はじめに
『スタンフォード ベクトル・行列からはじめる最適化数学』の学習ノートです。
「数式の行間埋め」や「Pythonを使っての再現」によって理解を目指します。本と一緒に読んでください。
この記事は4.3節「k平均法」の内容です。
MNISTデータセットの手書き数字に対するk平均法によるクラスタリングを実装します。
【前の内容】
【他の内容】
【今回の内容】
MNISTデータセットのクラスタリング
MNIST(手書き数字)データセットに対して、k平均法(k-means algorithm)によりクラスタリング(clustering)を行います。
k平均法については「【Python】k平均法による多次元混合ガウス分布のクラスタリングの実装【『スタンフォード線形代数入門』のノート】 - からっぽのしょこ」も参照してください。
利用するライブラリを読み込みます。
# 利用ライブラリ import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
# 読み込み用の設定t import sys sys.path.insert(0, '「ファイルパスを指定」/deep-learning-from-scratch-3-master') # 追加ライブラリ from dezero.datasets import MNIST
DeZeroについては「『ゼロから作るDeep Learning 3』の学習ノート:記事一覧 - からっぽのしょこ」を参照してください。
NumPyのバージョンが1.20以降だと(?)np.intが使えなくて読み込みエラーになるようです。この例では、ゼロつく3巻のサポートページ(GitHub)からライブラリのソースコードを保存して、エラー箇所をnp.int32に置き換えたものを読み込んでいます。
データの読み込み
まずは、MNISTデータセットを読み込みます。
訓練用とテスト用のデータセットを読み込みます。
# データセットを取得 train_set = MNIST(train=True, transform=None) test_set = MNIST(train=False, transform=None) print(len(train_set)) # 訓練データ数 print(len(test_set)) # テストデータ数
60000
10000
dezeroライブラリのMNISTモジュールでMNISTデータセットを取得できます。train引数にTrueを指定すると訓練データ、Falseを指定するとテストデータを返します。
訓練データとして6万枚、テストデータとして1万枚の画像データとラベルデータが格納されています。
訓練用の画像データとラベルデータを取り出します。
# データ数を指定 N = 5000 # ランダムにインデックスを作成 idx = np.random.choice(a=np.arange(len(train_set)), size=N, replace=False) # 画像データを抽出 X = np.array( [train_set[i][0].flatten() / 255.0 for i in idx] ) print(X[:5, 300:305].round(2)) print(X.shape) # ラベルデータを抽出 c_truth = np.array( [train_set[i][1] for i in idx] ) print(c_truth[:5]) print(c_truth.shape)
[[0.99 0.93 0.23 0. 0. ]
[0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. ]
[1. 0.99 0.34 0. 0. ]]
(5000, 784)
[4 1 3 4 2]
(5000,)
データ数を指定して、6万枚分のデータセットからN枚分の画像データ
とラベルデータ
をランダムに抽出して
X, c_truthとします。
各画像データはピクセルなので、1行に並べ替えて
次元ベクトル
として扱います。また、各ピクセルは0から255の整数なので、最大値の255で割って0から1の値に変換します。
各ラベルデータは0から9の10種類なので、真のクラスタ数を、書かれている数字を真のクラスタ
とします。
目安として、クラスタごとの平均と目的関数を計算します。
