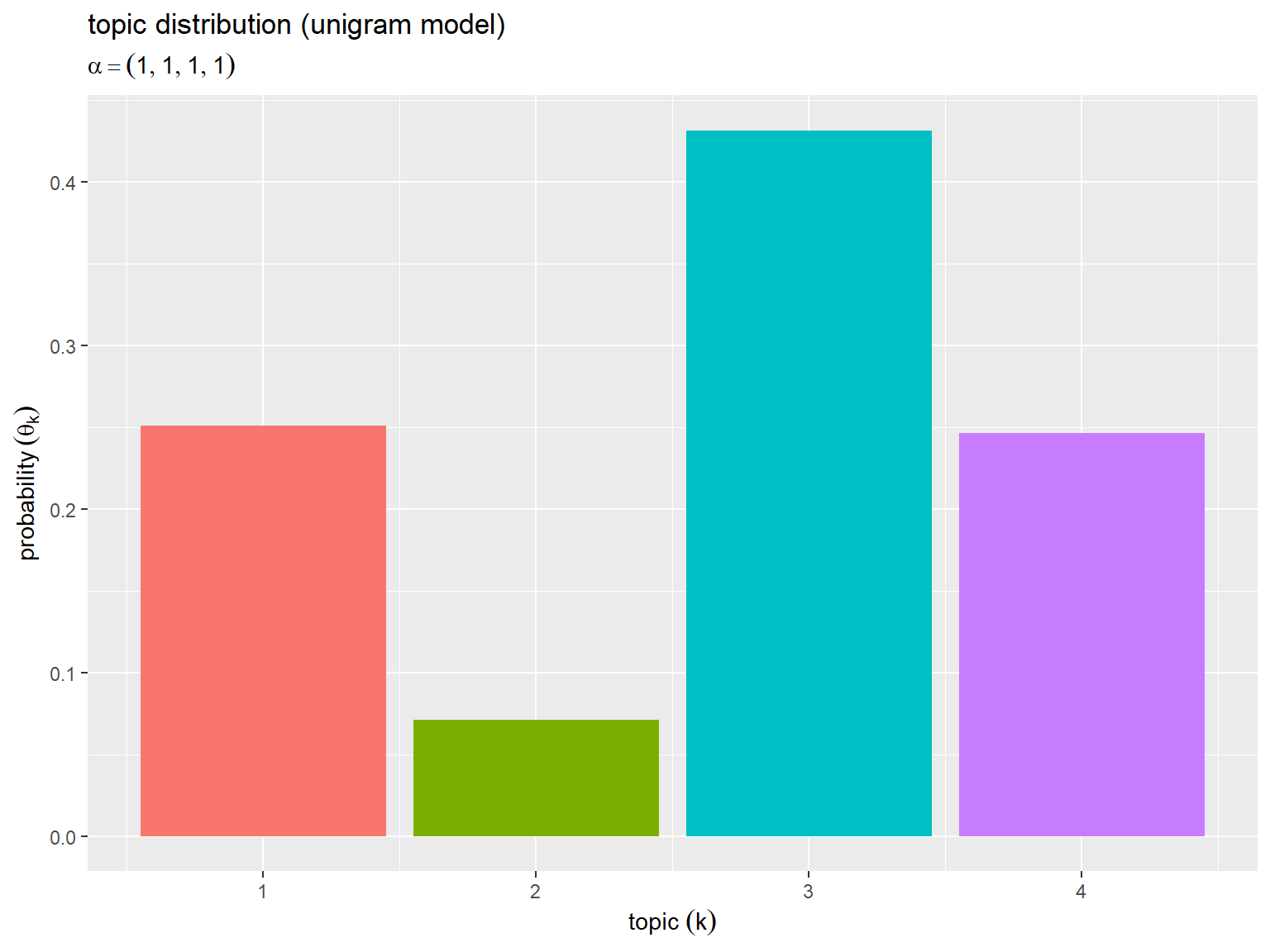
横軸はトピック番号 、縦軸は各トピックの割り当て確率
を表す。
以降の図も含めて、トピックごとにバーを色付けしている。
単語分布
単語分布の描画用のデータフレームを作成する。
# 単語分布を格納 true_phi_df <- true_phi_kv |> tibble::as_tibble(.name_repair = ~paste0("V", 1:V)) |> # 語彙番号の列名を設定 tibble::add_column( k = 1:true_K # トピック番号 ) |> tidyr::pivot_longer( cols = !k, names_to = "v", # 列名を語彙番号に変換 names_prefix = "V", names_transform = list(v = as.numeric), values_to = "prob" # 生成確率を1列に結合 ) true_phi_df
# A tibble: 24 × 3
k v prob
<int> <dbl> <dbl>
1 1 1 0.256
2 1 2 0.0764
3 1 3 0.0224
4 1 4 0.0928
5 1 5 0.163
6 1 6 0.389
7 2 1 0.104
8 2 2 0.202
9 2 3 0.0503
10 2 4 0.411
# ℹ 14 more rows
トピックごとの確率データ true_phi_kv をデータフレームに変換して、トピック番号 と語彙番号
、パラメータ
を格納する。
単語分布のグラフを作成する。
# ラベル用の文字列を作成 param_label <- paste0( "beta == ", true_beta ) # 一様な値の場合 param_label <- paste0( "beta == (list(", paste0(true_beta_v, collapse = ", "), "))" ) # 多様な値の場合 # 単語分布を作図 