はじめに
ハロー!プロジェクトの歴史を可視化しようシリーズ(仮)です。
この記事では、各グループの平均月齢の推移をバーチャートレースにします。
【他の記事】
【目次】
平均月齢の推移の可視化
ハロー!プロジェクトのグループ・ユニットの平均月齢の推移をバーチャートレースで可視化します。1年に1歳ではなく、ひと月に1か月(1/12歳)カウントアップします。
次のパッケージを利用します。
# 利用パッケージ library(tidyverse) library(lubridate) library(gganimate)
この記事では、基本的にパッケージ名::関数名()の記法を使うので、パッケージを読み込む必要はありません。
ただし、パイプ演算子%>%を使うためmagrittrと、作図コードがごちゃごちゃしないようにパッケージ名を省略するためggplot2は読み込む必要があります。
データの読込
次のページのデータを利用します。
GitHub上のcsvデータをRから読み込めたらよかったのですがやり方が分からなかったので、ダウンロードしてローカルフォルダに保存しておきます。
保存先のフォルダパスを指定します。
# フォルダパスを指定 dir_path <- "data/HP_DB-main/"
ファイルの読み込み時にファイル名を結合する(ファイルパスにする)ので、末尾を/にしておきます。
メンバーの情報を読み込みます。
# メンバー一覧を読み込み member_df <- readr::read_csv( file = paste0(dir_path, "member.csv"), col_types = readr::cols( memberID = "i", memberName = "c", HPjoinDate = readr::col_date(format = "%Y/%m/%d"), debutDate = readr::col_date(format = "%Y/%m/%d"), HPgradDate = readr::col_date(format = "%Y/%m/%d"), memberKana = "c", birthDate = readr::col_date(format = "%Y/%m/%d") ) ) %>% dplyr::arrange(memberID) # 昇順に並べ替え member_df
## # A tibble: 273 x 7 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 1 中澤裕子 1997-09-14 1998-01-28 2009-03-31 なかざわゆう~ 1973-06-19 ## 2 2 石黒彩 1997-09-14 1998-01-28 2000-01-07 いしぐろあや 1978-05-12 ## 3 3 飯田圭織 1997-09-14 1998-01-28 2009-03-31 いいだかおり 1981-08-08 ## 4 4 安倍なつみ 1997-09-14 1998-01-28 2009-03-31 あべなつみ 1981-08-10 ## 5 5 福田明日香 1997-09-14 1998-01-28 1999-04-18 ふくだあすか 1984-12-17 ## 6 6 平家みちよ 1997-11-05 1997-11-05 2002-11-07 へいけみちよ 1979-04-06 ## 7 7 保田圭 1998-05-03 1998-05-03 2009-03-31 やすだけい 1980-12-06 ## 8 8 矢口真里 1998-05-03 1998-05-03 2005-04-14 やぐちまり 1983-01-20 ## 9 9 市井紗耶香 1998-05-03 1998-05-03 2000-05-21 いちいさやか 1983-12-31 ## 10 10 信田美帆 1999-02-21 1999-04-21 2000-10-09 しのだみほ 1972-05-18 ## # ... with 263 more rows
member.csvは、メンバーID・メンバー名・ハロプロ加入日・メジャーデビュー日・卒業日・メンバー名(かな)の6列のcsvファイルです。
member.csvには、メンバーが重複しているデータがあります。
# 重複データを確認 member_df %>% dplyr::filter(memberID %in% c(19, 41))
## # A tibble: 4 x 7 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 19 戸田鈴音 1999-04-27 NA 2000-04-30 とだりんね 1981-02-06 ## 2 19 りんね 2000-05-01 2001-04-18 2002-10-13 りんね 1981-02-06 ## 3 41 紺野あさ美 2001-08-26 2001-08-26 2006-07-23 こんのあさみ 1987-05-07 ## 4 41 紺野あさ美 2007-07-15 2007-07-15 2009-03-31 こんのあさみ 1987-05-07
「戸田鈴音」さんは改名によるもので、「紺野あさ美」さんはモーニング娘。卒業の後にハロプロ復帰したためです。
また、誕生日が欠損しているデータがあります。
# 欠損データを確認 member_df %>% dplyr::filter(is.na(birthDate))
## # A tibble: 2 x 7 ## memberID memberName HPjoinDate debutDate HPgradDate memberKana birthDate ## <int> <chr> <date> <date> <date> <chr> <date> ## 1 21 小林梓 1999-04-27 NA 1999-08-23 こばやしあずさ NA ## 2 98 大柳麻帆 2004-08-10 NA 2005-07-01 おおやなぎまほ NA
誕生日が公表されていないようです。
グループの情報を読み込みます。
# グループ一覧を読み込み group_df <- readr::read_csv( file = paste0(dir_path, "group.csv"), col_types = readr::cols( groupID = "i", groupName = "c", formDate = readr::col_date(format = "%Y/%m/%d"), dissolveDate = readr::col_date(format = "%Y/%m/%d"), isUnit = "l" ) ) %>% dplyr::arrange(groupID, formDate) # 昇順に並べ替え group_df
## # A tibble: 60 x 5 ## groupID groupName formDate dissolveDate isUnit ## <int> <chr> <date> <date> <lgl> ## 1 1 モーニング娘。 1997-09-14 2013-12-31 FALSE ## 2 1 モーニング娘。 '14 2014-01-01 2014-12-31 FALSE ## 3 1 モーニング娘。 '15 2015-01-01 2015-12-31 FALSE ## 4 1 モーニング娘。 '16 2016-01-01 2016-12-31 FALSE ## 5 1 モーニング娘。 '17 2017-01-01 2017-12-31 FALSE ## 6 1 モーニング娘。 '18 2018-01-01 2018-12-31 FALSE ## 7 1 モーニング娘。 '19 2019-01-01 2019-12-31 FALSE ## 8 1 モーニング娘。 '20 2020-01-01 2020-12-31 FALSE ## 9 1 モーニング娘。 '21 2021-01-01 2021-12-31 FALSE ## 10 1 モーニング娘。 '22 2022-01-01 NA FALSE ## # ... with 50 more rows
group.csvは、グループID・グループ名・結成日・解散日・ユニットかどうかの5列のcsvファイルです。改名グループであれば結成日・解散日は改名日を表し、現在活動中であれば解散日が欠損値になります。
例えば、「モーニング娘。とモーニング娘。'14」「スマイレージとアンジュルム」「カントリー娘。とカントリー・ガールズ」は同一のグループとして共通のグループIDを持ちます。よって、groupID列の値は重複し、groupName列の値(文字列)は重複しません。
メンバーの加入日・卒業日の情報を読み込みます。
# 加入・卒業日一覧を読み込み join_df <- readr::read_csv( file = paste0(dir_path, "join.csv"), col_types = readr::cols( memberID = "i", groupID = "i", joinDate = readr::col_date(format = "%Y/%m/%d"), gradDate = readr::col_date(format = "%Y/%m/%d") ) ) %>% dplyr::arrange(joinDate, memberID, groupID) # 昇順に並べ替え join_df
## # A tibble: 514 x 4 ## memberID groupID joinDate gradDate ## <int> <int> <date> <date> ## 1 1 1 1997-09-14 2001-04-15 ## 2 2 1 1997-09-14 2000-01-07 ## 3 3 1 1997-09-14 2005-01-30 ## 4 4 1 1997-09-14 2004-01-25 ## 5 5 1 1997-09-14 1999-04-18 ## 6 7 1 1998-05-03 2003-05-05 ## 7 8 1 1998-05-03 2005-04-14 ## 8 9 1 1998-05-03 2000-05-21 ## 9 2 2 1998-10-18 2000-01-07 ## 10 3 2 1998-10-18 2002-09-23 ## # ... with 504 more rows
join.csvは、メンバーID・グループID・加入日・卒業日の4列のcsvファイルです。現在活動中であれば卒業日が欠損値になります。
member.cscのメンバーID、group.csvのグループIDと対応しています。
このデータを利用して、各グループ・ユニットの平均月齢を集計します。
期間の指定
アニメーションとしてグラフ化する(平均月齢を集計する)期間を指定します。
# 期間を指定 date_from <- "1997-09-01" date_to <- "2022-05-30" #date_to <- lubridate::today()
開始日をdate_from、終了日をdate_toとして期間を指定します。文字列でyyyy-mm-ddやyyyy/mm/dd、yyyymmddなどと指定できます。現在の日付を使う場合は、today()で設定します。
集計に利用する期間内の全ての月を持つベクトルを作成します。
# 月ベクトルを作成 date_vec <- seq( from = date_from %>% lubridate::as_date() %>% lubridate::floor_date(unit = "mon"), to = date_to %>% lubridate::as_date() %>% lubridate::floor_date(unit = "mon"), by = "mon" ) length(date_vec) # フレーム数
## [1] 297
seq()で、第1引数fromから第2引数toまでのベクトルを作成します。第3引数byに"mon"を指定すると、1か月間隔のベクトルを作成します。
文字列型で指定した開始日を、as_date()でDate型に変換し、さらにfloor_date()のunit引数に"mon"を指定して月初の日付にして(日にちを切り捨てて)使います。
アニメーションでは、1月ずつフレーム(グラフ)を切り替えるので、date_vecの要素数がフレーム数になります。
演出用の処理
集計を行う前に、アニメーションの演出用のデータフレームを作成します。
改名グループの対応データ
各フレーム(各グラフ・各月)に応じてグループ名のラベルを変更するために、月とグループ名とを対応するデータフレームを作成します。
「期間内の全ての月」と「各月におけるグループ名」のデータフレームを作成します。
# 月・グループID・グループ名の対応表を作成 group_name_df <- group_df %>% dplyr::mutate( formDate = formDate %>% lubridate::floor_date(unit = "mon"), dissolveDate = dissolveDate %>% dplyr::if_else( condition = is.na(.), true = lubridate::today(), false = dissolveDate ) %>% # 現在活動中なら現在の日付 lubridate::floor_date(unit = "mon"), n = lubridate::interval(start = formDate, end = dissolveDate) %>% lubridate::time_length(unit = "mon") + 1 ) %>% # 月単位に切り捨てて月数をカウント tidyr::uncount(n) %>% # 月数に応じて行を複製 dplyr::group_by(groupName) %>% # 行番号用にグループ化 dplyr::mutate(idx = dplyr::row_number()) %>% # 行番号を割り当て dplyr::group_by(groupName, idx) %>% # 1か月刻みの値の作成用にグループ化 dplyr::mutate(date = seq(from = formDate, to = dissolveDate, by = "mon")[idx]) %>% # 複製した行を1か月刻みの値に変更 dplyr::group_by(date, groupID) %>% # 重複の除去用にグループ化 