はじめに
機械学習プロフェッショナルシリーズの『トピックモデル』の勉強時に理解の助けになったことや勉強会用レジュメのまとめです。
この記事では、R言語で混合ユニグラムモデルのパラメータをギブスサンプリングによって推定する方法について書いています。Rの基本的な関数で参考書のアルゴリズム3.3を組むことで、理論をコード・処理の面から理解しようというものです。
パラメータの更新式の導出などはこの記事をご参照ください。
【前節の内容】
【他の節の内容】
【この節の内容】
・コード全体
・テキスト処理
# 利用パッケージ library(RMeCab) library(tidyverse) ### テキスト処理 # 抽出しない単語を指定 stop_words <- "[a-z]" # 小文字のアルファベットを含む語 # 形態素解析 mecab_df <- docDF("フォルダ名", type = 1) # テキストファイルの保存先を指定する # 文書dの語彙vの出現回数(N_dv)の集合 N_dv <- mecab_df %>% filter(grepl("名詞|形容詞|^動詞", POS1)) %>% # 抽出する品詞(大分類)を指定する filter(grepl("一般|^自立", POS2)) %>% # 抽出する品詞(細分類)を指定する filter(!grepl(stop_words, TERM)) %>% # ストップワードを除く select(-c(TERM, POS1, POS2)) %>% # 数値列のみを残す filter(apply(., 1, sum) >= 5) %>% # 抽出する総出現回数を指定する t() # 転置 # 確認用の行列名 dimnames(N_dv) <- list(paste0("d=", 1:nrow(N_dv)), # 行名 paste0("v=", 1:ncol(N_dv))) # 列名 # 文書dの単語数(N_d)のベクトル N_d <- apply(N_dv, 1, sum) # 行方向に和をとる # 文書数(D) D <- nrow(N_dv) # 総語彙数(V) V <- ncol(N_dv)
・パラメータの初期設定
### パラメータの初期設定 # トピック数(K) K <- 4 # 任意の値を指定する # ハイパーパラメータ(alpha, beta) alpha <- 2 # 任意の値を指定する beta <- 2 # 任意の値を指定する # トピックkが割り当てられた文書数(D_{z_d})のベクトルの初期化 D_k <- rep(0, K) # トピックkが割り当てられた文書の語彙vの出現回数(N_{z_d,v})の集合の初期化 N_kv <- matrix(0, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V))) # トピックkが割り当てられた文書の単語数(N_{z_d})のベクトルの初期化 N_k <- rep(0, K) # 文書dのトピック(z_d)のベクトルの初期化 z_d <- rep(0, D)
・ギブスサンプリング
### ギブスサンプリング # 受け皿の用意 p <- NULL # 結果の確認用 trace_alpha <- alpha trace_beta <- beta for(i in 1:3000) { # 任意の回数を指定する # 新たに割り当られてるトピックに関するカウントを初期化 new_D_k <- rep(0, K) new_N_kv <- matrix(0, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V))) new_N_k <- rep(0, K) for(d in 1:D) { ## (各文書:1,...,D) # 現ステップの計算のために前ステップのカウントを移す tmp_D_k <- D_k tmp_N_kv <- N_kv