ggplot() + geom_bar(data = true_phi_df, mapping = aes(x = v, y = prob, fill = factor(k)), stat = "identity", show.legend = FALSE) + # 確率 facet_wrap(k ~ ., labeller = label_bquote(topic ~ (k): .(k)), scales = "free_x") + # トピックごとに分割 labs(title = "word distribution (unigram model)", subtitle = parse(text = param_label), x = expression(vocabulary ~ (v)), y = expression(probability ~ (phi[kv])))
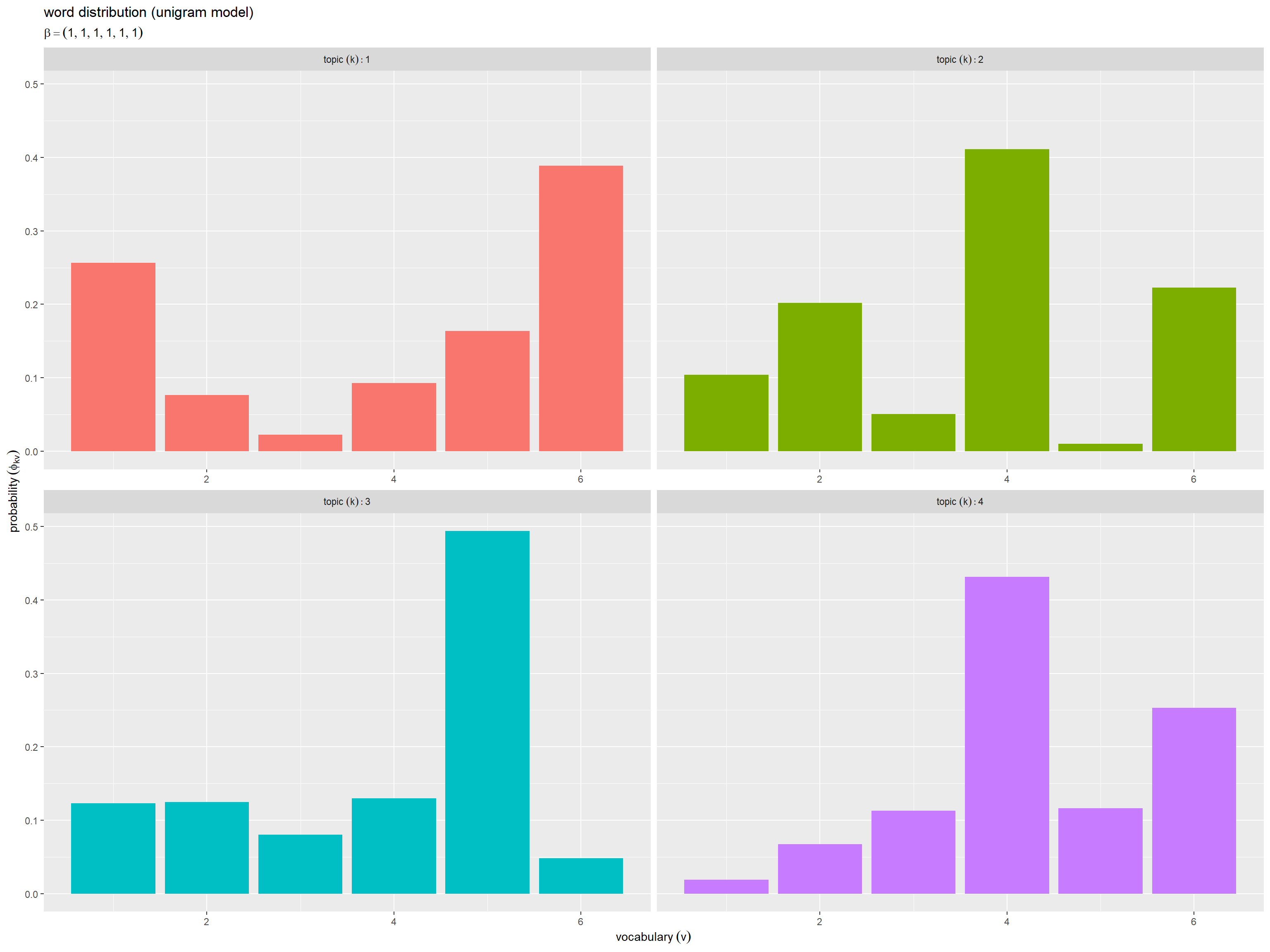
横軸は語彙番号 、縦軸は各トピックにおける各語彙の出現確率
を表す。トピックごとにグラフを縦横に並べている。
文書データの図
文書集合(頻度データ)とトピック集合をグラフで確認する。
各文書における各語彙の単語数
文書ごとの語彙頻度の描画用のデータフレームを作成する。
# 文書・語彙ごとの単語数を格納 Ndv_df <- N_dv |> tibble::as_tibble(.name_repair = ~paste0("V", 1:V)) |> # 語彙番号の列名を設定 tibble::add_column( d = 1:D, # 文書番号 k = true_z_d, # トピック番号 ) |> tidyr::pivot_longer( cols = !c(d, k), names_to = "v", # 列名を語彙番号に変換 names_prefix = "V", names_transform = list(v = as.numeric), values_to = "freq" # 語彙頻度を1列に結合 ) Ndv_df
# A tibble: 60 × 4
d k v freq