dplyr::slice_max(formDate) %>% # 重複する場合は新しい方を抽出 dplyr::ungroup() %>% # グループ化を解除 dplyr::select(date, groupID, groupName, formDate, dissolveDate) %>% # 利用する列を選択 dplyr::arrange(date, groupID) # 昇順に並べ替え group_name_df
## # A tibble: 3,240 x 5 ## date groupID groupName formDate dissolveDate ## <date> <int> <chr> <date> <date> ## 1 1997-09-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 2 1997-10-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 3 1997-11-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 4 1997-12-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 5 1998-01-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 6 1998-02-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 7 1998-03-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 8 1998-04-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 9 1998-05-01 1 モーニング娘。 1997-09-01 2013-12-01 ## 10 1998-06-01 1 モーニング娘。 1997-09-01 2013-12-01 ## # ... with 3,230 more rows
group_dfは、グループ名groupNameと結成日(改名日)formDate・解散日(次の改名日)dissolveDateの情報を持ちます。
そこで、グループ名ごとに、結成月から解散月(または現在の月)までの全ての月を作成します。
formDate, dissolveDate列をfloor_date()で結成月と解散月にします。ただし、解散前のグループであれば解散日がNAなので、if_else()とis.na()を使って、today()で現在の日付に変更します。
結成月から解散月までの月数を、interval()とtime_length()を使って求めて、n列とします。解散月 - 結成月が求まるので+ 1します。
uncount()でn列の値と同じ行数に複製します。
ここまでで、グループ名ごとに、その名前だった月数に応じて行(データ)が複製されました。続いて、1か月間隔の値を設定します。
複製した行にrow_number()で行番号を割り当てて、idx列とします。
結成月から解散月までの月ベクトルをseq()で作成して、行番号に対応する要素を取り出して、date列とします。
改名日が月の途中だと月(date列の値)が重複するので、slice_max()で新しい方の行(データ)を抽出します。
結成前月と解散月のデータ
続いて、バーの変化を強調するために、結成1か月前と解散月のデータ(メンバー数が0のデータ)を作成します。
グループごとの「結成1か月前と解散月」のデータフレームを作成します。
# 結成前月・解散月のデータを作成 member_0_df <- group_df %>% dplyr::group_by(groupID) %>% # 日付の再設定用にグループ化 dplyr::mutate(dissolveDate = dplyr::lead(dissolveDate, n = max(dplyr::n())-1)) %>% # 最後の行を1行目にズラす dplyr::slice_head(n = 1) %>% # 1行目を抽出 dplyr::ungroup() %>% # グループ化を解除 dplyr::mutate( formDate = formDate %>% lubridate::rollback() %>% # 結成1か月前に変更 lubridate::floor_date(unit = "mon"), dissolveDate = dissolveDate %>% lubridate::floor_date(unit = "mon") ) %>% # 月単位に切り捨て tidyr::pivot_longer( cols = c(formDate, dissolveDate), names_to = "date_type", values_to = "date" ) %>% # 結成前月・解散月を同じ列に変形 dplyr::select(date, groupID) %>% # 利用する列を選択 dplyr::filter(!is.na(date)) %>% # 現在活動中のグループの解散月を除去 tibble::add_column( groupName = " ", moonage = 0, member_n = 0, average_moonage = 0 ) %>% # メンバー数(0人)を追加 dplyr::filter(date > min(date_vec), date < max(date_vec)) %>% # 指定した期間内のデータを抽出 dplyr::arrange(date, groupID) # 昇順に並び替え member_0_df
## # A tibble: 76 x 6 ## date groupID groupName moonage member_n average_moonage ## <date> <int> <chr> <dbl> <dbl> <dbl> ## 1 1998-09-01 2 " " 0 0 0 ## 2 1999-01-01 3 " " 0 0 0 ## 3 1999-02-01 4 " " 0 0 0 ## 4 1999-03-01 5 " " 0 0 0 ## 5 1999-07-01 7 " " 0 0 0 ## 6 1999-09-01 6 " " 0 0 0 ## 7 2000-05-01 8 " " 0 0 0 ## 8 2000-06-01 9 " " 0 0 0 ## 9 2000-10-01 3 " " 0 0 0 ## 10 2001-12-01 9 " " 0 0 0 ## # ... with 66 more rows
group_dfのformDate, dissolveDate列は、改名したグループだと、最初の行は「結成日・改名日」、途中の行は「改名日・改名日」、最後の行は「改名日・解散日」になります。
そこで、グループごとに、formDate列の最初の値とdissolveDate列の最後の値を取り出して、「結成日・解散日」にします。
dissolveDate列の最後の行の値が最初の行に来るように、lead()でズラします。ズラす行数の引数nに、行数 - 1の値を指定します。行数はn()で得られますが行数分の値が返ってくるので、max()で1つの値にして使います。
