はじめに
機械学習プロフェッショナルシリーズの『トピックモデル』の勉強時に理解の助けになったことや勉強会用レジュメのまとめです。
この記事では、R言語でトピックモデルを変分ベイズ推定するLDA(潜在ディリクレ配分モデル)を行う方法について書いています。Rの基本的な関数で参考書のアルゴリズム4.2を組むことで、理論をコード・処理の面から理解しようというものです。
パラメータの更新式の導出などはこの記事をご参照ください。
【前節の内容】
【他の節の内容】
【この節の内容】
・コード全体
・テキスト処理
# 利用パッケージ library(RMeCab) library(tidyverse) ### テキスト処理 # 抽出しない単語を指定 stop_words <- "[a-z]" # 小文字のアルファベットを含む語 # 形態素解析 mecab_df <- docDF("フォルダ名", type = 1) # テキストファイルの保存先を指定する # 文書dの語彙vの出現回数(N_dv)の集合 N_dv <- mecab_df %>% filter(grepl("名詞|形容詞|^動詞", POS1)) %>% # 抽出する品詞(大分類)を指定する filter(grepl("一般|^自立", POS2)) %>% # 抽出する品詞(細分類)を指定する filter(!grepl(stop_words, TERM)) %>% # ストップワードを除く select(-c(TERM, POS1, POS2)) %>% # 数値列のみを残す filter(apply(., 1, sum) >= 5) %>% # 抽出する総出現回数を指定する t() # 転置 # 確認用の行列名 dimnames(N_dv) <- list(paste0("d=", 1:nrow(N_dv)), # 行名 paste0("v=", 1:ncol(N_dv))) # 列名 # 文書dの単語数(N_d)のベクトル N_d <- apply(N_dv, 1, sum) # 行方向に和をとる # 文書数(D) D <- nrow(N_dv) # 総語彙数(V) V <- ncol(N_dv)
・パラメータの初期設定
### パラメータの初期設定 # トピック数(K) K <- 4 # 任意の値を指定する # トピックの変分事後分布(q_dvk)の集合 q_dvk <- array(0, dim = c(D, V, K), dimnames = list(paste0("d=", 1:D), # 確認用の次元名 paste0("v=", 1:V), paste0("k=", 1:K))) # 事前分布のパラメータ(alpha, beta) alpha <- 2 # 任意の値を指定する beta <- 2 # 任意の値を指定する # トピック分布の変分事後分布のパラメータ(alpha_dk)の集合 alpha_dk <- seq(1, 3, 0.01) %>% # 任意の範囲を指定する sample(D * K, replace = TRUE) %>% # 値をランダムに生成 matrix(nrow = D, ncol = K, # 次元の設定 