# 真のクラスタ数を設定:(固定) K_truth = 10 # 真のクラスタの代表値(平均値)を計算 z_truth = np.array( [np.mean(X[c_truth == j], axis=0) for j in range(K_truth)] ) print(z_truth[:5, 300:305].round(2)) print(z_truth.shape) # 目的関数(ノルムの2乗平均)を計算 J_truth = np.array( [np.sum(np.linalg.norm(X[c_truth == j] - z_truth[j], axis=1)**2) / N for j in range(K_truth)] ) print(J_truth.round(1)) print(np.sum(J_truth))
[[0.6 0.61 0.48 0.26 0.07]
[0.01 0. 0. 0. 0. ]
[0.3 0.16 0.06 0.02 0. ]
[0.18 0.09 0.03 0.01 0. ]
[0.33 0.19 0.09 0.03 0.01]]
(10, 784)
[4.9 2.7 4.9 4.7 4. 3.9 4.3 4. 4.5 3.7]
41.64103082489797
真のクラスタごとのデータの平均値を代表値、
とします。
はクラスタ
の集合
、
は
の要素数を表します。
「クラスタリング」で確認する目的関数と同様に、次の式を計算します。
個の
を
J_truthとします。
は、ユークリッドノルムで、
np.linalg.norm()で計算できます。
手書き数字を確認します。
# 描画枚数を指定 plot_num = 16 # サブプロットの列数を指定(1行になるとエラーになる) col_num = 4 row_num = plot_num // col_num row_num += 0 if plot_num%col_num == 0 else 1 # 割り切れない場合は1行加える # 手書き数字を描画 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(7, 7), facecolor='white') fig.suptitle('MNIST data', fontsize=20) # 手書き数字を作図 for i in range(plot_num): # サブプロットのインデックスを計算 l = i // col_num m = i % col_num # 平均との距離を計算 dist = np.linalg.norm(X[i] - z_truth[c_truth[i]]) # i番目の画像を描画 axes[l, m].imshow(X[i].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$c_{' + str(i+1) + '}^{truth}=' + str(c_truth[i]) + ', ' + '\|x_{' + str(i+1) + '}-z_{' + str(c_truth[i]) + '}^{truth}\|=' + str(dist.round(1)) + '$', loc='left', fontsize=8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') plt.show()

手書き数字のベクトルをの2次元配列に戻して、
axes.imshow()でヒートマップとして描画します。
以上で、クラスタリングに利用する手書き数字データを用意できました。
クラスタリング
次は、手書き数字データ(784次元ベクトル)に対するk平均法を実装します。
クラスタの初期値をランダムに割り当てて、クラスタごとに代表値として平均値を計算します。
# クラスタ数の初期値を指定 K = 20 # ランダムにクラスタを割り当て c_onehot = np.random.multinomial(n=1, pvals=np.repeat(1, K)/K, size=N) print(c_onehot[:5]) # クラスタ番号を抽出 _, c = np.where(c_onehot == 1) print(c[:5]) # クラスタごとのデータ数を集計 G_num = np.sum(c_onehot, axis=0) print(G_num) # クラスタの代表値(平均値)を計算 Z = np.array( [np.mean(X[c == j], axis=0) for j in range(K)] ) print(Z[:5, 300:305].round(2)) # 目的関数(ノルムの2乗平均)を計算 J = np.array( [np.sum(np.linalg.norm(X[c == j] - Z[j], axis=1)**2) / N for j in range(K)] ) print(J[:5].round(1)) print(np.sum(J))
[[0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