必要な値を最初の行にまとめられたので、slice_head()で最初の行のみ取り出します。
続いて、次で作成する集計データと対応するようにデータフレームを変形します。
結成日と解散日をfloor_date()で月初の値にします。その際に、rollback()で結成月の1か月前にします。
pivot_longer()で結成前月と解散月の列をまとめて、date列とします。その際に、結成か解散かを表す列をdate_type列としますが、この列は使いません。
現在活動中のグループの解散月はNAなので、is.na()を使って取り除きます。
結成前と解散後はメンバー数が0なので、結合時(集計データ)の列と対応するように値(データ)を設定します。グループ名については、作図時に"NA"と表示されないように(空白にするために)半角スペースにしておきます。
演出用の2つのデータフレームを用意できました。次の集計処理に利用します。
平均月齢の集計と順位付け
平均月齢を集計してランキングを付けます。
受け皿となるデータフレームの作成用にサイズを取得します。
# サイズを取得 date_size <- length(date_vec) group_size <- max(group_df[["groupID"]]) member_size <- max(member_df[["memberID"]])
集計した期間の月数・グループ数・メンバー数を取得します。
各月における「平均月齢」と「順位」のデータフレームを作成します。
# 平均月齢を集計 rank_df <- tibble::tibble( date = rep(date_vec, each = group_size*member_size), groupID = rep(rep(1:group_size, times = date_size), each = member_size), memberID = rep(1:member_size, times = date_size*group_size) ) %>% # 全ての組み合わせを作成 dplyr::left_join(group_name_df, by = c("date", "groupID")) %>% # グループ情報を結合 dplyr::filter(date >= formDate, date <= dissolveDate) %>% # 活動中のグループを抽出 dplyr::select(!c(formDate, dissolveDate)) %>% # 不要な列を削除 dplyr::left_join( join_df %>% dplyr::mutate( joinDate = lubridate::floor_date(joinDate, unit = "mon"), gradDate = lubridate::floor_date(gradDate, unit = "mon") ), # 月単位に切り捨て by = c("groupID", "memberID") ) %>% # 加入メンバー情報を結合 dplyr::filter(date >= joinDate, date < gradDate | is.na(gradDate)) %>% # グループ活動中のメンバーを抽出 dplyr::select(!c(joinDate, gradDate)) %>% # 不要な列を削除 dplyr::left_join( member_df %>% dplyr::distinct(memberID, .keep_all = TRUE), # 重複を除去 by = "memberID" ) %>% # メンバー情報を結合 dplyr::select(date, groupID, groupName, memberID, memberName, birthDate) %>% # 利用する列を選択 dplyr::mutate( moonage = lubridate::interval(start = birthDate, end = date) %>% lubridate::time_length(unit = "mon") ) %>% # メンバーの月齢を計算 dplyr::group_by(date, groupID, groupName) %>% # 平均月齢の計算用にグループ化 dplyr::summarise( moonage = sum(moonage, na.rm = TRUE), member_n = sum(!is.na(birthDate)), .groups = "drop" ) %>% # グループの合計月齢と(計算に使った)メンバー数を計算 dplyr::mutate(average_moonage = moonage / member_n) %>% # グループの平均月齢を計算 dplyr::bind_rows(member_0_df) %>% # 結成前月・解散月を追加 dplyr::arrange(date, average_moonage, groupID) %>% # ランク付け用に並べ替え dplyr::group_by(date) %>% # ランク付け用にグループ化 dplyr::mutate( groupID = factor(groupID), year = average_moonage %/% 12, month = round(average_moonage %% 12, digits = 1), ranking = dplyr::row_number(-average_moonage), ) %>% # ランク付けとラベル用の値を追加 dplyr::ungroup() %>% # グループ化の解除 dplyr::select(date, groupID, groupName, average_moonage, year, month, ranking) %>% # 利用する列を選択 dplyr::arrange(date, ranking) # 昇順に並べ替え rank_df
## # A tibble: 3,209 x 7 ## date groupID groupName average_moonage year month ranking ## <date> <fct> <chr> <dbl> <dbl> <dbl> <int> ## 1 1997-09-01 1 モーニング娘。 212. 17 8 1 ## 2 1997-10-01 1 モーニング娘。 213. 17 9 1 ## 3 1997-11-01 1 モーニング娘。 214. 17 10 1 ## 4 1997-12-01 1 モーニング娘。 215. 17 11 1 ## 5 1998-01-01 1 モーニング娘。 216. 18 0 1 ## 6 1998-02-01 1 モーニング娘。 217. 18 1 1 ## 7 1998-03-01 1 モーニング娘。 218. 18 2 1 ## 8 1998-04-01 1 モーニング娘。 219. 18 3 1 ## 9 1998-05-01 1 モーニング娘。 208. 17 4 1 ## 10 1998-06-01 1 モーニング娘。 209. 17 5 1 ## # ... with 3,199 more rows
まずは、データの受け皿となる、月・グループID・メンバーIDの全ての組み合わせを持つデータフレームを作成します。
