はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、4.2.3節の内容です。反復方策評価アルゴリズムを実装して状態価値関数を求めます。
【前節の内容】
【他の記事一覧】
【この記事の内容】
4.2.3 反復方策評価の実装
前節では、2マスのグリッドワールドを扱いました。この項では、3×4マスのグリッドワールド(図4-8)に対して、反復方策評価アルゴリズムにより「ある方策における状態価値関数」を求めます。ある方策における状態価値関数を求めることは、その方策の価値を計算することなので、方策を評価すると表現します。反復方策評価や状態価値関数の更新式については「4.1:動的計画法と方策評価【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
利用するライブラリを読み込みます。
# 利用するライブラリを読み込み import numpy as np from collections import defaultdict # 追加ライブラリ import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation from matplotlib.colors import LinearSegmentedColormap
MatplotlibライブラリのanimationモジュールからFuncAnimationを使って、推移の確認用のアニメーションを作成します。その際に、colorsモジュールからLinearSegmentedColormapも使います。不要であれば省略してください。
また、3×4マスのグリッドワールドのクラスGridWorldを読み込みます。
# 実装済みのクラスを読み込み import sys sys.path.append('../deep-learning-from-scratch-4-master') from common.gridworld import GridWorld
GridWorldクラスについては「4.2.1:GridWorldクラスの実装【ゼロつく4のノート】 - からっぽのしょこ」を参照してください。
・eval_onestep関数の実装
まずは、反復方策評価アルゴリズムにより状態価値関数を1回更新する処理を関数eval_onestep()として実装します。
・計算式の確認
関数内で行う計算について数式で確認します。
反復方策評価アルゴリズムによる状態価値関数の更新式は、次の式でした(4.1節)。
図4-8の問題設定では、上下左右の行動を取るので4つの行動を$\{\mathrm{Up}, \mathrm{Down}, \mathrm{Left}, \mathrm{Right}\}$で表すと、更新式は次のようになります。
この式は、上下左右それぞれの行動で波括弧の計算を行い、その行動となる確率$\pi(a | s)$を掛けて、全ての行動の和を求めることを表しています。
具体的な値を使って、初回($k = 0$)の計算をしてみます。
図4-9の設定に従って、縦方向のマス番号を$h$、横方向のマス番号を$w$として、各マスを$L_{h,w}$で表すと、爆弾のマス$L_{1,3}$の状態価値関数$V_1(L_{1,3})$は、次の式になります。
この例では、各行動は等確率(それぞれ0.25)でランダムに決まり、報酬は図4-8の設定です。それぞれ代入します。
さらに、各状態の価値関数の初期値$V_0(s)$を0とします。
以上で、1回更新した状態価値関数の推定値が得られました。
ただし、これから実装するプログラムでは、左上のマス$L_{0,0}$から図4-12の順番に状態価値を求めます。そのため、$V_1(L_{1,3})$の計算時には$V_1(L_{1,2}) = -0.19$が得られているので、$V_1(L_{1,3}) = 0.25 \gamma V_1(L_{1,2})$になります。よって、割引率を$\gamma = 0.9$とすると、$V_1(L_{1,3}) = -0.04$になります。
この計算を全ての状態で行い、各状態の価値関数$V_1(s)$を求めます。さらに、$V_1(s)$を使って$V_2(s)$を求めます(状態価値関数を更新します)。これを繰り返すことで、ある方策(この例では等確率でランダムな方策)における状態価値関数が得られます。
このアルゴリズムは、更新を繰り返して方策$\pi$における状態価値関数を求める、つまり反復計算によって方策の価値を求める(方策を評価する)ことから、反復方策評価と呼ばれます。