[6 4 8 6 4]
[230 271 242 258 257 245 274 260 257 234 246 257 271 231 242 253 256 230
241 245]
[[0.28 0.2 0.11 0.04 0.02]
[0.26 0.18 0.1 0.04 0.01]
[0.28 0.19 0.11 0.06 0.02]
[0.27 0.22 0.13 0.07 0.03]
[0.27 0.16 0.1 0.05 0.02]]
[2.5 2.8 2.5 2.8 2.7]
52.419958361053865
クラスタ数の初期値として、真のクラスタ数
以上の値を指定します。
多項分布の乱数生成関数np.random.multinomial()の試行回数の引数nに1を指定して、カテゴリ分布の乱数を生成します。パラメータ(割り当て確率)の引数pvalsに混合比率pi、サンプルサイズの引数sizeにデータ数Nを指定します。
one-hotベクトル(クラスタ番号に対応する列が1でそれ以外の列が0の行)をまとめたN行K_truth列の配列が出力されるので、np.where()で行ごとに値が1の列番号を抽出して、データごとクラスタ、
の初期値とします。
各列の値が1の行数が、各クラスタが割り当てられたデータ数です。他の要素は0なので、列ごとの和で得られます。
各クラスタが割り当てられたデータの平均値を代表値、
とします。
は(初期値や推定値の)クラスタ
の集合
、
は
の要素数を表します。
各データと割り当てられたクラスタの代表値
の距離
の2乗平均を目的関数とします。
個の
を
Jとします。
クラスタごとの代表値の初期値をグラフで確認します。
# サブプロットの列数を指定(1行になるとエラーになる) col_num = 5 row_num = K // col_num row_num += 0 if K%col_num == 0 else 1 # 割り切れない場合は1行加える # 手書き数字を描画 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(8, 8), facecolor='white') fig.suptitle('initial cluster representative', fontsize=20) # K個の代表値を作図 for j in range(K): # サブプロットのインデックスを計算 l = j // col_num m = j % col_num # j番目の代表値を描画 axes[l, m].imshow(Z[j].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$z_{' + str(j+1) + '}^{(0)}, ' + '|G_{' + str(j+1) + '}|=' + str(G_num[j]) + ', ' + 'J_{' + str(j+1) + '}=' + str(J[j].round(2))+ '$', loc='left', fontsize = 8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') plt.show()
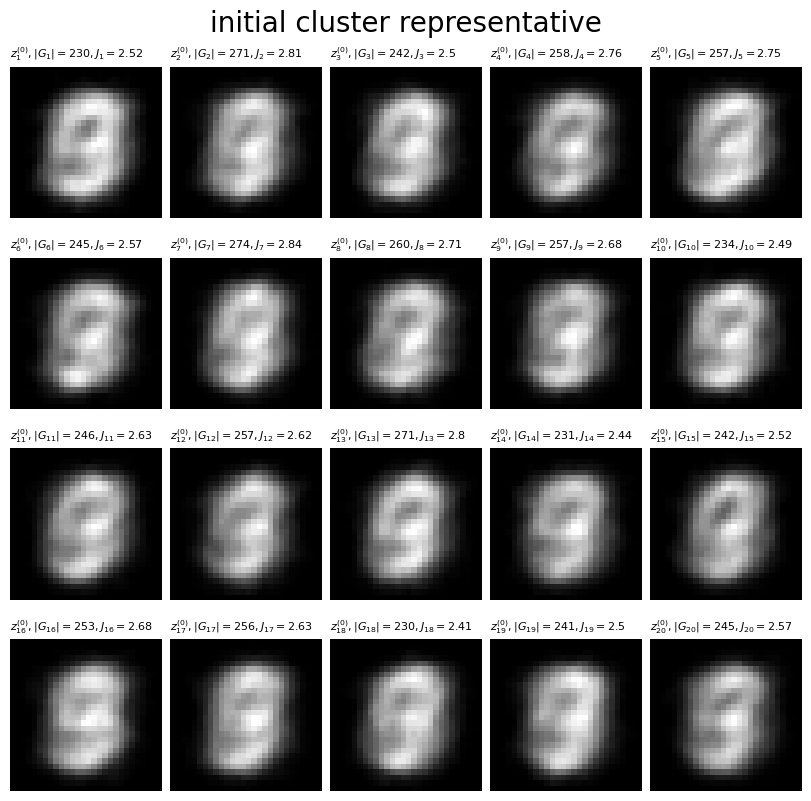
手書き数字の作図のときと同様にして、代表値の初期値を作図します。
どのクラスタの代表値も、全ての数字を重ねたようなベクトル(ヒートマップ)になっています。
k平均法によりクラスタと代表値を繰り返し更新します。
# クラスタの最低割り当て数を指定 G_num_lower = 150 # 更新量の閾値を指定 threshold = 0.001 # 初期値を記録 trace_Z = [Z] trace_c = [c] trace_G = [G_num] trace_J = [J] # 繰り返し試行 cnt = 0 old_J_sum = np.sum(J) while True: # 試行回数をカウント cnt += 1 print('--- iter:' + str(cnt) + ' ---') # クラスタの代表値(平均値)を計算 Z = np.array( [np.mean(X[c == j], axis=0) for j in range(K) if G_num[j] >= G_num_lower] ) # クラスタ数を再設定 