tmp_N_k <- N_k if(z_d[d] > 0) { ## 初回を飛ばす処理 # 前ステップで文書dが与えられたトピックを`k`に代入 k <- z_d[d] # 文書dに関する値をカウントから除く tmp_D_k[k] <- D_k[k] - 1 tmp_N_kv[k, ] <- N_kv[k, ] - N_dv[d, ] tmp_N_k[k] <- N_k[k] - N_d[d] } for(k in 1:K) { ## (各トピック:1,...,K) # サンプリング確率の計算 tmp_p_alpha <- log(tmp_D_k[k] + alpha) # 第1因子 tmp_p_beta1 <- lgamma(tmp_N_k[k] + beta * V) - lgamma(tmp_N_k[k] + N_d[d] + beta * V) # 第2因子 tmp_p_beta2 <- lgamma(tmp_N_kv[k, ] + N_dv[d, ] + beta) - lgamma(tmp_N_kv[k, ] + beta) # 第3因子 p[k] <- exp(tmp_p_alpha + tmp_p_beta1 + sum(tmp_p_beta2)) } ## (/各トピック:1,...,K) # サンプリング tmp_z_d <- rmultinom(n = 1, size = 1, prob = p) # カテゴリ分布によりトピックを生成 z_d[d] <- which(tmp_z_d == 1) # サンプリングの結果を抽出 # 新たに割り当てられたトピックを`k`に代入 k <- z_d[d] # 文書dに関する値をカウントに加える new_D_k[k] <- new_D_k[k] + 1 new_N_kv[k, ] <- new_N_kv[k, ] + N_dv[d, ] new_N_k[k] <- new_N_k[k] + N_d[d] } ## (/各文書:1,...,D) # カウントを更新 D_k <- new_D_k N_kv <- new_N_kv N_k <- new_N_k # ハイパーパラメータ(α)を更新 tmp_alpha_numer1 <- sum(digamma(D_k + alpha)) # 分子 tmp_alpha_numer2 <- K * digamma(alpha) # 分子 tmp_alpha_denom1 <- K * digamma(D + alpha * K) # 分母 tmp_alpha_denom2 <- K * digamma(alpha * K) # 分母 alpha <- alpha * (tmp_alpha_numer1 - tmp_alpha_numer2) / (tmp_alpha_denom1 - tmp_alpha_denom2) # ハイパーパラメータ(β)を更新 tmp_beta_numer1 <- sum(digamma(N_kv + beta)) # 分子 tmp_beta_numer2 <- K * V * digamma(beta) # 分子 tmp_beta_denom1 <- V * sum(digamma(N_k + beta * V)) # 分母 tmp_beta_denom2 <- K * V * digamma(beta * V) # 分母 beta <- beta * (tmp_beta_numer1 - tmp_beta_numer2) / (tmp_beta_denom1 - tmp_beta_denom2) # 結果の確認用 trace_alpha <- c(trace_alpha, alpha) trace_beta <- c(trace_beta, beta) }
・コードの解説
・利用パッケージ
library(RMeCab) library(tidyverse)