数式での計算を確認できたので、プログラムでの計算を確認します。その前に、数式上の変数・関数と、プログラム上の変数(オブジェクト)・関数(メソッド)の対応を確認しておきます。
現在の状態$s$はstate、次の状態$s'$はnext_state、各状態の価値関数$V_k(s)$はV[state]、各行動$a$はaction、行動$a$の確率$\pi(a | s)$はaction_prob、状態遷移関数$f(s, a)$はenv.next_state()、報酬関数$r(s, a, s')$はenv.reward()に対応します。また、for文により全ての行動における計算結果をnew_Vに加える処理が$\sum_{a \in \{\mathrm{U}, \mathrm{D}, \mathrm{L}, \mathrm{R}\}}$に対応します。
・処理の確認
続いて、eval_onestep()の内部で行われる処理を確認します。
引数に指定する(関数内で利用する)オブジェクトを作成します。
# グリッドワールドのインスタンスを作成 env = GridWorld() # 全ての確率論的方策を指定 pi = defaultdict(lambda: {0: 0.25, 1:0.25, 2: 0.25, 3: 0.25}) # 全ての状態価値関数を初期化 V = defaultdict(lambda: 0) # 割引率を指定 gamma = 0.9
GridWorldクラスのインスタンスenvを作成します。
全てのマスの確率論的方策のディクショナリを格納したディクショナリpiを作成します。この例では、全ての状態で、各行動(上下左右)が等しい確率で起きるとします。
全てのマスの状態価値関数の初期値を0として格納したディクショナリVを作成します。
割引率gammaを指定します。
初期値による状態価値関数のヒートマップを確認しましょう。
# 状態価値関数のヒートマップを作図
env.render_v(v=V, policy=pi)
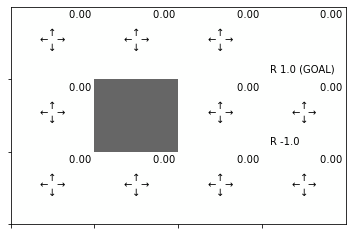
全ての状態(マス)で初期値が0なので、全て白色になっています。
反復方策評価により状態価値関数を1回更新します。
# 状態ごとに処理 for state in env.states(): # ゴールの場合 if state == env.goal_state: # 状態価値は常に0 V[state] = 0 continue # 以降は処理せず次の状態へ # 方策(確率分布)を抽出 action_probs = pi[state] # 次の状態価値を初期化 new_V = 0 # 行動ごとに処理 for action, action_prob in action_probs.items(): # 次の状態を取得 next_state = env.next_state(state, action) # 報酬を取得 r = env.reward(state, action, next_state) # 状態価値関数を計算:式(4.3) new_V += action_prob * (r + gamma * V[next_state]) # 状態価値関数を更新 V[state] = new_V # 結果を確認 print(list(V.keys())) # 状態 print(np.round(list(V.values()), 2)) # 状態価値
[(0, 0), (1, 0), (0, 1), (0, 2), (1, 2), (0, 3), (2, 0), (2, 1), (1, 1), (2, 2), (1, 3), (2, 3)]
[ 0. 0. 0. 0.25 -0.19 0. 0. 0. 0. -0.04 -0.04 -0.27]
for文とstate()メソッドを使って、状態ごとに処理します。
この例の問題設定では、ゴールに辿り着くとエピソード終了なので、ゴールのマスの状態価値は常に0になります。そのため、0を代入して、その後の処理はcontinueで飛ばして次の状態に移ります。
piから各状態の確率論的方策action_probsを取り出して、for文で行動ごとに処理します。
next_state()メソッドで次の状態、reward()メソッドで報酬を取得して、更新式(4.3)の計算を行い状態価値を更新します(書き換えます)。
全ての状態(マス)を1回更新した状態価値関数のヒートマップを作成します。
# 状態価値関数のヒートマップを作図
env.render_v(v=V, policy=pi)