K = len(Z) print('K=' + str(K)) # ノルムが最小のクラスタを割り当て c = np.argmin( [np.linalg.norm(X - Z[j], axis=1) for j in range(K)], axis=0 ) # クラスタごとのデータ数を集計 G_num = np.array( [np.sum(c == j) for j in range(K)] ) print('|G|=' + str(G_num)) # 目的関数(ノルムの2乗平均)を計算 J = np.array( [np.sum(np.linalg.norm(X[c == j] - Z[j], axis=1)**2) / N for j in range(K)] ) J_sum = np.sum(J) print('J=' + str(J_sum)) # 更新値を記録 trace_Z.append(Z) trace_c.append(c) trace_G.append(G_num) trace_J.append(J) # 更新量が閾値未満なら終了 if abs(J_sum - old_J_sum) < threshold: break # 目的関数の値を保存 old_J_sum = J_sum
--- iter:1 ---
K=20
|G|=[724 92 64 266 178 183 84 467 459 36 50 520 510 288 175 259 155 59
378 53]
J=50.67184146497588
--- iter:2 ---
K=13
|G|=[501 281 327 300 421 337 551 506 466 212 382 332 384]
J=41.19493118884337
--- iter:3 ---
K=13
|G|=[424 286 362 324 400 289 511 503 491 248 391 364 407]
J=39.36714109366748
(省略)
--- iter:24 ---
K=13
|G|=[366 346 242 429 381 356 463 362 427 486 402 468 272]
J=37.53972799326367
--- iter:25 ---
K=13
|G|=[366 346 241 428 381 356 464 364 428 487 400 467 272]
J=37.53737437160713
--- iter:26 ---
K=13
|G|=[364 344 241 428 381 356 464 365 428 489 399 469 272]
J=37.53672695761081
クラスタに含まれるデータ数が一定数未満になると、そのクラスタを削除することにします。
下限値をG_num_lowerとして指定して、クラスタjのデータ数G_num[j]がG_num_lower以上のときのみ代表値(平均値)を計算します。クラスタが削除される(計算されないクラスタがある)と、クラスタ番号(行インデックス)が変わります。
Zの行数をKとして、クラスタ数を更新します。
各データと各クラスタの代表値
との距離
が最小となるクラスタ
をそのデータのクラスタ
とします。
最小値のインデックスはnp.argmin()で得られます。
こちらの方法では、one-hotベクトルのクラスタ番号が不要なので、cに含まれる1からKの要素数をカウントして、クラスタごとのデータ数G_numとします。
目的関数の計算については、初期化時と同じです。
閾値thresholdを指定し、前ステップの値をold_J_sumとしておき、更新値J_sumとの差の絶対値が閾値未満になると、収束したとみなしてbreakでループ処理を終了します。
更新推移の確認用に、値(配列)をtrace_*に記録していきます。
クラスタごとの代表値の更新値(収束結果)をグラフで確認します。