次に、各グループの(改名に対応した)名前と、各メンバーの加入・卒業日の情報を結合して、不要な行(組み合わせ)を削除します。
続いて、各メンバーの誕生日の情報を結合して、各メンバーの月齢を計算し、各グループの平均月齢を計算します。
最後に、各グループの平均月齢に応じて順位付けして、作図用にデータを編集します。
各処理を細かく見ます。
・コード(クリックで展開)
月・グループID・メンバーIDの全ての組み合わせを持つデータフレームを作成します。
# 受け皿を作成 df1 <- tibble::tibble( date = rep(date_vec, each = group_size*member_size), groupID = rep(rep(1:group_size, times = date_size), each = member_size), memberID = rep(1:member_size, times = date_size*group_size) ) # 全ての組み合わせを作成 df1
## # A tibble: 3,528,360 x 3 ## date groupID memberID ## <date> <int> <int> ## 1 1997-09-01 1 1 ## 2 1997-09-01 1 2 ## 3 1997-09-01 1 3 ## 4 1997-09-01 1 4 ## 5 1997-09-01 1 5 ## 6 1997-09-01 1 6 ## 7 1997-09-01 1 7 ## 8 1997-09-01 1 8 ## 9 1997-09-01 1 9 ## 10 1997-09-01 1 10 ## # ... with 3,528,350 more rows
rep()のtimes引数とeach引数を組み合わせて、全ての組み合わせを作成します。times引数は要素ごとに、each引数はベクトルを繰り返して複製します。
これは、次のように処理しています。
tibble::tibble( x = rep(1:3, each = 3*3), y = rep(rep(1:3, times = 3), each = 3), z = rep(1:3, times = 3*3) )
## # A tibble: 27 x 3 ## x y z ## <int> <int> <int> ## 1 1 1 1 ## 2 1 1 2 ## 3 1 1 3 ## 4 1 2 1 ## 5 1 2 2 ## 6 1 2 3 ## 7 1 3 1 ## 8 1 3 2 ## 9 1 3 3 ## 10 2 1 1 ## # ... with 17 more rows
各グループの各月に対応した名前・結成日・解散日の情報を結合します。
# グループの情報を結合 df2 <- df1 %>% dplyr::left_join(group_name_df, by = c("date", "groupID")) %>% # グループ情報を結合 dplyr::filter(date >= formDate, date <= dissolveDate) # 活動中のグループを抽出 df2
## # A tibble: 874,800 x 6 ## date groupID memberID groupName formDate dissolveDate ## <date> <int> <int> <chr> <date> <date> ## 1 1997-09-01 1 1 モーニング娘。 1997-09-01 2013-12-01 ## 2 1997-09-01 1 2 モーニング娘。 1997-09-01 2013-12-01 ## 3 1997-09-01 1 3 モーニング娘。 1997-09-01 2013-12-01 ## 4 1997-09-01 1 4 モーニング娘。 1997-09-01 2013-12-01 ## 5 1997-09-01 1 5 モーニング娘。 1997-09-01 2013-12-01 ## 6 1997-09-01 1 6 モーニング娘。 1997-09-01 2013-12-01 ## 7 1997-09-01 1 7 モーニング娘。 1997-09-01 2013-12-01 ## 8 1997-09-01 1 8 モーニング娘。 1997-09-01 2013-12-01 ## 9 1997-09-01 1 9 モーニング娘。 1997-09-01 2013-12-01 ## 10 1997-09-01 1 10 モーニング娘。 1997-09-01 2013-12-01 ## # ... with 874,790 more rows
left_join()で、group_name_dfからグループ名(groupName列)・結成月(formDate列)・解散月(dissolveDate列)の情報を、月(date列)とグループ(groupID列)で対応付けて結合します。
dateがformDate以上でdissoveDate以下の行を抽出します。各月において活動中のグループが得られ(groupIDについて不要なデータが削除され)ます。
各メンバーのグループ加入・卒業日の情報を結合します。
# 加入・卒業の情報を結合 df3 <- df2 %>% dplyr::select(!c(formDate, dissolveDate)) %>% # 不要な列を削除 dplyr::left_join( join_df %>% dplyr::mutate( joinDate = lubridate::floor_date(joinDate, unit = "mon"), gradDate = lubridate::floor_date(gradDate, unit = "mon") ), # 月単位に切り捨て by = c("groupID", "memberID") ) %>% # 所属メンバー情報を結合 dplyr::filter(date >= joinDate, date < gradDate | is.na(gradDate)) # 活動中のメンバーを抽出 df3
## # A tibble: 21,189 x 6 ## date groupID memberID groupName joinDate gradDate ## <date> <int> <int> <chr> <date> <date> ## 1 1997-09-01 1 1 モーニング娘。 1997-09-01 2001-04-01 ## 2 1997-09-01 1 2 モーニング娘。 1997-09-01 2000-01-01 ## 3 1997-09-01 1 3 モーニング娘。 1997-09-01 2005-01-01 ## 4 1997-09-01 1 4 モーニング娘。 1997-09-01 2004-01-01 ## 5 1997-09-01 1 5 モーニング娘。 1997-09-01 1999-04-01 ## 6 1997-10-01 1 1 モーニング娘。 1997-09-01 2001-04-01 ## 7 1997-10-01 1 2 モーニング娘。 1997-09-01 2000-01-01 ## 8 1997-10-01 1 3 モーニング娘。 1997-09-01 2005-01-01 ## 9 1997-10-01 1 4 モーニング娘。 1997-09-01 2004-01-01 ## 10 1997-10-01 1 5 モーニング娘。 1997-09-01 1999-04-01 ## # ... with 21,179 more rows
left_join()で、join_dfから加入月(joinDate列)・卒業月(gradDate列)の情報を、グループ(groupID列)とメンバー(memberID列)で対応付けて結合します。結合時に、floor_date()で日付から月に変換します。