dimnames = list(paste0("d=", 1:D), # 行名 paste0("k=", 1:K))) # 列名 # 単語分布の変分事後分布のパラメータ(beta_kv)の集合 beta_kv <- seq(1, 3, 0.01) %>% # 任意の範囲を指定する sample(K * V, replace = TRUE) %>% # 値をランダムに生成 matrix(nrow = K, ncol = V, # 次元の設定 dimnames = list(paste0("k=", 1:K), # 行名 paste0("v=", 1:V))) # 列名
・変分ベイズ推定
### 変分ベイズ推定 # 推移の確認用 trace_alpha <- alpha_dk[1, ] trace_beta <- beta_kv[1, ] for(i in 1:50) { # 任意の回数を指定する # パラメータを初期化 new_alpha_dk <- matrix(data = alpha, nrow = D, ncol = K, dimnames = list(paste0("d=", 1:D), paste0("k=", 1:K))) new_beta_kv <- matrix(data = beta, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V))) for(d in 1:D) { ## (各文書) for(v in 1:V) { ## (各語彙) for(k in 1:K) { ## (各トピック) # 負担率を計算 tmp_q_alpha <- digamma(alpha_dk[d, k]) - digamma(sum(alpha_dk[d, ])) tmp_q_beta <- N_dv[d, v] * (digamma(beta_kv[k, v]) - digamma(sum(beta_kv[k, ]))) q_dvk[d, v, k] <- exp(tmp_q_alpha + tmp_q_beta) } # 負担率を正規化 q_dvk[d, v, ] <- q_dvk[d, v, ] / sum(q_dvk[d, v, ]) for(k in 1:K) { ## (各トピック(続き)) # alpha_dkを更新 new_alpha_dk[d, k] <- new_alpha_dk[d, k] + q_dvk[d, v, k] # beta_kvを更新 new_beta_kv[k, v] <- new_beta_kv[k, v] + q_dvk[d, v, k] * N_dv[d, v] } ## (/各トピック) } ## (/各語彙) } ## (/各文書) # パラメータを更新 alpha_dk <- new_alpha_dk beta_kv <- new_beta_kv # 推移の確認用 trace_alpha <- rbind(trace_alpha, alpha_dk[1, ]) trace_beta <- rbind(trace_beta, beta_kv[1, ]) }
・コードの解説
・利用パッケージ