<int> <int> <dbl> <dbl>
1 1 1 1 3
2 1 1 2 1
3 1 1 3 0
4 1 1 4 1
5 1 1 5 6
6 1 1 6 8
7 2 3 1 6
8 2 3 2 0
9 2 3 3 1
10 2 3 4 2
# ℹ 50 more rows
文書ごとの語彙頻度データ N_dv をデータフレームに変換して、文書番号 とトピック番号
、語彙番号
、単語数
を格納する。
文書ごとの単語数の描画用のデータフレームを作成する。
# 文書ごとの単語数を格納 Nd_df <- tibble::tibble( d = 1:D, # 文書番号 k = true_z_d, # トピック番号 cnt = N_d, # 単語数 label = paste0( "list(", "z[d] == ", k, ", ", "N[d] == ", cnt, ")" ) ) Nd_df
# A tibble: 10 × 4
d k cnt label
<int> <int> <dbl> <chr>
1 1 1 19 list(z[d] == 1, N[d] == 19)
2 2 3 20 list(z[d] == 3, N[d] == 20)
3 3 2 13 list(z[d] == 2, N[d] == 13)
4 4 3 17 list(z[d] == 3, N[d] == 17)
5 5 2 16 list(z[d] == 2, N[d] == 16)
6 6 3 11 list(z[d] == 3, N[d] == 11)
7 7 2 10 list(z[d] == 2, N[d] == 10)
8 8 1 20 list(z[d] == 1, N[d] == 20)
9 9 4 18 list(z[d] == 4, N[d] == 18)
10 10 1 16 list(z[d] == 1, N[d] == 16)
文書番号 と単語数
を格納する。また、単語数ラベル用の文字列を作成する。