dateがjoinDate以上でgradDate以下または欠損値の行を抽出します。各月において活動中のメンバーが得られ(memberIDについて不要なデータが削除され)ます。
各メンバーの誕生日の情報を結合して、月齢を計算します。
# 月齢を計算 df4 <- df3 %>% dplyr::select(!c(joinDate, gradDate)) %>% # 不要な列を削除 dplyr::left_join( member_df %>% dplyr::distinct(memberID, .keep_all = TRUE), # 重複を除去 by = "memberID" ) %>% # メンバー情報を結合 dplyr::select(date, groupID, groupName, memberID, memberName, birthDate) %>% # 利用する列を選択 dplyr::mutate( moonage = lubridate::interval(start = birthDate, end = date) %>% lubridate::time_length(unit = "mon") ) # メンバーの月齢を計算 df4
## # A tibble: 21,189 x 7 ## date groupID groupName memberID memberName birthDate moonage ## <date> <int> <chr> <int> <chr> <date> <dbl> ## 1 1997-09-01 1 モーニング娘。 1 中澤裕子 1973-06-19 290. ## 2 1997-09-01 1 モーニング娘。 2 石黒彩 1978-05-12 232. ## 3 1997-09-01 1 モーニング娘。 3 飯田圭織 1981-08-08 193. ## 4 1997-09-01 1 モーニング娘。 4 安倍なつみ 1981-08-10 193. ## 5 1997-09-01 1 モーニング娘。 5 福田明日香 1984-12-17 152. ## 6 1997-10-01 1 モーニング娘。 1 中澤裕子 1973-06-19 291. ## 7 1997-10-01 1 モーニング娘。 2 石黒彩 1978-05-12 233. ## 8 1997-10-01 1 モーニング娘。 3 飯田圭織 1981-08-08 194. ## 9 1997-10-01 1 モーニング娘。 4 安倍なつみ 1981-08-10 194. ## 10 1997-10-01 1 モーニング娘。 5 福田明日香 1984-12-17 153. ## # ... with 21,179 more rows
left_join()で、member_dfから誕生日(birthDate列)の情報を、メンバー(memberID列)で対応付けて結合します。メンバー名(memberName列)は確認用です。結合時に、distinct()で重複データを削除します。
interval()とtime_length()で、birthDateからdateまでの月数を求めます。各月におけるメンバーの月齢が得られます。
各グループの平均月齢を計算します。
# 平均月齢を計算 df5 <- df4 %>% dplyr::group_by(date, groupID, groupName) %>% # 平均月齢の計算用にグループ化 dplyr::summarise( moonage = sum(moonage, na.rm = TRUE), member_n = sum(!is.na(birthDate)), .groups = "drop" ) %>% # グループの合計月齢と(計算に使った)メンバー数を計算 dplyr::mutate(average_moonage = moonage / member_n) # グループの平均月齢を計算 df5
## # A tibble: 3,133 x 6 ## date groupID groupName moonage member_n average_moonage ## <date> <int> <chr> <dbl> <int> <dbl> ## 1 1997-09-01 1 モーニング娘。 1060. 5 212. ## 2 1997-10-01 1 モーニング娘。 1065. 5 213. ## 3 1997-11-01 1 モーニング娘。 1070. 5 214. ## 4 1997-12-01 1 モーニング娘。 1075. 5 215. ## 5 1998-01-01 1 モーニング娘。 1080. 5 216. ## 6 1998-02-01 1 モーニング娘。 1085. 5 217. ## 7 1998-03-01 1 モーニング娘。 1090. 5 218. ## 8 1998-04-01 1 モーニング娘。 1095. 5 219. ## 9 1998-05-01 1 モーニング娘。 1664. 8 208. ## 10 1998-06-01 1 モーニング娘。 1672. 8 209. ## # ... with 3,123 more rows
summarise()で、各メンバーの月齢を合計します。また、メンバー数をカウントします。ただし、誕生日情報がないメンバーがいるので、is.na()の結果を!で反転させて、欠損値NAでないメンバー数をカウントします。
合計月齢(moonage列)をメンバー数(member_n列)で割って、平均月齢(average_moonage列)とします。
作図用に編集します。