# 利用パッケージ library(RMeCab) library(tidyverse)
形態素解析のためのRMeCab::docDF()と、グラフ作成時のtidyr::gather()、ggplot2関連の関数以外にライブラリの読み込みが必要なのはdplyrのみ。(面倒なのでtidyversパッケージを読み込んでいる)
その他テキスト処理の部分は3.3節の記事を参照のこと。
・パラメータの初期設定
・トピック数
# トピック数(K) K <- 4 # 任意の値を指定する
任意のトピック数を指定する。
・負担率
# トピックの変分事後分布(q_dvk)の集合 q_dvk <- array(0, dim = c(D, V, K), dimnames = list(paste0("d=", 1:D), # 確認用の次元名 paste0("v=", 1:V), paste0("k=", 1:K)))
ここでは負担率$q_{dnk}$を単語レベルではなく語彙レベルで扱うため、$q_{dnk}$をq_dvkとして扱う。
for()文の中で添え字で指定して1要素ずつ代入していくため、受け皿として事前に用意しておく。
トピックモデルの負担率$q_{dvk}$は3次元の変数なので、array()を使って配列として扱う。初期値を0として、引数dim = c(D, V, K)で各次元の要素数を$D, V, K$個とする。
変数に付ける行列名等は目で確認するためのもので、付けなくても処理に影響しない。他の変数についても同様である。
・事前分布のパラメータ
# 事前分布のパラメータ(alpha, beta) alpha <- 2 # 任意の値を指定する beta <- 2 # 任意の値を指定する
事前分布$p(\boldsymbol{\theta} | \alpha), p(\boldsymbol{\Phi} | \beta)$のパラメータ$\alpha, \beta$の値を任意で設定する。
この値は更新パラメータの初期化時の値として用いる。
・トピック分布の変分事後分布のパラメータ
# トピック分布の変分事後分布のパラメータ(alpha_dk)の集合 alpha_dk <- seq(1, 3, 0.01) %>% # 任意の範囲を指定する sample(D * K, replace = TRUE) %>% # 値をランダムに生成 matrix(nrow = D, ncol = K, # 次元の設定 dimnames = list(paste0("d=", 1:D), # 行名 paste0("k=", 1:K))) # 列名
seq(最小値, 最大値, 間隔)で初期値として取り得る値の範囲を任意で指定する。そこから、sample()でランダムに$D * K$個の値をとる。その数値ベクトルをmatrix()で$D$行$K$列の行列とする。
・単語分布の変分事後分布のパラメータ