# サブプロットの列数を指定(1行になるとエラーになる) col_num = 5 row_num = K // col_num row_num += 0 if K%col_num == 0 else 1 # 割り切れない場合は1行加える # 手書き数字を描画 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(8, 6), facecolor='white') fig.suptitle('k-means algorithm', fontsize=20) # K個の代表値を作図 for j in range(K): # サブプロットのインデックスを計算 l = j // col_num m = j % col_num # j番目の代表値を描画 axes[l, m].imshow(Z[j].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$z_{' + str(j+1) + '}^{(' + str(cnt) + ')}, ' + '|G_{' + str(j+1) + '}|=' + str(G_num[j]) + ', ' + 'J_{' + str(j+1) + '}=' + str(J[j].round(2))+ '$', loc='left', fontsize=8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') plt.show()

これまでと同様にして、代表値の更新値を作図します。
特定の数字を代表するようなベクトル(ヒートマップ)になっているクラスタや、複数の数字の中間的なベクトルになっているクラスタを確認できます。また、複数のクラスタが同じ数字を示すことや、どのクラスタも示さない数字が存在することもあります。
「手書き数字の識別」で利用するために、数字ラベルを〝目視確認の手打ちで〟設定します。
# 手書き数字ラベルを指定 number_label = np.array( [0, 8, 6, 9, 1, 2, 1, 6, 4, 9, 5, 3, 7] )
クラスタ番号は、手書き数字とは無関係に割り当てられます。そこで、各クラスタに対応している数字をnumber_labelとして、〝目視確認の手打ちで〟指定します。
同じクラスタが割り当てられた手書き数字を確認します。
# 表示するクラスタ番号を指定 j = 1 # 描画枚数を指定 plot_num = 16 # クラスタjのデータインデックスを抽出 j_idx, = np.where(c == j) # サブプロットの列数を指定(1行になるとエラーになる) col_num = 4 row_num = plot_num // col_num row_num += 0 if plot_num%col_num == 0 else 1 # 割り切れない場合は1行加える # 手書き数字を描画 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(7, 7), facecolor='white') fig.suptitle('MNIST data', fontsize=20) # 手書き数字を作図 for i in range(plot_num): # サブプロットのインデックスを計算 l = i // col_num m = i % col_num # クラスタjのi番目の画像のインデックスを抽出 idx = j_idx[i] # 代表値との距離を計算 dist = np.linalg.norm(X[idx] - Z[c[idx]]) # i番目の画像を描画 axes[l, m].imshow(X[idx].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$c_{' + str(idx+1) + '}^{truth}=' + str(c_truth[idx]) + ', ' + '\|x_{' + str(idx+1) + '}-z_{' + str(c[idx]) + '}\|=' + str(dist.round(2)) + '$', loc='left', fontsize=8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') plt.show()



描画するクラスタ番号をjとして指定します。
cの値がjのインデックスをj_idxとしておき、plot_num番目までのインデックスの手書き数字を描画します。
目的関数の推移を確認します。
# 目的関数の推移を作図 fig, ax = plt.subplots(figsize=(8, 6), facecolor='white') ax.plot(np.arange(cnt+1), [np.sum(J) for J in trace_J]) # 目的関数 ax.set_xlabel('iteration') ax.set_ylabel('$J^{clust}$') ax.set_title('N=' + str(N) + ', K=' + str(K), loc='left') fig.suptitle('objective function', fontsize=20) ax.grid() plt.show()
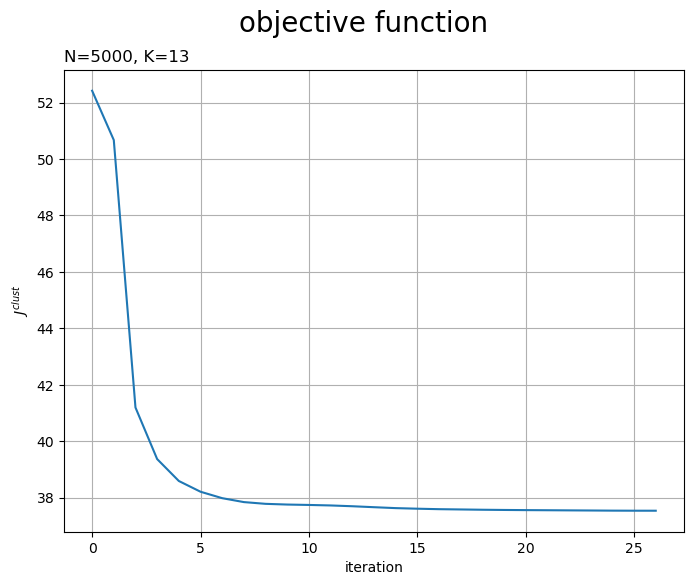