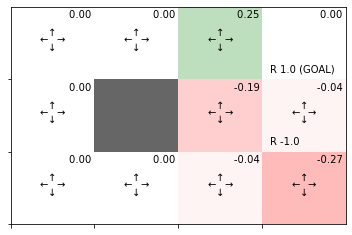
爆弾(負の報酬)の付近の状態価値がマイナス(赤色)に、ゴール(正の報酬)の隣の状態価値がプラス(緑色)になっています。
以上が、反復方策評価における1回の更新処理です。
・実装
処理の確認ができたので、反復方策評価アルゴリズムの1回の更新処理を関数として実装します。eval_onestep関数の定義については、次のページを参照してください。
実装した関数を試してみましょう。
# グリッドワールドのインスタンスを作成 env = GridWorld() # 全ての確率論的方策を指定 pi = defaultdict(lambda: {0: 0.25, 1:0.25, 2: 0.25, 3: 0.25}) # 全ての状態価値関数を初期化 V = defaultdict(lambda: 0) # 割引率を指定 gamma = 0.9 # 状態価値関数を更新 V = eval_onestep(pi, V, env, gamma) # 状態価値関数のヒートマップを作図 env.render_v(v=V, policy=pi)
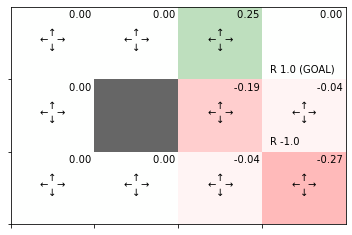
処理の確認時と同じ結果が得られました。
以上で、1回の更新処理を実装できました。次は、収束するまで更新を繰り返す関数を実装します。
・policy_eval関数の実装
次は、反復方策評価アルゴリズムにより状態価値関数を収束するまで更新する関数をpolicy_eval()として実装します。
・処理の確認
policy_eval()の内部で行われる処理を確認します。
先ほどと同様に、引数に指定する(関数内で利用する)オブジェクトを作成します。
# グリッドワールドのインスタンスを作成 env = GridWorld() # 全ての確率論的方策を指定 pi = defaultdict(lambda: {0: 0.25, 1:0.25, 2: 0.25, 3: 0.25}) # 全ての状態価値関数を初期化 V = defaultdict(lambda: 0) # 割引率を指定 gamma = 0.9 # 閾値を指定 threshold =0.001
先ほどに加えて、閾値thresholdを指定します。
反復方策評価によって、状態価値関数を更新幅が閾値を下回るまで繰り返し更新します。
# 記録用のリストを初期化 trace_V = [{state: 0 for state in env.states()}] # 初期値を記録 # 試行回数のカウントを初期化 cnt = 0 # 繰り返し処理 while True: # 現在の状態価値を複製 old_V = V.copy() # 状態価値関数を更新:式(4.3) V = eval_onestep(pi, V, env, gamma) # 更新幅の最大値を初期化 delta = 0 # 更新幅の最大値を記録 for state in V.keys(): # 更新量の絶対値を計算 t = abs(V[state] - old_V[state]) # 最大値を更新したら記録 if delta < t: delta = t # 試行回数をカウント cnt += 1 # 途中経過を表示 print('iter', cnt, ': delta', delta) # 状態価値関数の更新値を記録 trace_V.append(V.copy()) # 更新幅が閾値未満になると終了 if delta < threshold: break
iter 1 : delta 0.26961718749999997
iter 2 : delta 0.1593603588867188
iter 3 : delta 0.10277391199493408
(省略)
iter 22 : delta 0.0010770081863089864
iter 23 : delta 0.0009152085452608441
更新量を計算するため、現在の状態価値をold_Vとして保存しておきます。
eval_onestep()で状態価値関数を1回更新します。
更新後の値Vと更新前の値old_Vの差の絶対値を各状態で計算し、最大値をdeltaとします。
deltaがthresholdを下回ると、while文による繰り返し処理をbreakで終了します。
途中経過の出力を見ると、23回更新されたのが分かります。
最終結果(収束した状態価値関数)のヒートマップを作成します。
# 状態価値関数のヒートマップを作図
env.render_v(v=V, policy=pi)