# 単語分布の変分事後分布のパラメータ(beta_kv)の集合 beta_kv <- seq(1, 3, 0.01) %>% # 任意の範囲を指定する sample(K * V, replace = TRUE) %>% # 値をランダムに生成 matrix(nrow = K, ncol = V, # 次元の設定 dimnames = list(paste0("k=", 1:K), # 行名 paste0("v=", 1:V))) # 列名
$\alpha$と同様に、初期値をランダムに取る$K$行$V$列の行列を作る。
・変分ベイズ推定
ここからは、for()ループ内の処理について説明する。
・ハイパーパラメータの初期化
# パラメータを初期化 new_alpha_dk <- matrix(data = alpha, nrow = D, ncol = K, dimnames = list(paste0("d=", 1:D), paste0("k=", 1:K))) new_beta_kv <- matrix(data = beta, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V)))
各パラメーターの更新時に用いる変数を作成する。
また、次ステップに入る前に事前分布のパラメータとして設定した値でそれぞれ初期化する。
・負担率の計算
for(k in 1:K) { ## (各トピック) # 負担率(q_dvk)を計算 tmp_q_alpha <- digamma(alpha_dk[d, k]) - digamma(sum(alpha_dk[d, ])) tmp_q_beta <- N_dv[d, v] * (digamma(beta_kv[k, v]) - digamma(sum(beta_kv[k, ]))) q_dvk[d, v, k] <- exp(tmp_q_alpha + tmp_q_beta) } # 負担率を正規化 q_dvk[d, v, ] <- q_dvk[d, v, ] / sum(q_dvk[d, v, ])
負担率の計算を
で行う。
ただしこの式がイコールの関係でないことから、そのままの値を用いずに$\sum_{k=1}^K q_{dk} = 1$となるように正規化した値を用いる。正規化処理の時点で1~Kまでの要素が必要であるため、for(k in 1:K)のループ処理を先に回し切り、正規化後のパラメータの更新では、もう一度for(k in 1:K)のループ処理を行う。
・ハイパーパラメータ:$\alpha_{dk}$の更新
# alpha_dkを更新 new_alpha_dk[d, k] <- new_alpha_dk[d, k] + q_dvk[d, v, k]
$\alpha$の更新式
の計算を行い値を求める。$\sum_{v=1}^V$については、for(v in 1:V)によって各要素に$V$回繰り返し加算されることがこれに相当する。
・ハイパーパラメータ:$\beta_{kv}$の更新
# beta_kvを更新 new_beta_kv[k, v] <- new_beta_kv[k, v] + q_dvk[d, v, k] * N_dv[d, v]
$\beta_{kv}$も同様に、更新式
の計算を行い値を求める。
・ハイパーパラメータの更新
# パラメータを更新 alpha_dk <- new_alpha_dk beta_kv <- new_beta_kv
各パラメータを次ステップでの計算に用いるために移す。