文書ごとの語彙頻度のグラフを作成する。
# ラベル用の文字列を作成 param_label <- paste0( "list(", "D == ", D, ", ", "V == ", V, ", ", "K == ", true_K, ", ", "N == ", N, ")" ) # 文書・語彙ごとの単語数を作図 ggplot() + geom_bar(data = Ndv_df, mapping = aes(x = v, y = freq, fill = factor(k)), stat = "identity") + # 頻度 geom_label(data = Nd_df, mapping = aes(x = -Inf, y = Inf, label = label), parse = TRUE, hjust = 0, vjust = 1, alpha = 0.5) + # 単語数 facet_wrap(d ~ ., labeller = label_bquote(document ~ (d): .(d))) + # 文書ごとに分割 guides(fill = "none") + # 凡例の体裁 labs(title = "document data (unigram model)", subtitle = parse(text = param_label), x = expression(vocabulary ~ (v)), y = expression(frequency ~ (N[dv])))
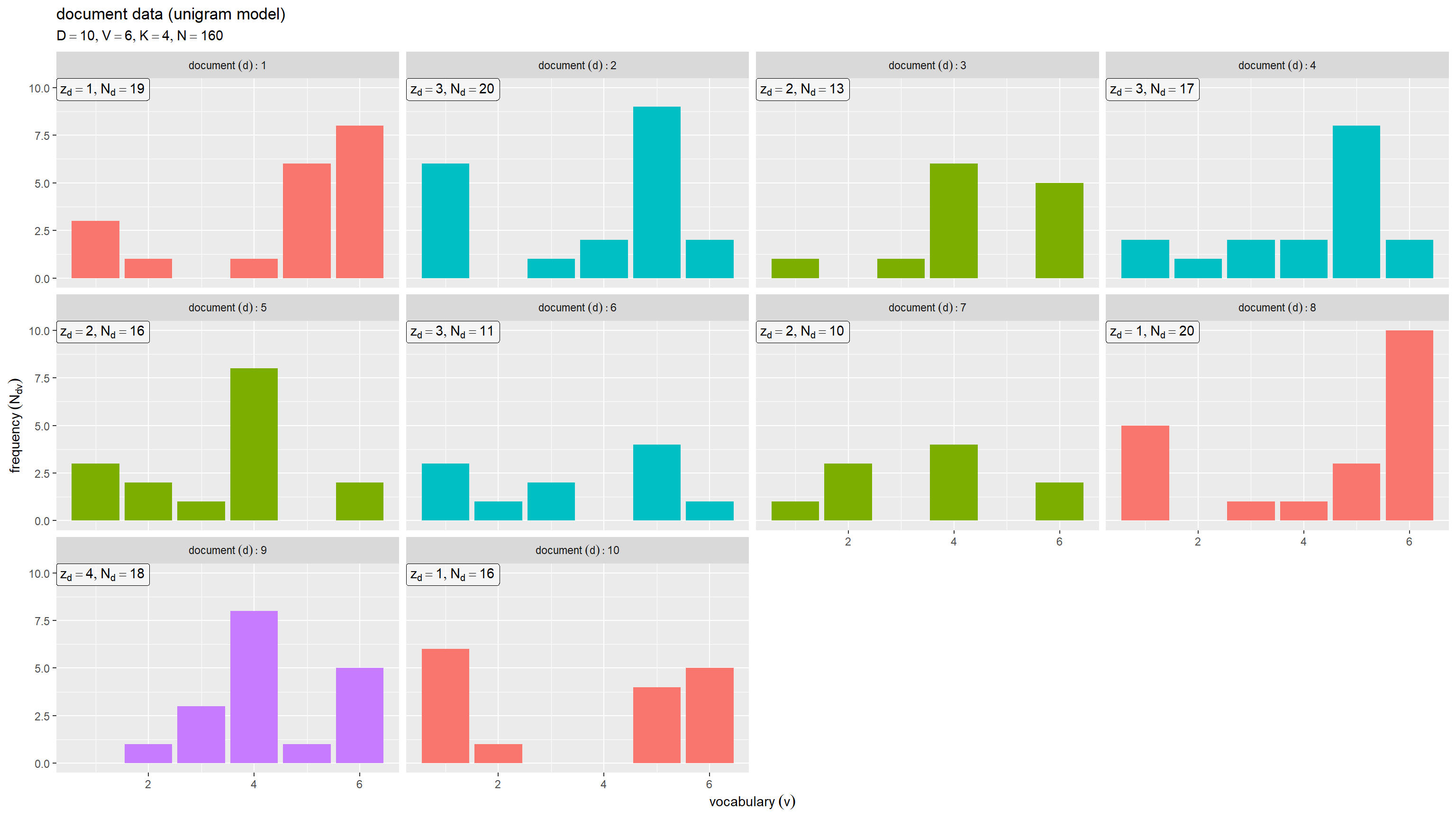
横軸は語彙番号 、縦軸は文書ごとの各語彙の出現回数
を表す。文書ごとにグラフを縦横に並べている。
各文書の単語数 が増えるとそれぞれ単語分布の形状に近付く。
各トピックの文書数
トピックごとの文書数の描画用のデータフレームを作成する。