試行の度に目的関数が下がるのを確認できます。ただし、クラスタ数の変更時には値が上がることがあります。
更新の様子をアニメーションで確認します。
・作図コード(クリックで展開)
# フレーム数を設定 frame_num = cnt # クラスタ数の初期値(最大値)を設定 K_init = len(trace_Z[0]) # サブプロットの列数を指定(1行になるとエラーになる) col_num = 5 row_num = K_init // col_num row_num += 0 if K_init%col_num == 0 else 1 # 割り切れない場合は1行加える # グラフオブジェクトを初期化 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(10, 8), facecolor='white') fig.suptitle('k-means algorithm', fontsize=20) # 作図処理を関数として定義 plot_flg = np.repeat(True, repeats=K_init) def update(i): # i回目の値を取得 Z = trace_Z[i] c = trace_c[i] G_num = trace_G[i] J = trace_J[i] # 描画するクラスタ(削除されていないクラスタ番号)を設定 if i > 0: plot_flg[plot_flg] = trace_G[i-1] >= G_num_lower # i回目におけるクラスタ番号のカウントを初期化 j = 0 # K個の代表値を作図 for k in range(K_init): # サブプロットのインデックスを計算 l = k // col_num m = k % col_num if plot_flg[k]: # クラスタjの代表値を作図 axes[l, m].clear() # 前フレームのグラフを初期化 axes[l, m].imshow(Z[j].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$z_{' + str(k+1) + '}^{(' + str(i) + ')}, ' + '|G_{' + str(k+1) + '}|=' + str(G_num[j]) + ', ' + 'J_{' + str(k+1) + '}=' + str(J[j].round(2))+ '$', loc='left', fontsize=8) # i回目におけるクラスタ番号をカウント j += 1 else: # 削除されたクラスタを非表示 axes[l, m].clear() # 前フレームのグラフを初期化 axes[l, m].axis('off') axes[l, m].set_title('$z_{' + str(k+1) + '}$', loc='left', fontsize=8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') # gif画像を作成 ani = FuncAnimation(fig=fig, func=update, frames=frame_num, interval=300) # gif画像を保存 ani.save('k_means_mnist.gif')
作図処理をupdate()として定義して、FuncAnimation()でgif画像を作成します。

徐々に特定の数字を示すようなベクトル(ヒートマップ)に近付くのが分かります。これは、各クラスタが特定の数字に割り当てられ(上手くクラスタリングされることで)、代表値がその数字の平均値になるためです。
以上で手書き数字のクラスタリングを行えました。次は、クラスタリング結果を利用します。
手書き数字の識別
クラスタごとの代表値を用いて、手書き数字を識別します。
テスト用の画像データとラベルデータを取り出します。
# データ数を指定 N = 1000 # ランダムにインデックスを作成 idx = np.random.choice(a=np.arange(len(test_set)), size=N, replace=False) # 画像データを抽出 X = np.array( [test_set[i][0].flatten() / 255.0 for i in idx] ) print(X.shape) # ラベルデータを抽出 c_truth = np.array( [test_set[i][1] for i in idx] ) print(c_truth.shape)
(1000, 784)