この推定処理を指定した回数繰り返す。(本当は収束条件を満たすまで繰り返すようにしたい…)
・ハイパーパラメータの推定結果の確認
・トピック分布のパラメータ
## トピック分布のパラメータ # データフレームを作成 alpha_df_wide <- cbind(as.data.frame(alpha_dk), as.factor(1:D)) # データフレームをlong型に変換 colnames(alpha_df_wide) <- c(1:K, "doc") # key用に行名を付与 alpha_df_long <- gather(alpha_df_wide, key = "topic", value = "alpha", -doc) # 変換 alpha_df_long$topic <- alpha_df_long$topic %>% # 文字列から因子に変換 as.numeric() %>% as.factor() # 作図 ggplot(data = alpha_df_long, mapping = aes(x = topic, y = alpha, fill = topic)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap(~ doc, labeller = label_both) + # グラフの分割 labs(title = "LDA") # タイトル
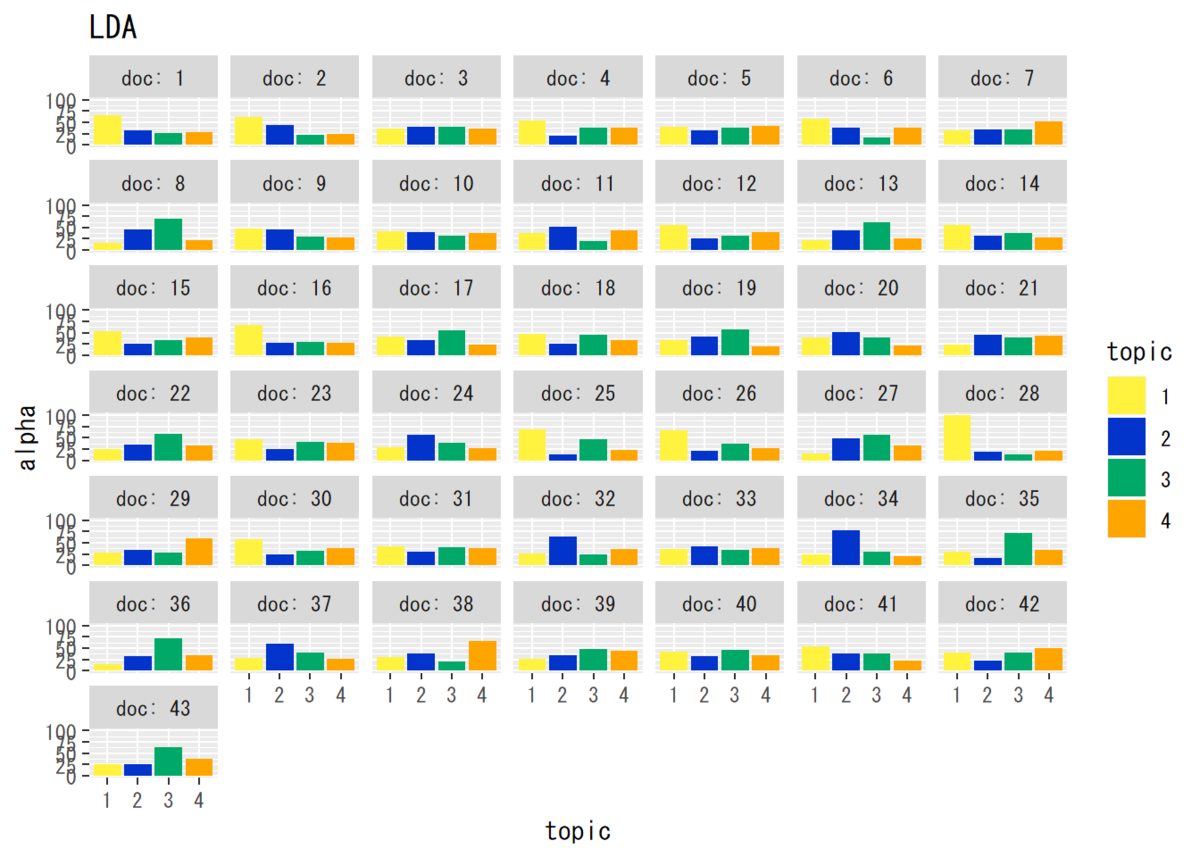
・単語分布のパラメータ
## 単語分布のパラメータ # データフレームを作成 beta_df_wide <- cbind(as.data.frame(beta_kv), as.factor(1:K)) # データフレームをlong型に変換 colnames(beta_df_wide) <- c(1:V, "topic") # key用に行名を付与 beta_df_long <- gather(beta_df_wide, key = "word", value = "beta", -topic) # 変換 beta_df_long$word <- beta_df_long$word %>% # 文字列から因子に変換 as.numeric() %>% as.factor() # 作図 ggplot(data = beta_df_long, mapping = aes(x = word, y = beta, fill = word)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap(~ topic, labeller = label_both) + # グラフを分割 theme(legend.position = "none") + # 凡例 labs(title = "LDA") # タイトル

最尤推定ではパラメータを点推定したが、変分ベイズ推定ではハイパーパラメータを推定することでパラメータを分布推定している。
・パラメータの推定結果(平均値)の確認
ディリクレ分布の平均値の計算式