形態素解析のためのRMeCab::docDF()と、グラフ作成時のtidyr::gather()、ggplot2関連の関数以外にライブラリの読み込みが必要なのはdplyrのみ。(面倒なのでtidyversパッケージを読み込んでいる)\
テキスト処理の部分の説明は3.3節の記事をご参照ください。
・パラメータの初期設定
・トピック数
# トピック数(K) K <- 4 # 任意の値を指定する
任意のトピック数を指定する。
・パラメータの初期値の指定
# ハイパーパラメータ(alpha, beta) alpha <- 2 # 任意の値を指定する beta <- 2 # 任意の値を指定する
ハイパーパラメータ$\alpha, \beta$の初期値を任意で指定する。
・トピック集合
# 文書dのトピック(z_d)のベクトルの初期化 z_d <- rep(0, D)
z_dは、各文書に割り当てられたトピックで、要素が$D$個のベクトルである。初回はどの文書にもトピックが割り当てられていない状態として、全ての要素を0としておく。
・トピックごとの各カウントの初期化
# トピックkが割り当てられた文書数(D_{z_d})のベクトルの初期化 D_k <- rep(0, K) # トピックkが割り当てられた文書の語彙vの出現回数(N_{z_d,v})の集合の初期化 N_kv <- matrix(0, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V))) # トピックkが割り当てられた文書の単語数(N_{z_d})のベクトルの初期化 N_k <- rep(0, K)
D_kは、トピックごとの割り当てられた文書の数で、要素が$K$個のベクトルである。
N_kvは、各文書に割り当てられたトピックごとに語彙$v$の出現回数を足し合わせた数で、$K$行$V$列のマトリクスである。
N_kは、割り当てられたトピックごとに各文書の単語数$N_d$を足し合わせた数で、要素が$K$個のベクトルである。
初回はどの文書にもトピックが割り当てられていないため、初期値は全て0である。
次からは、forループ内の処理である。
・ギブスサンプリング
・次ステップのカウントの初期化
# 新たに割り当られてるトピックに関するカウントを初期化 new_D_k <- rep(0, K) new_N_kv <- matrix(0, nrow = K, ncol = V, dimnames = list(paste0("k=", 1:K), paste0("v=", 1:V))) new_N_k <- rep(0, K)
new_D_k、new_N_kv、new_N_kは、それぞれ現ステップで割り当てられた文書に関するカウントを加算していく受け皿である。そのため、毎ステップの最初にカウントを0にリセットする。
次からは、for(d in 1:D)のループ内で、各文書順番に処理していく内容である。
・現ステップのカウント
# 現ステップの計算のために前ステップのカウントを移す tmp_D_k <- D_k tmp_N_kv <- N_kv tmp_N_k <- N_k if(z_d[d] > 0) { # 初回を飛ばす処理 # 前ステップで文書dが与えられたトピックを`k`に代入 k <- z_d[d] # 文書dに関する値をカウントから除く tmp_D_k[k] <- D_k[k] - 1 tmp_N_kv[k, ] <- N_kv[k, ] - N_dv[d, ] tmp_N_k[k] <- N_k[k] - N_d[d] }
tmp_D_k、tmp_N_kv、tmp_N_kは、それぞれ$D_{k \backslash d}$、$N_{kv \backslash d}$、$N_{k \backslash d}$のことである。これらの変数は、現ステップでのサンプリング確率の計算に用いる。
文書ごとに処理していくので、毎回前ステップでのカウントを一度移した上で、k番目トピックに関するの要素からd番目の文書に関するカウントを除く。ただし、カウントの初期値は0であるため、初回の処理は行われないようにif(z_d[d] > 0)として条件分岐を行う必要がある。