# トピックごとの文書数を集計 true_Dk_df <- dplyr::bind_rows( tibble::tibble( k = 1:true_K, cnt = 0 ), # 未観測トピックの補完用 tibble::tibble( k = true_z_d, # トピック番号 cnt = 1 # 集計用の値 ) ) |> dplyr::reframe( cnt = sum(cnt), .by = k # 各トピックの文書数を集計 ) true_Dk_df
# A tibble: 4 × 2
k cnt
<int> <dbl>
1 1 3
2 2 3
3 3 3
4 4 1
文書のトピック を格納して、トピック番号
ごとに文書数
をカウントする。
トピックごとの文書数のグラフを作成する。
# ラベル用の文字列を作成 param_label <- paste0( "list(", "D == ", D, ", ", "K == ", true_K, ")" ) # トピックごとの文書数を作図 ggplot() + geom_bar(data = true_Dk_df, mapping = aes(x = k, y = cnt, fill = factor(k)), stat = "identity") + # 度数 guides(fill = "none") + # 図の体裁 labs(title = "document data (unigram model)", subtitle = parse(text = param_label), x = expression(topic ~ (k)), y = expression(count ~ (D[k])))
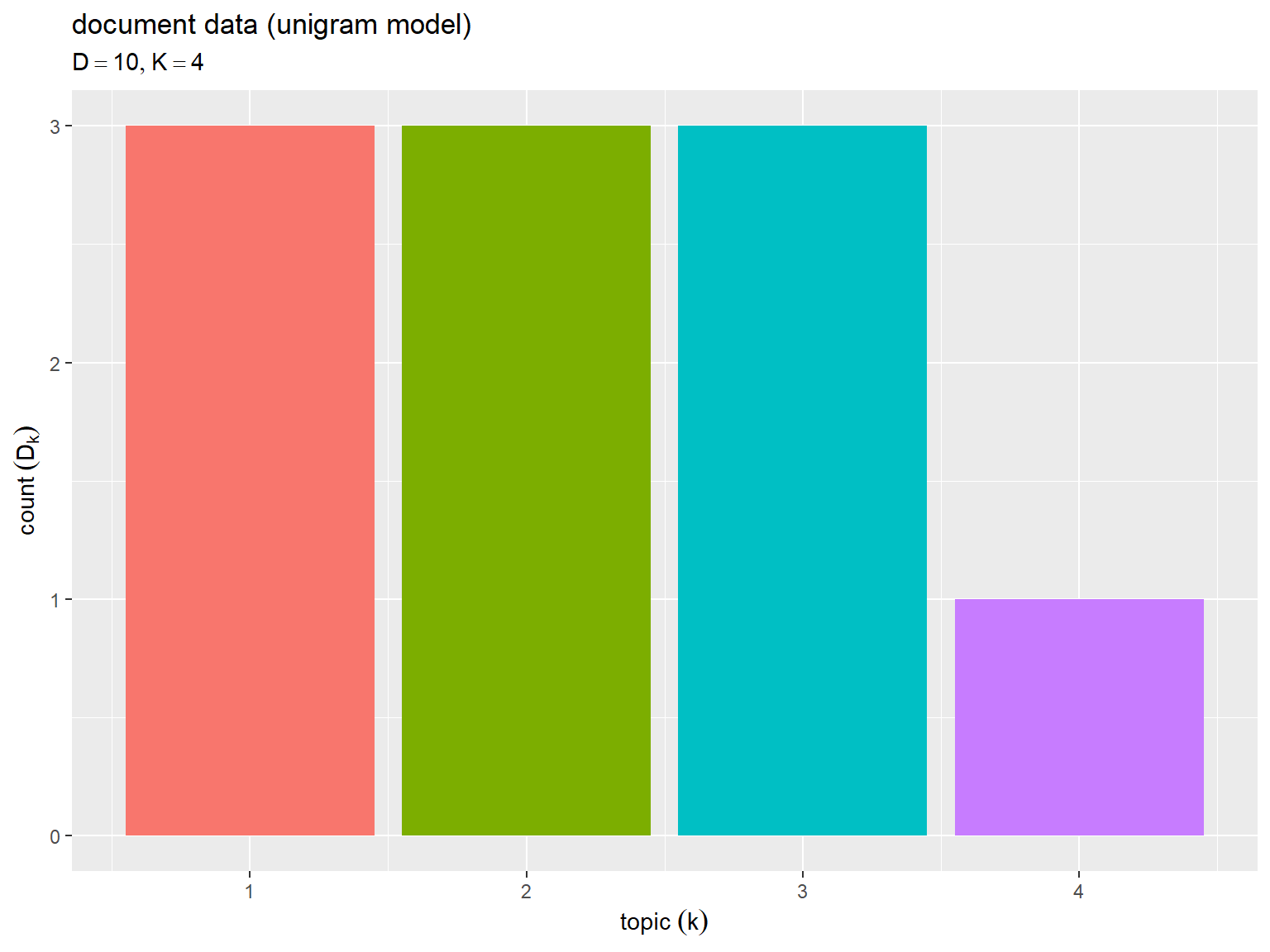
横軸はトピック番号 、縦軸は各トピックが割り当てられた文書数
を表す。
文書数 が増えるとトピック分布の形状に近付く。
各文書の単語数
文書ごとの単語数のグラフを作成する。