より、パラメータの平均値の分布を確認する。
・トピック分布(平均値)
## トピック分布(平均値) #パラメータの平均値を算出 theta_dk <- matrix(nrow = D, ncol = K) for(d in 1:D) { theta_dk[d, ] <- alpha_dk[d, ] / sum(alpha_dk[d, ]) } # データフレームを作成 theta_df_wide <- cbind(as.data.frame(theta_dk), as.factor(1:D)) # 文書番号の列を加える # データフレームをlong型に変換 colnames(theta_df_wide) <- c(1:K, "doc") # key用に行名を付与 theta_df_long <- gather(theta_df_wide, key = "topic", value = "prob", -doc) # 変換 theta_df_long$topic <- theta_df_long$topic %>% # 文字列から因子に変換 as.numeric() %>% as.factor() # 作図 ggplot(data = theta_df_long, mapping = aes(x = topic, y = prob, fill = topic)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap(~ doc, labeller = label_both) + # グラフの分割 labs(title = "LDA") # タイトル
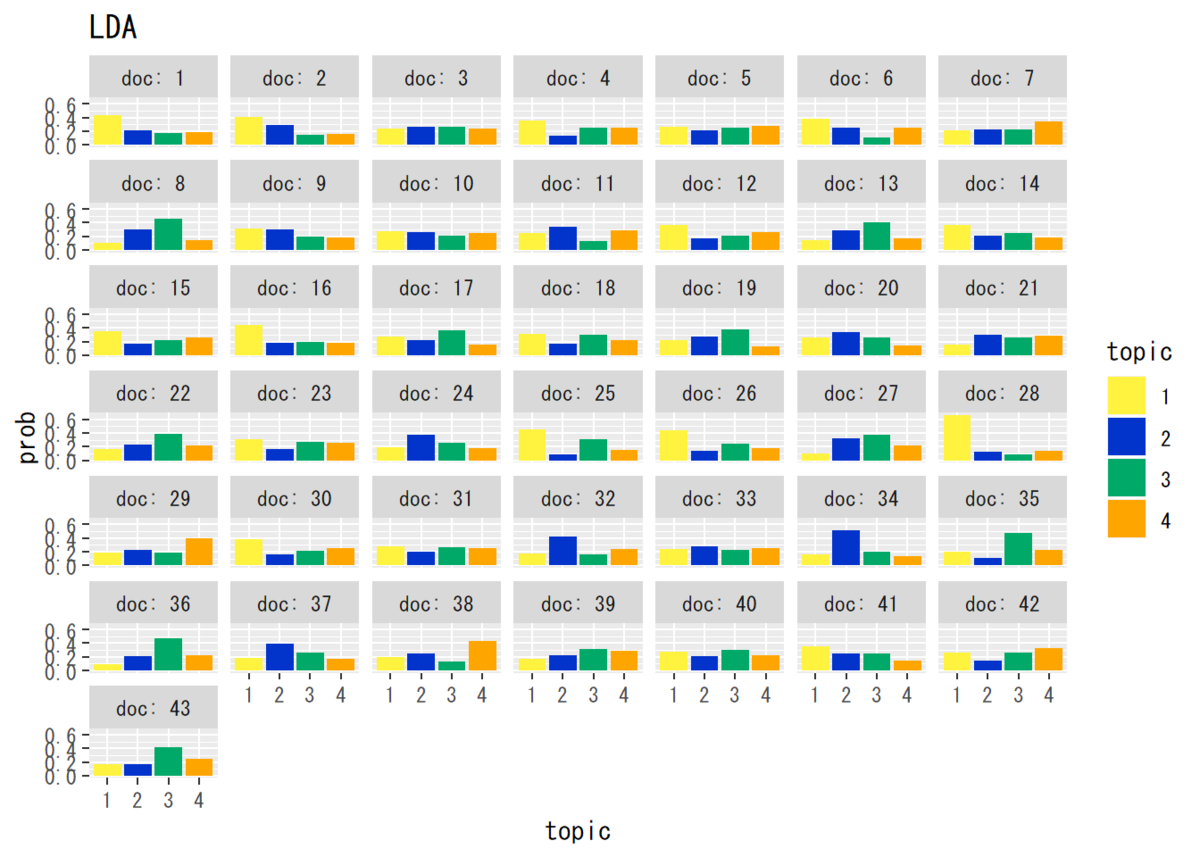
・単語分布(平均値)
## 単語分布(平均値) #パラメータの平均値を算出 phi_kv <- matrix(nrow = K, ncol = V) for(k in 1:K) { phi_kv[k, ] <- beta_kv[k, ] / sum(beta_kv[k, ]) } # データフレームを作成 phi_df_wide <- cbind(as.data.frame(phi_kv), as.factor(1:K)) # トピック番号の列を加える # データフレームをlong型に変換 colnames(phi_df_wide) <- c(1:V, "topic") # key用に行名を付与 phi_df_long <- gather(phi_df_wide, key = "word", value = "prob", -topic) # 変換 phi_df_long$word <- phi_df_long$word %>% # 文字列から因子に変換 as.numeric() %>% as.factor() # 作図 ggplot(data = phi_df_long, mapping = aes(x = word, y = prob, fill = word)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ facet_wrap(~ topic, labeller = label_both) + # グラフを分割 theme(legend.position = "none") + # 凡例 labs(title = "LDA") # タイトル
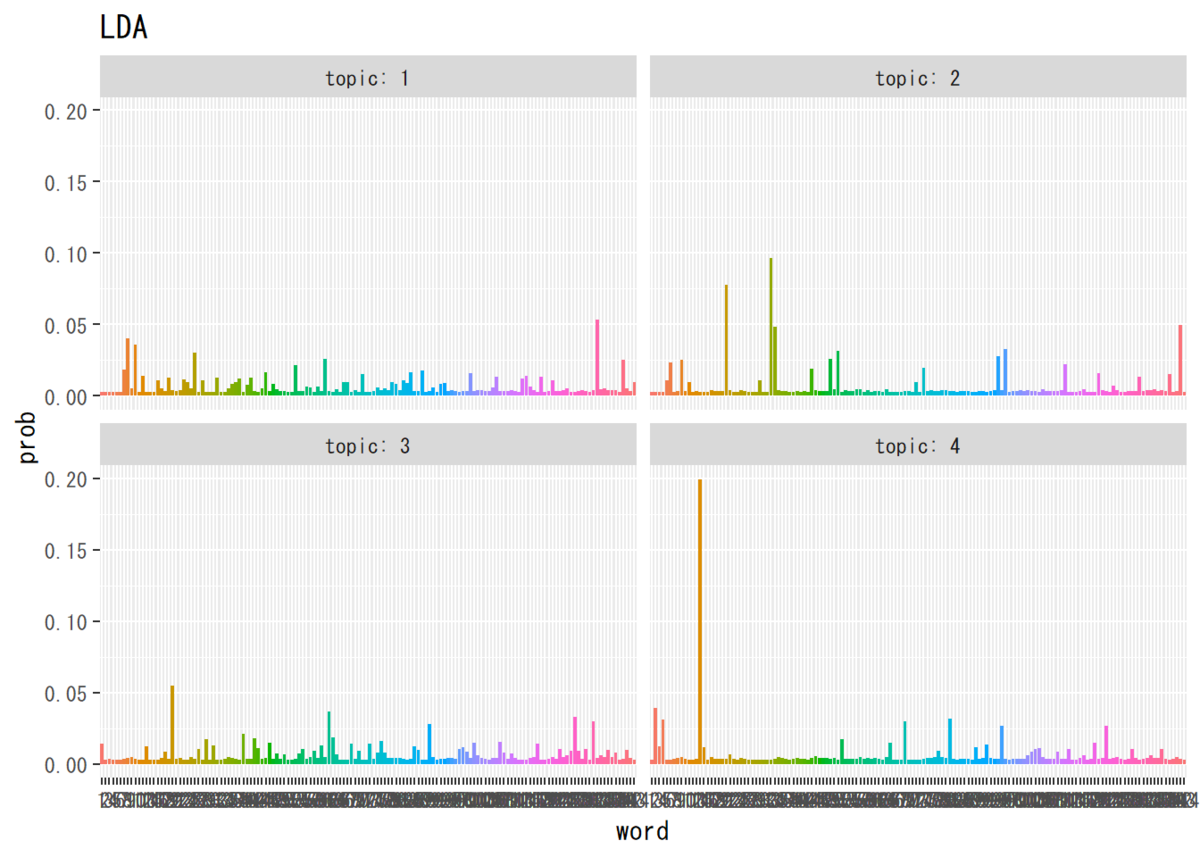