# 作図用に編集 df6 <- df5 %>% dplyr::bind_rows(member_0_df) %>% # 結成前月・解散月を追加 dplyr::arrange(date, average_moonage, groupID) %>% # ランク付け用に並べ替え dplyr::group_by(date) %>% # ランク付け用にグループ化 dplyr::mutate( groupID = factor(groupID), year = average_moonage %/% 12, month = round(average_moonage %% 12, digits = 1), ranking = dplyr::row_number(-average_moonage), ) %>% # ランク付けとラベル用の値を追加 dplyr::ungroup() %>% # グループ化の解除 #dplyr::select(date, groupID, groupName, average_moonage, year, month, ranking) %>% # 利用する列を選択:(集計用) dplyr::arrange(date, ranking) # 昇順に並べ替え df6
## # A tibble: 3,209 x 9 ## date groupID groupName moonage member_n average_moonage year month ## <date> <fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1997-09-01 1 モーニング娘~ 1060. 5 212. 17 8 ## 2 1997-10-01 1 モーニング娘~ 1065. 5 213. 17 9 ## 3 1997-11-01 1 モーニング娘~ 1070. 5 214. 17 10 ## 4 1997-12-01 1 モーニング娘~ 1075. 5 215. 17 11 ## 5 1998-01-01 1 モーニング娘~ 1080. 5 216. 18 0 ## 6 1998-02-01 1 モーニング娘~ 1085. 5 217. 18 1 ## 7 1998-03-01 1 モーニング娘~ 1090. 5 218. 18 2 ## 8 1998-04-01 1 モーニング娘~ 1095. 5 219. 18 3 ## 9 1998-05-01 1 モーニング娘~ 1664. 8 208. 17 4 ## 10 1998-06-01 1 モーニング娘~ 1672. 8 209. 17 5 ## # ... with 3,199 more rows, and 1 more variable: ranking <int>
bind_rows()で「メンバーが0のデータmember_0_df」を結合します。
色分け用にグループIDを因子型に変換します。
平均年齢をyy歳mmか月と表示するために、平均月齢を12で割った整数(yyの値)をyear列、12で割った余り(mmの値)をmonth列とします。整数部分は%/%、余り部分は%%で計算できます。また、整数部分についてはround()で値を小数点以下第1位で丸めておきます。
row_number()で平均年齢に応じて順位を付けて、ranking列とします。昇順に通し番号が割り当てられるので、-を付けて大小関係を反転させます。
以上で、必要なデータを得られました。次は、作図を行います。
推移の可視化
平均月齢と順位を棒グラフで可視化します。
バーチャートレースの作成
平均月齢の推移をバーチャートレースで可視化します。バーチャートレースの作図については「【R】バーチャートレースのアニメーションの作図【gganimate】 - からっぽのしょこ」を参照してください。
フレームに関する値を指定します。
# 遷移フレーム数を指定 t <- 8 # 一時停止フレーム数を指定 s <- 2 # 1秒間に表示する月数を指定:(値が大きいと意図した通りにならない) mps <- 3 # フレーム数を取得 n <- length(unique(rank_df[["date"]])) n
## [1] 297
現月と次月のグラフを繋ぐアニメーションのフレーム数をtとして、整数を指定します。
各月のグラフで一時停止するフレーム数をsとして、整数を指定します。
基本となるフレーム数(月の数)をnとします。
バーチャートレースを作成します。
# バーチャートレースを作成:(y軸可変) anim <- ggplot(rank_df, aes(x = ranking, y = average_moonage, fill = groupID, color = groupID)) + geom_bar(stat = "identity", width = 0.9, alpha = 0.8) + # 平均月齢バー geom_text(aes(y = 0, label = paste(groupName, " ")), hjust = 1) + # グループ名ラベル geom_text(aes(label = paste(" ", year, "歳", month, "か月")), hjust = 0) + # 平均年齢ラベル gganimate::transition_states(states = date, transition_length = t, state_length = s, wrap = FALSE) + # フレーム gganimate::ease_aes("cubic-in-out") + # アニメーションの緩急 gganimate::view_follow(fixed_x = TRUE) + # 表示範囲のフィット coord_flip(clip = "off", expand = FALSE) + # 軸の入れ変え scale_x_reverse() + # x軸を反転 theme( axis.title.x = element_blank(), # x軸のラベル axis.title.y = element_blank(), # y軸のラベル axis.text.x = element_blank(), # x軸の目盛ラベル axis.text.y = element_blank(), # y軸の目盛ラベル axis.ticks.x = element_blank(), # x軸の目盛指示線 axis.ticks.y = element_blank(), # y軸の目盛指示線 #panel.grid.major.x = element_line(color = "grey", size = 0.1), # x軸の主目盛線 panel.grid.major.y = element_blank(), # y軸の主目盛線 #panel.grid.minor.x = element_line(color = "grey", size = 0.1), # x軸の補助目盛線 panel.grid.minor.y = element_blank(), # y軸の補助目盛線 panel.border = element_blank(), # グラフ領域の枠線 #panel.background = element_blank(), # グラフ領域の背景 plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 100, b = 10, l = 150, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = "ハロプログループの平均月齢の推移", subtitle = "{lubridate::year(closest_state)}年{lubridate::month(closest_state)}月", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル
y軸を最大値で固定して描画します。
animate()でgif画像を作成します。