まず、z_dから前ステップで割り当てられたトピック番号をkに代入する。そのkを添え字として使い、それぞれd番目の文書に関するカウントを引いた値を上書きする。
D_kは文書数であるため、どの文書のときであっても数は1なので、k個目の要素から1を引く。
N_kvのk行目(番目のトピックに関する)の各語彙の出現回数から、N_dvからd行目(番目の文書に関する)の各語彙の出現回数を引く。
N_kのk個目(番目のトピックの)の単語数から、d個目(番目の文書の)単語数を引く。
・サンプリング確率の計算
for(k in 1:K) { # サンプリング確率の計算 tmp_p_alpha <- log(tmp_D_k[k] + alpha) # 第1因子 tmp_p_beta1 <- lgamma(tmp_N_k[k] + beta * V) - lgamma(tmp_N_k[k] + N_d[d] + beta * V) # 第2因子 tmp_p_beta2 <- lgamma(tmp_N_kv[k, ] + N_dv[d, ] + beta) - lgamma(tmp_N_kv[k, ] + beta) # 第3因子 p[k] <- exp(tmp_p_alpha + tmp_p_beta1 + sum(tmp_p_beta2)) }
サンプリング確率の計算は次の式によって行う。
因子ごとに分けて計算する。ただし、gamma()に渡す値が171より大きくなると発散してしまい扱えないため、対数化して計算するlgamma()を使う。そのため、他の値に関しても対数をとって計算を行い、最後にexp()で指数をとる。
トピックごとに1つずつ計算を行い、添え字を使って計算結果をpに代入していくため、最初に空のオブジェクトとしてpを作っておく。
・サンプリング
# サンプリング tmp_z_d <- rmultinom(n = 1, size = 1, prob = p) # カテゴリ分布によりトピックを生成 z_d[d] <- which(tmp_z_d == 1) # サンプリングの結果を抽出
上で求めた確率を基にカテゴリ分布に従ってトピックが決まる。多項分布の乱数発生関数rmultinom()の引数にn = 1、size = 1を指定して試行回数を1回、サンプル数を1つとすることで、カテゴリ分布に従う乱数を発生させる。rmultinom()の結果は、サンプル確率を指定する引数probに渡す要素数の行、nに指定した試行回数の列のマトリクスで返ってくる。
この節の例では、$1, 2, \cdots, K$の行を持つ1列のマトリクスが返ってくる。要素は列ごとに、割り当てられたトピックの行が1でそれ以外は0となる。
出力された$K$行1列のマトリクスにwhich()を使い、要素が1の行番号を検索する。返ってきた値(行番号)がトピック番号に相当するので、それをz_dのd個目の要素に代入する。
・カウントの加算
# 新たに割り当てられたトピックを`k`に代入 k <- z_d[d] # 文書dに関する値をカウントに加える new_D_k[k] <- new_D_k[k] + 1 new_N_kv[k, ] <- new_N_kv[k, ] + N_dv[d, ] new_N_k[k] <- new_N_k[k] + N_d[d]
d番目の文書に関する値を除いたときと同様に今度は加算していく。割り当てられたトピック番号をkに代入して、new_D_k、new_N_kv、new_N_kにそれぞれ対応する値を順次加えていく。
ここまでが文書ごとに処理していく内容であった。ここでの結果を基に、パラメータを更新していく。
・カウントの更新
# カウントを更新 D_k <- new_D_k N_kv <- new_N_kv N_k <- new_N_k
全文書に関するカウントを集計できたので、その結果をそれぞれD_k、N_kv、N_kに上書きする。