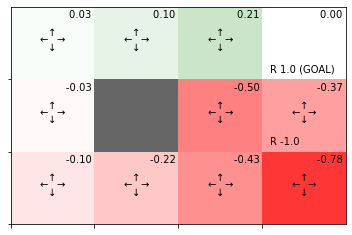
この結果の解釈については本を参照してください。
・更新推移の可視化
ここまでで、繰り返しの更新処理を確認できました。続いて、途中経過をアニメーションで確認します。
状態価値関数のヒートマップのアニメーションを作成します。
・作図コード(クリックで展開)
# グリッドマップのサイズを取得 xs = env.width ys = env.height # 最後の状態価値の最小値・最大値を取得 vmin = min(trace_V[-1].values()) vmax = max(trace_V[-1].values()) # 色付け用に最小値・最大値を再設定 vmax = max(vmax, abs(vmin)) vmin = -1 * vmax if vmax < 1: vmax = 1 if vmin > -1: vmin = -1 # カラーマップを設定 color_list = ['red', 'white', 'green'] cmap = LinearSegmentedColormap.from_list('colormap_name', color_list) # 図を初期化 fig = plt.figure(figsize=(9, 6)) # 図の設定 plt.suptitle('Iterative Policy Evaluation', fontsize=20) # 全体のタイトル # 作図処理を関数として定義 def update(i): # 前フレームのグラフを初期化 plt.cla() # i回目の更新値を取得 V = trace_V[i] # ディクショナリを配列に変換 v = np.zeros((env.shape)) for state, value in V.items(): v[state] = value # 状態価値のヒートマップを描画 plt.pcolormesh(np.flipud(v), cmap=cmap, vmin=vmin, vmax=vmax) # ヒートマップ # マス(状態)ごとに処理 for state in env.states(): # インデックスを取得 y, x = state # 報酬を抽出 r = env.reward_map[state] # 報酬がある場合 if r != 0 and r is not None: # 報酬ラベル用の文字列を作成 txt = 'R ' + str(r) # ゴールの場合 if state == env.goal_state: # 報酬ラベルにゴールを追加 txt = txt + ' (GOAL)' # 報酬ラベルを描画 plt.text(x=x+0.1, y=ys-y-0.9, s=txt) # 壁以外の場合 if state != env.wall_state: # 状態価値ラベルを描画 plt.text(x=x+0.4, y=ys-y-0.15, s='{:12.2f}'.format(v[y, x])) # 確率が最大の行動を抽出 actions = pi[state] max_actions = [k for k, v in actions.items() if v == max(actions.values())] # 矢印の描画用のリストを作成 arrows = ['↑', '↓', '←', '→'] offsets = [(0, 0.1), (0, -0.1), (-0.1, 0), (0.1, 0)] # 行動ごとに処理 for action in max_actions: # 矢印の描画用の値を抽出 arrow = arrows[action] offset = offsets[action] # ゴールの場合 if state == env.goal_state: # 描画せず次の状態へ continue # 方策ラベル(矢印)を描画 plt.text(x=x+0.45+offset[0], y=ys-y-0.5+offset[1], s=arrow, fontsize=20) # 壁の場合 if state == env.wall_state: # 壁を描画 plt.gca().add_patch(plt.Rectangle(xy=(x, ys-y-1), width=1, height=1, fc=(0.4, 0.4, 0.4, 1.0))) # 長方形を重ねる # マスを描画 plt.xticks(ticks=np.arange(xs)) # x軸の目盛位置 plt.yticks(ticks=np.arange(ys)) # y軸の目盛位置 