# ラベル用の文字列を作成 param_label <- paste0( "list(", "D == ", D, ", ", "N == ", N, ")" ) # 文書ごとの単語数を作図 ggplot() + geom_bar(data = Nd_df, mapping = aes(x = d, y = cnt), stat = "identity") + # 頻度 labs(title = "document data", subtitle = parse(text = param_label), x = expression(vocabulary ~ (d)), y = expression(count ~ (N[d])))
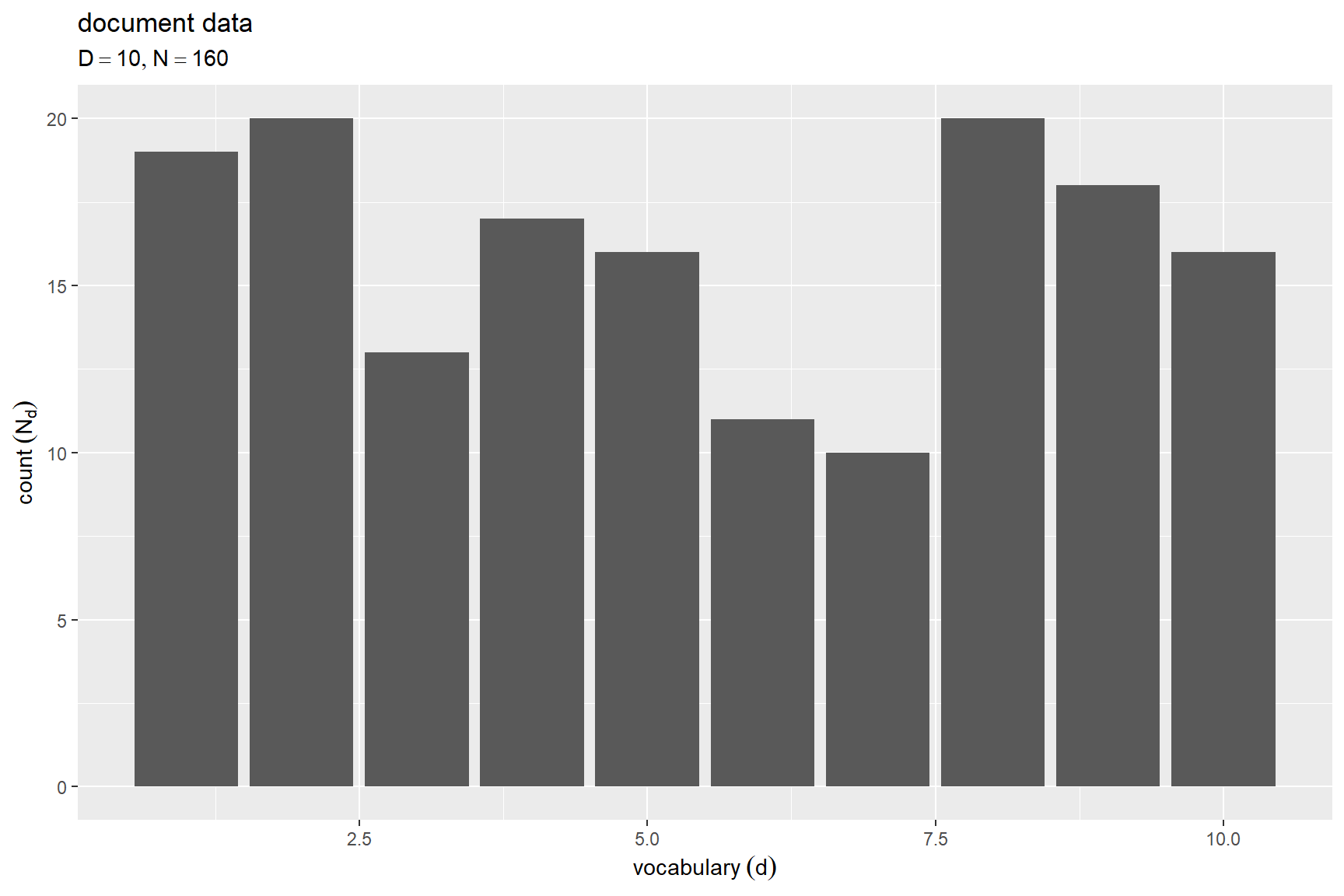
横軸は文書番号 、縦軸は各文書の単語数
を表す。
この例では、一様分布に従い設定している。
各トピックの文書における各語彙の単語数
トピックごとの語彙頻度の描画用のデータフレームを作成する。
# トピック・語彙ごとの単語数を集計 Nkv_df <- Ndv_df |> dplyr::reframe( freq = sum(freq), .by = c(k, v), # トピックの単語数を集計 ) |> dplyr::arrange(k, v) # 確認用 Nkv_df
# A tibble: 24 × 3
k v freq
<int> <dbl> <dbl>
1 1 1 14
2 1 2 2
3 1 3 1
4 1 4 2
5 1 5 13
6 1 6 23
7 2 1 5
8 2 2 5
9 2 3 2
10 2 4 18
# ℹ 14 more rows
文書ごとの語彙頻度データ Ndv_df をトピック番号 と語彙番号
ごとに(
である
個の文書の)語彙頻度の和
を計算する。
トピックごとの単語数の描画用のデータフレームを作成する。
# トピックごとの単語数を集計 Nk_df <- Nkv_df|> dplyr::reframe( cnt = sum(freq), .by = k, # 各トピックの単語数を集計 ) |> dplyr::right_join( true_Dk_df |> dplyr::select(k, Dk = cnt), by = "k" ) |> # ラベル用の値を結合 dplyr::mutate(cnt = tidyr::replace_na(cnt, replace = 0)) |> # 未観測トピックの補完用 dplyr::mutate( label = paste0( "list(", "D[k] == ", Dk, ", ", "N[k] == ", cnt, ")" ) ) Nk_df
# A tibble: 4 × 4
k cnt Dk label
<int> <dbl> <dbl> <chr>
1 1 55 3 list(D[k] == 3, N[k] == 55)
2 2 39 3 list(D[k] == 3, N[k] == 39)
3 3 48 3 list(D[k] == 3, N[k] == 48)
4 4 18 1 list(D[k] == 1, N[k] == 18)
トピックごとの語彙頻度データ Nkv_df をトピック番号 ごとに語彙頻度の和
を計算する。
トピックごとの語彙頻度をグラフで確認する。
# ラベル用の文字列を作成 param_label <- paste0( "list(", "D == ", D, ", ", "V == ", V, ", ", "K == ", true_K, ", ", "N == ", N, ")" ) # トピックごとの単語数を作図 ggplot() + geom_bar(data = Nkv_df, mapping = aes(x = v, y = freq, fill = factor(k)), stat = "identity") + # 頻度 geom_label(data = Nk_df, mapping = aes(x = -Inf, y = Inf, label = label), parse = TRUE, hjust = 0, vjust = 1, alpha = 0.5) + # 文書数・単語数 facet_wrap(k ~ ., labeller = label_bquote(topic ~ (k): .