・推移の確認
・推移の記録
# 推移の確認用(初期値) trace_alpha <- alpha_dk[1, ] trace_beta <- beta_kv[1, ] # 推移の確認用(更新後) trace_alpha <- rbind(trace_alpha, alpha_dk[1, ]) trace_beta <- rbind(trace_beta, beta_kv[1, ])
推移を確認するために、パラメータを更新する度に記録しておく。トピック分布については文書1、単語分布についてはトピック1のみ確認する。
・トピック分布のパラメータ
## トピック分布のパラメータ # データフレームを作成 trace_alpha_df_wide <- cbind(as.data.frame(trace_alpha), 1:nrow(trace_alpha)) # 試行回数 # データフレームをlong型に変換 colnames(trace_alpha_df_wide) <- c(1:K, "n") # key用の行名を付与 trace_alpha_df_long <- gather(trace_alpha_df_wide, key = "topic", value = "alpha", -n) # 変換 # 描画 ggplot(data = trace_alpha_df_long, mapping = aes(x = n, y = alpha, color = topic)) + # データ geom_line() + # 棒グラフ labs(title = "LDA:alpha") # タイトル
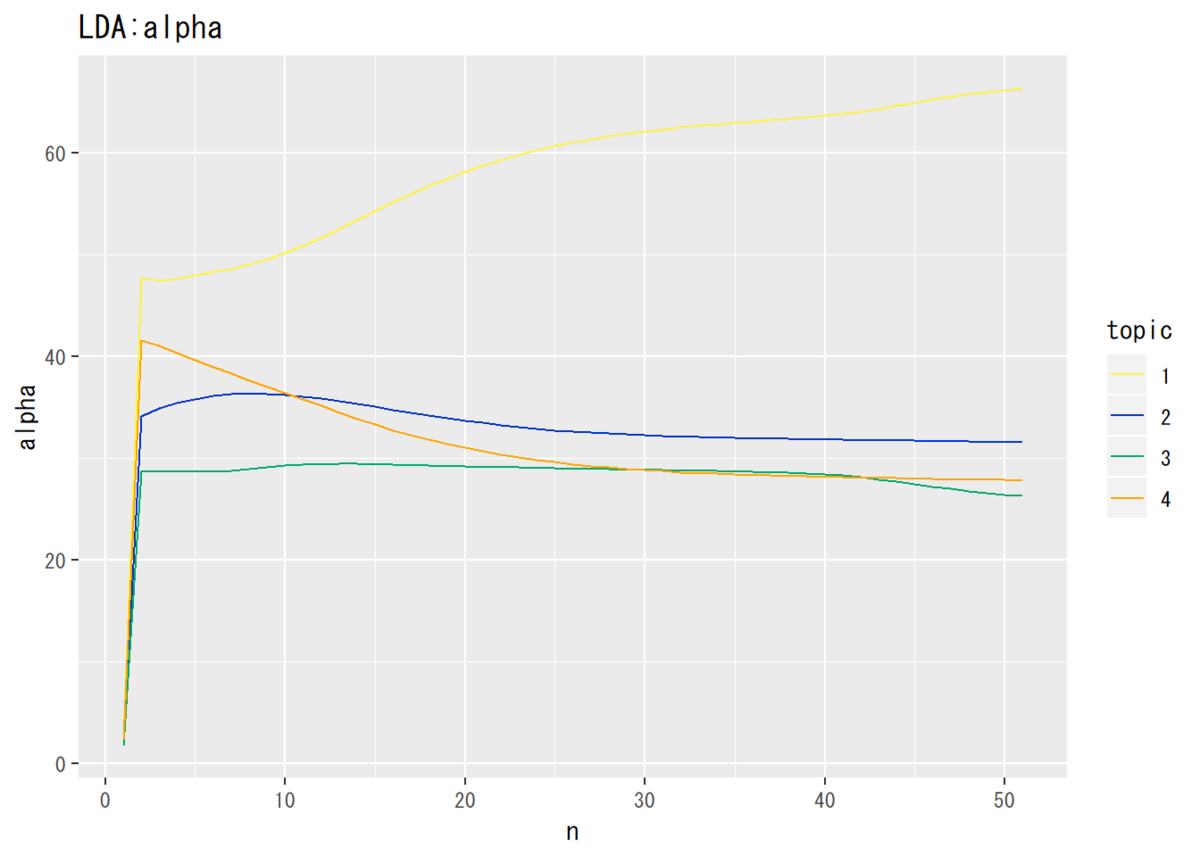
・単語分布のパラメータ
## 単語分布のパラメータ # データフレームを作成 trace_beta_df_wide <- cbind(as.data.frame(trace_beta), 1:nrow(trace_beta)) # 試行回数 # データフレームをlong型に変換 colnames(trace_beta_df_wide) <- c(1:V, "n") # key用の行名を付与 trace_beta_df_long <- gather(trace_beta_df_wide, key = "word", value = "beta", -n) # 変換 trace_beta_df_long$word <- trace_beta_df_long$word %>% # 文字列になるため因子に変換 as.numeric() %>% as.factor() # 描画 ggplot(data = trace_beta_df_long, mapping = aes(x = n, y = beta, color = word)) + geom_line(alpha = 0.5) + # 棒グラフ theme(legend.position = "none") + # 凡例 labs(title = "LDA:beta") # タイトル

・各トピックの出現確率の上位語