plt.xlim(xmin=0, xmax=xs) # x軸の範囲 plt.ylim(ymin=0, ymax=ys) # y軸の範囲 plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) # 軸ラベル plt.grid() # グリッド線 plt.title('iter:'+str(i), loc='left') # タイトル # gif画像を作成 anime = FuncAnimation(fig, update, frames=len(trace_V), interval=100) # gif画像を保存 anime.save('policy_eval.gif')
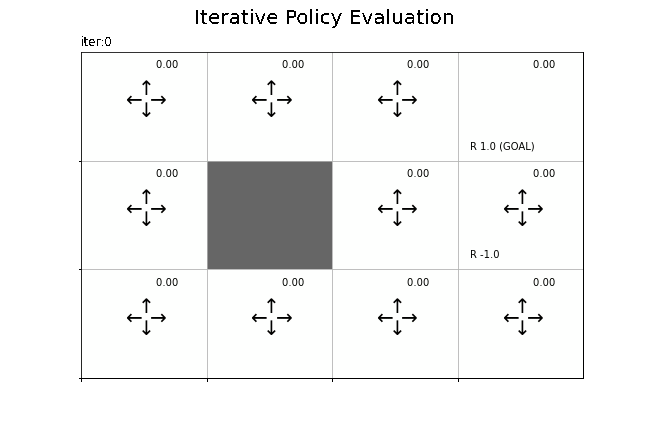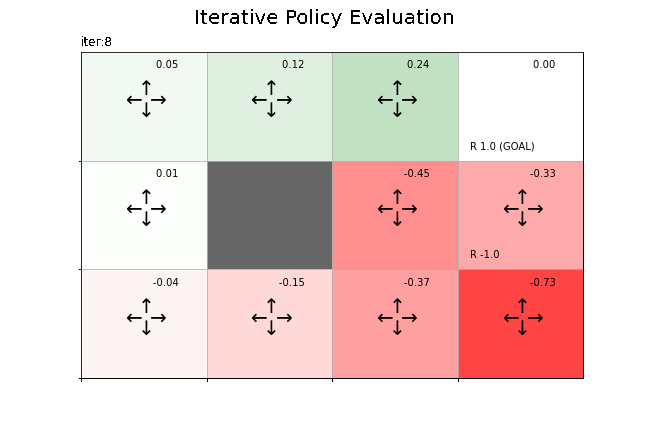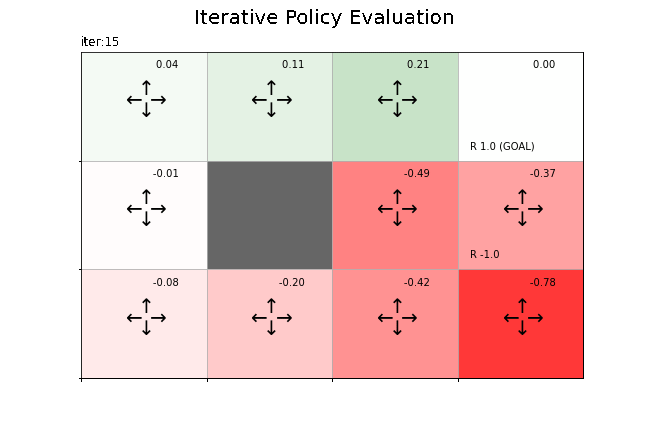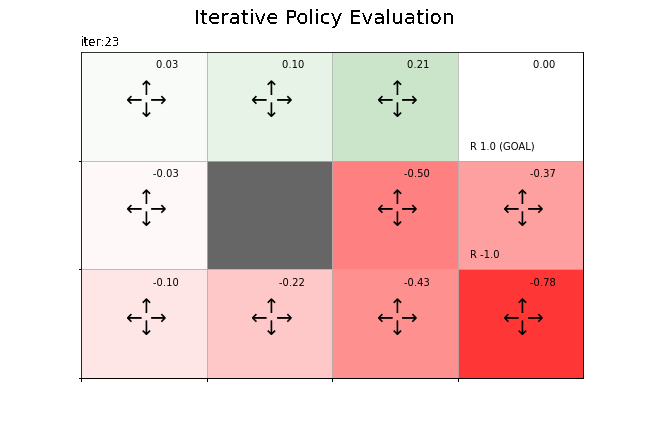
状態価値関数の更新値の推移をグラフで確認します。
・作図コード(クリックで展開)
# 更新回数を取得 max_iter = len(trace_V) # 状態数を取得 state_size = env.reward_map.size # 作図用の配列を作成 trace_V_arr = np.zeros((max_iter, state_size)) for i in range(max_iter): # i回目の更新値を抽出 V = trace_V[i] # 配列に格納 trace_V_arr[i] = list(V.values()) # 状態価値関数の推移を作図 plt.figure(figsize=(8, 6)) for s in range(env.reward_map.size): plt.plot(np.arange(max_iter), trace_V_arr[:, s]) plt.xlabel('iteration') plt.ylabel('state-value') plt.suptitle('Iterative Policy Evaluation', fontsize=20) plt.title('$\gamma='+str(gamma)+'$', loc='left') plt.grid() plt.show()
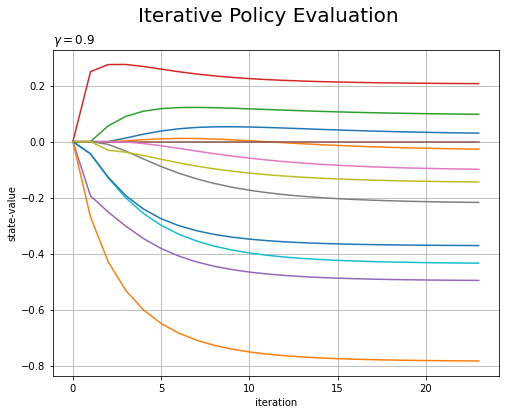
アニメーションでは、状態価値を色の濃淡で表しました。こちらは、y軸で表しています。
・実装
処理の確認ができたので、反復方策評価アルゴリズムを関数として実装します。policy_eval関数の定義については、eval_onestep関数のときと同じページを参照してください。
実装した関数を試してみましょう。
# グリッドワールドのインスタンスを作成 env = GridWorld() # 全ての確率論的方策を指定 pi = defaultdict(lambda: {0: 0.25, 1:0.25, 2: 0.25, 3: 0.25}) # 全ての状態価値関数を初期化 V = defaultdict(lambda: 0) # 割引率を指定 gamma = 0.9 # 閾値を指定 threshold =0.001 # 状態価値関数を推定:式(4.3)の繰り返し V = policy_eval(pi, V, env, gamma, threshold) # 状態価値関数のヒートマップを作図 env.render_v(v=V, policy=pi)
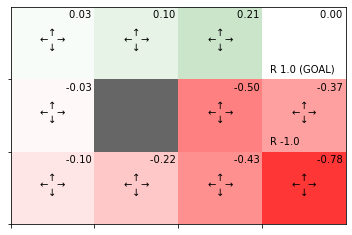
処理の確認時と同じ結果が得られました。
この節では、反復方策評価アルゴリズムを実装しました。これにより、ある方策における状態価値関数を得られます(方策を評価できます)。次節では、方策反復法により最適方策を得る(方策を改善する)ことを考えます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
アルゴリズムの名前がごっちゃになる。状態価値関数を更新するのになんで〝方策〟〝評価〟なんだと混乱したけど、ある〝方策の〟ときの状態〝価値を求める〟のは、方策を評価していることになるのか。なるほど。
それと可視化の話で、グラフをアニメーションにするとやった感と分かった感が出てとてもいい。これからも隙あらば捻じ込みたい。
先日公開された新MVをどうぞ♫
来月のデビューが待ち遠しいです。
【次節の内容】