(1000,)
「データの読み込み」のときと同様にして、テスト用のデータを抽出します。
テストデータ(未知の数字)に対して、代表値との距離が最小となるクラスタを割り当てます。
# ノルムが最小のクラスタ番号を割り当て c_estimate = np.argmin( [np.linalg.norm(X - Z[j], axis=1) for j in range(K)], axis=0 ) print(c_estimate[:5]) # 手書き数字ラベルを抽出 number_estimate = number_label[c_estimate] print(number_estimate[:5])
[9 3 6 4 7]
[9 9 1 1 6]
クラスタリング時と同様にして、各データにクラスタを割り当てます。ただし、クラスタ番号は、書かれている数字とは無関係な値でした。
そこで、クラスタ番号をインデックスとして使い、〝目視確認の手打ちで〟設定した数字ラベルnumber_labelから値を抽出してnumber_estimateとします。
識別精度を測定します。
# 精度を計算 acc = np.sum(number_estimate == c_truth) / N print(acc)
0.634
推定したラベルnumber_estimateと真のラベルc_truthが一致した数をデータ数で割って、正解率を求めます。
手書き数字の識別結果をグラフで確認します。
# 描画枚数を指定 plot_num = 16 # サブプロットの列数を指定(1行になるとエラーになる) col_num = 4 row_num = plot_num // col_num row_num += 0 if plot_num%col_num == 0 else 1 # 割り切れない場合は1行加える # 手書き数字を描画 fig, axes = plt.subplots(nrows=row_num, ncols=col_num, constrained_layout=True, figsize=(7, 7), facecolor='white') fig.suptitle('MNIST data', fontsize=20) # 手書き数字を作図 for i in range(plot_num): # サブプロットのインデックスを計算 l = i // col_num m = i % col_num # i番目の画像を描画 axes[l, m].imshow(X[i].reshape((28, 28)), cmap='gray') axes[l, m].axis('off') axes[l, m].set_title('$c_{' + str(i+1) + '}^{truth}=' + str(c_truth[i]) + ', ' + 'c_{' + str(i+1) + '}^{estimate}=' + str(number_estimate[i]) +'$', loc='left', fontsize=8) # 余ったサブプロットを非表示 for n in range(m+1, col_num): axes[l, n].axis('off') plt.show()
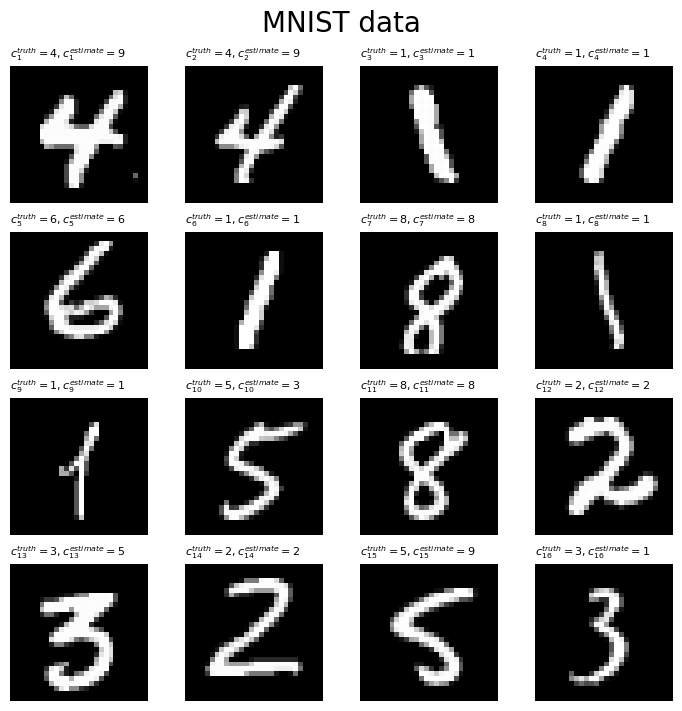
「3・5・8」や「4・7・9」を混同しやすいようです。これは、代表値をグラフで確認した際に、中間的な文字になりやすいことからも分かります。
この記事では、MNISTデータセットに対するk平均法を実装しました。次の記事では、ベクトルの線形独立と線形従属を確認します。
参考書籍
- Stephen Boyd・Lieven Vandenberghe(著),玉木 徹(訳)『スタンフォード ベクトル・行列からはじめる最適化数学』講談社サイエンティク,2021年.
おわりに
4章はほぼ同じ内容のでも全然違って見える2記事で完了です。3章後半とセットな内容でした。
前回は2・3次元データのクラスタリングで、今回は784次元データのクラスタリングでした。NumPy関数がよしなにしてくれるので、次元の違いに関わらず同じコードで処理できました。
2つの記事を通じて、可視化できない多次元空間でも距離(近さ)を定義できて類似度として扱えるのを感覚的に掴めればと思います。
これまでも別の手法でMNISTデータセットを識別(認識)しました。こっちも面白いので覗いてみてください。
ここまでは毎日更新できてたのですが、5章の解説が呪文すぎて、予約記事ストックに追いつかれそうです。
【次の内容】