・ハイパーパラメータ$\alpha$を更新
# ハイパーパラメータ(α)を更新 tmp_alpha_numer1 <- sum(digamma(D_k + alpha)) # 分子 tmp_alpha_numer2 <- K * digamma(alpha) # 分子 tmp_alpha_denom1 <- K * digamma(D + alpha * K) # 分母 tmp_alpha_denom2 <- K * digamma(alpha * K) # 分母 alpha <- alpha * (tmp_alpha_numer1 - tmp_alpha_numer2) / (tmp_alpha_denom1 - tmp_alpha_denom2)
ハイパーパラメータ$\alpha$の更新は、次の式によって行う。
分かりやすくするために、各項を分けて計算した上で、最後にまとめて計算を行う。ディガンマ関数$\Psi(x)$の計算はdigamma()を使う。
・ハイパーパラメータ$\beta$を更新
# ハイパーパラメータ(β)を更新 tmp_beta_numer1 <- sum(digamma(N_kv + beta)) # 分子 tmp_beta_numer2 <- K * V * digamma(beta) # 分子 tmp_beta_denom1 <- V * sum(digamma(N_k + beta * V)) # 分母 tmp_beta_denom2 <- K * V * digamma(beta * V) # 分母 beta <- beta * (tmp_beta_numer1 - tmp_beta_numer2) / (tmp_beta_denom1 - tmp_beta_denom2)
ハイパーパラメータ$\beta$の更新は、次の式によって行う。
$\alpha$と同様に、$\beta$もdigamma()を使って各項をまず計算する。
・推移の確認
・推移の記録
# 結果の確認用(初期値) trace_alpha <- alpha trace_beta <- beta # 結果の確認用(更新後) trace_alpha <- c(trace_alpha, alpha) trace_beta <- c(trace_beta, beta)
・ハイパーパラメータ
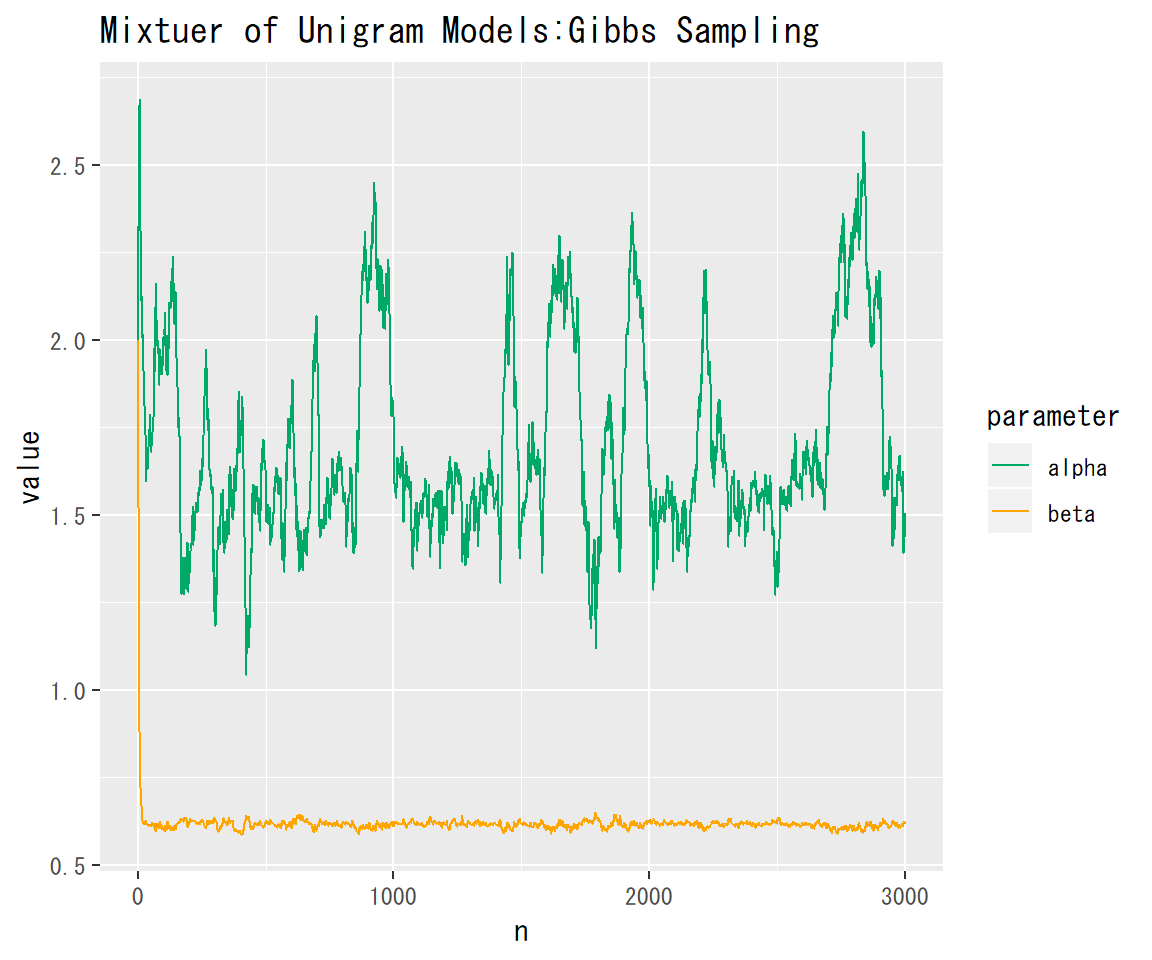
### 推移の確認 # データフレームを作成 ab_df_wide <- data.frame(n = 1:length(trace_alpha), alpha = trace_alpha, beta = trace_beta) # データフレームをlong型に変換 ab_df_long <- gather(ab_df_wide, key = "parameter", value = "value", -n) # 描画 ggplot(ab_df_long, aes(n, value, color = parameter)) + # データの指定 geom_line() + # 折れ線グラフ scale_color_manual(values = c("#00A968", "Orange")) + # グラフの色 labs(title = "Mixtuer of Unigram Models:Gibbs Sampling") # タイトル
参考書籍
- 岩田具治(2015)『トピックモデル』(機械学習プロフェッショナルシリーズ)講談社
おわりに
本当にこれで良いのでしょうか…
2019/08/13:加筆修正しました。
【次節の内容】
- スクラッチ実装編
トピックモデルの生成モデルをプログラムで確認します。
トピックモデルに対する周辺化ギブスサンプリングをプログラムで確認します。
- 数式読解編
トピックモデルの生成モデルを数式で確認します。