(k))) + # トピックごとに分割 guides(fill = "none") + # 図の体裁 labs(title = "document data (unigram model)", subtitle = parse(text = param_label), x = expression(vocabulary ~ (v)), y = expression(frequency ~ (N[kv])))
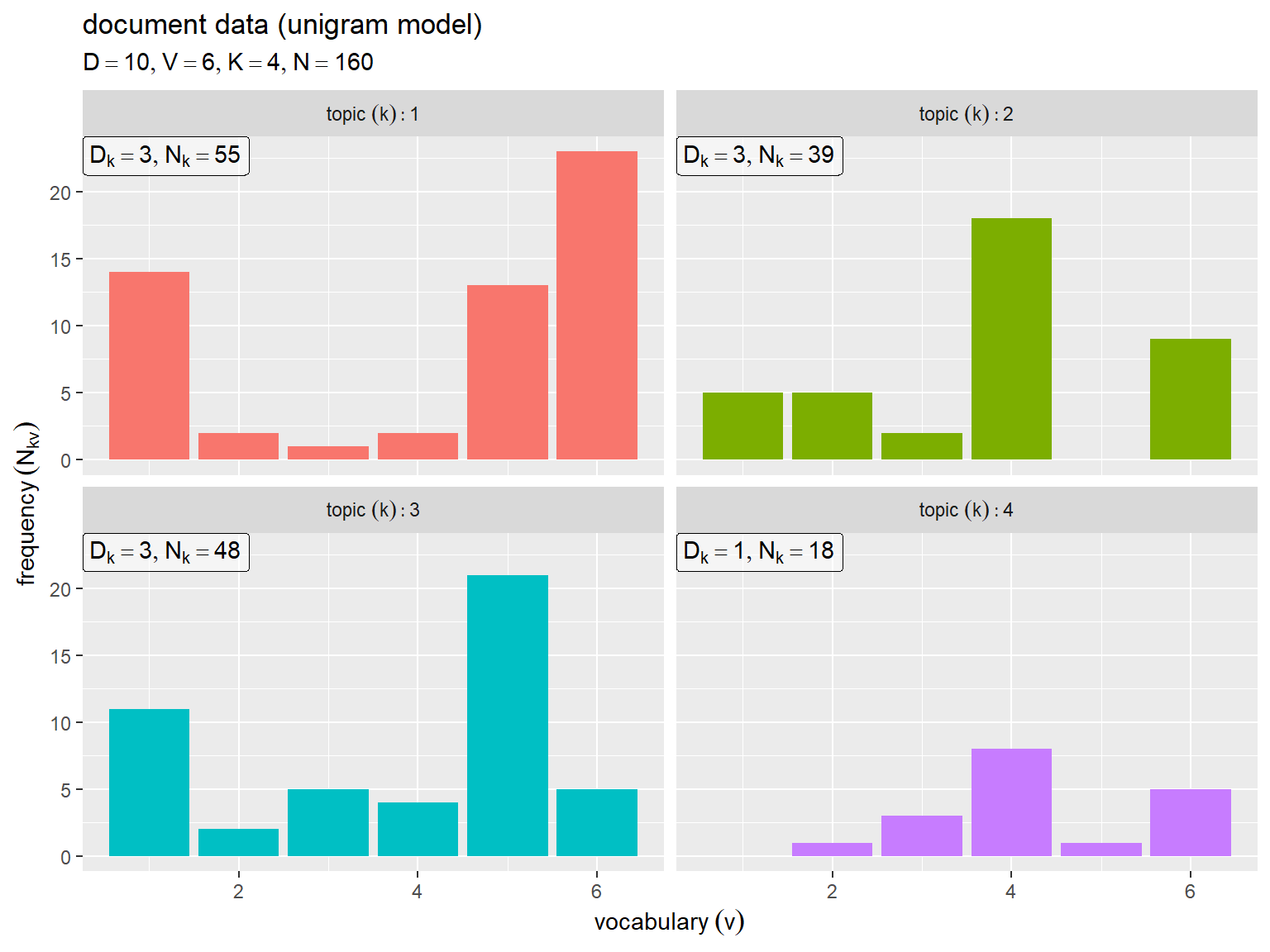
横軸は語彙番号 、縦軸は各トピックが割り当てられた文書における各語彙の出現回数
を表す。
文書数 と全文書での単語数
が増えると単語分布の形状に近付く。
この記事では、混合ユニグラムモデルの生成モデルを実装して、各種推論アルゴリズムに用いる人工データを作成した。 次の記事からは、3つの推論アルゴリズムを確認していく。
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
- 2024.05.26:加筆修正の際に「混合ユニグラムモデルの最尤推定の実装」から記事を分割しました。
どーでもいー話ですが、この記事は加筆修正なのか新規なのか微妙に悩みました。元々書いていた(3.3節の記事内の)3.1節相当の内容やPython版の3.1節の記事よりも最近書いた2.2節の記事からの方が流用したところが多い気がします。で、この記事を書きながら2.2節の記事も書き換えたり。やっぱりどーでもいーですね。
投稿日の前日に公開されたダンス動画をどうぞ。
最近アメフラにハマったきっかけの曲の1つです。ノリの良いメロディに可愛い振り付けでときめいた曲のダンス動画がアップされて筆も踊ります。
この記事の目的は全て既知のデータを用意しようなんですがね。
【次節の内容】
- 数式読解編
混合ユニグラムモデルに対応する最尤推定を数式で確認します。
- スクラッチ実装編
混合ユニグラムモデルに対する最尤推定をプログラムで確認します。
トピックモデルの生成モデルをプログラムで確認します。