# gif画像を作成 g <- gganimate::animate( plot = anim, nframes = n*(t+s), fps = (t+s)*mps, width = 900, height = 800 ) g
plot引数にグラフ、nframes引数にフレーム数、fps引数に1秒当たりのフレーム数を指定します。
(ファイルサイズの上限は越えてないんだけどアップロードできなかったので完成例は省略します。)
anim_save()でgif画像を保存します。
# gif画像を保存 gganimate::anim_save(filename = "output/AverageAge.gif", animation = g)
filename引数にファイルパス("(保存する)フォルダ名/(作成する)ファイル名.gif")、animation引数に作成したgif画像を指定します。
動画を作成する場合は、renderer引数を指定します。
# 動画を作成と保存 m <- gganimate::animate( plot = anim, nframes = n*(t+s), fps = (t+s)*mps, width = 900, height = 800, renderer = gganimate::av_renderer(file = "output/AverageAge.mp4") )
renderer引数に、レンダリング方法に応じた関数を指定します。この例では、av_renderer()を使います。
av_renderer()のfile引数に保存先のファイルパス("(保存する)フォルダ名/(作成する)ファイル名.mp4")を指定します。
(記事に動画を貼れないのでこれで代用します。)
ハロプログループ・ユニットの平均年齢の推移(誤差1か月くらいで計算できててほしい)です!📊 #hellopRoject pic.twitter.com/KaT0jMbKux
— しょこ📚 (@anemptyarchive) 2022年5月4日
月を指定して作図
最後に、指定した月における平均月齢のグラフを作成します。
月を指定して、作図用のデータを作成します。
# 月を指定 date_val <- "2022-05-01" # 作図用のデータを抽出 tmp_rank_df <- rank_df %>% dplyr::filter(date == lubridate::as_date(date_val)) # 平均年齢の最大値を取得 y_max <- max(tmp_rank_df[["average_moonage"]]) %/% 12 y_max
## [1] 21
y軸目盛の編集用に、平均年齢の最大値y_maxを作成しておきます。
棒グラフを作成します。
# 棒グラフを作成 graph <- ggplot(tmp_rank_df, aes(x = ranking, y = average_moonage, fill = groupID, color = groupID)) + geom_bar(stat = "identity", width = 0.9, alpha = 0.8) + # 平均月齢バー geom_text(aes(y = 0, label = paste(groupName, " ")), hjust = 1) + # グループ名ラベル geom_text(aes(y = 0, label = paste(" ", year, "歳", month, "か月")), hjust = 0, color = "white") + # 平均年齢ラベル coord_flip(clip = "off", expand = FALSE) + # 軸の入れ変え scale_x_reverse(breaks = 1:nrow(tmp_rank_df)) + # x軸(縦軸)目盛を反転 scale_y_continuous(breaks = 0:y_max*12, labels = 0:y_max) + # y軸(横軸)目盛 theme( axis.title.y = element_blank(), # y軸のラベル axis.text.y = element_blank(), # y軸の目盛ラベル axis.ticks.x = element_blank(), # x軸の目盛指示線 #panel.grid.major.x = element_line(color = "grey", size = 0.1), # x軸の主目盛線 panel.grid.major.y = element_blank(), # y軸の主目盛線 panel.grid.minor.x = element_blank(), # x軸の補助目盛線 panel.grid.minor.y = element_blank(), # y軸の補助目盛線 panel.border = element_blank(), # グラフ領域の枠線 #panel.background = element_blank(), # グラフ領域の背景 plot.title = element_text(color = "black", face = "bold", size = 20, hjust = 0.5), # 全体のタイトル plot.subtitle = element_text(color = "black", size = 15, hjust = 0.5), # 全体のサブタイトル plot.margin = margin(t = 10, r = 50, b = 10, l = 150, unit = "pt"), # 全体の余白 legend.position = "none" # 凡例の表示位置 ) + # 図の体裁 labs( title = "ハロプログループの平均月齢", subtitle = paste0(lubridate::year(date_val), "年", lubridate::month(date_val), "月時点"), y = "年齢", caption = "データ:「https://github.com/xxgentaroxx/HP_DB」" ) # ラベル graph
y軸(横軸)の値は、データ上では月齢です。これを年齢に対応させて表示します。scale_y_continuous()のbreaks引数に目盛位置、labels引数に目盛ラベルを指定します。年齢を使って目盛位置を指定するには、値を12倍して月齢に変換する必要があります。
ggsave()で画像を保存できます。
# 画像を保存 ggplot2::ggsave( filename = paste0("output/AverageAge_", date_val, ".png"), plot = graph, width = 24, height = 18, units = "cm", dpi = 100 )

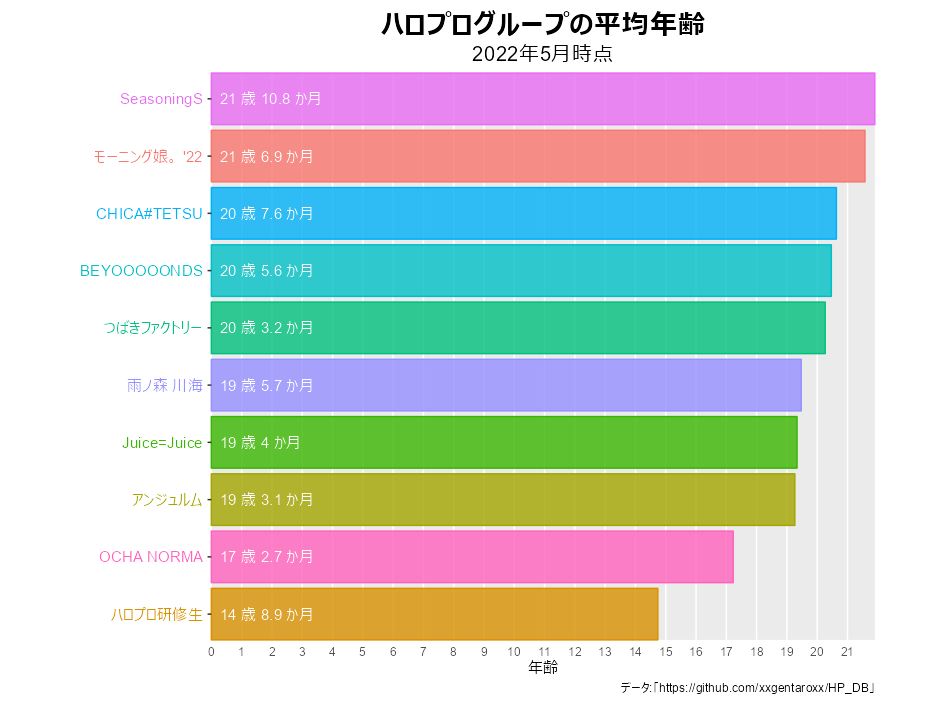
以上で、平均月齢の推移を可視化できました。
おわりに
フレームごとに必ず値が変わるので、バーチャートレースにしがいがありますね。ところで、月齢って言葉で通じますか?月の満ち欠けの方をイメージするでしょうか?
2022年5月30日は、元カントリー・ガールズとJuice=Juiceの稲場愛香さんの卒業の日です。
おめでとうございます!いつかまたパフォーマンスを観られる日を楽しみにしています🍑
この記事の投稿時には、私は卒コンを楽しんでいるはずです。