### 各トピックの出現確率の上位語 ## 語彙インデックス(v) # 指定した出現回数以上の単語の行番号 num <- mecab_df %>% select(-c(TERM, POS1, POS2)) %>% apply(1, sum) >= 5 # 抽出する総出現回数を指定する v_index <- mecab_df[num, ] %>% filter(grepl("名詞|形容詞|^動詞", POS1)) %>% # 抽出する品詞を指定する filter(grepl("一般|^自立", POS2)) %>% filter(!grepl(stop_words, TERM)) %>% .[, 1] # 単語の列を抽出する # データフレームを作成 phi_df_wide2 <- cbind(as.data.frame(t(phi_kv)), v_index) %>% as.data.frame() colnames(phi_df_wide2) <- c(paste0("topic", 1:K), "word") # key用の行名を付与 # データフレームの整形 phi_df_long2 <- data.frame() for(i in 1:K) { tmp_df <- phi_df_wide2 %>% select(paste0("topic", i), word) %>% # arrange(-.[, 1]) %>% # 降順に並べ替え head(20) %>% # 任意で指定した上位n語を抽出 gather(key = "topic", value = "prob", -word) # long型に変換 phi_df_long2 <- rbind(phi_df_long2, tmp_df) } # 描画 ggplot(data = phi_df_long2, mapping = aes(x = reorder(x = word, X = prob), y = prob, fill = word)) + # データ geom_bar(stat = "identity", position = "dodge") + # 棒グラフ coord_flip() + # グラフの向き facet_wrap( ~ topic, scales = "free") + # グラフの分割 theme(legend.position = "none") + # 凡例 labs(title = "LDA") # タイトル

(誰かストップワードのでレシピをください。)
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
2019/08/13:加筆修正しました。
【次節の内容】
- スクラッチ実装編
トピックモデルに対する変分ベイズ推定をプログラム(行列計算)で確認します。
- 数式読解編
トピックモデルに対する周辺化ギブスサンプリング(一様なハイパラ)を数式で確認します。