はじめに
『ゼロから作るDeep Learning 4 ――強化学習編』の独学時のまとめノートです。初学者の補助となるようにゼロつくシリーズの4巻の内容に解説を加えていきます。本と一緒に読んでください。
この記事は、1.5.1節と1.5.2節の内容です。非定常問題に対応したエージェントを実装します。
【前節の内容】
【他の記事一覧】
【この記事の内容】
1.5.1 非定常問題のエージェントの実装
非定常問題のエージェント(プレーヤー)の機能を持つAlphaAgentクラスの処理を確認します。
利用するライブラリを読み込みます。
# 利用するライブラリ import numpy as np import matplotlib.pyplot as plt
・処理の確認
AlphaAgentクラスの内部で行われる処理を確認します。基本的な処理はAgentと同様です。「1.4.2:エージェントの実装【ゼロつく4のノート】 - からっぽのしょこ」も参照してください。
非定常問題では、指数移動平均で価値の推定値$Q_n$を計算します。
ここで、$\alpha$は減衰率で0から1の値を設定します。
この式は次のように変形できます。詳しい式変形は本を参照してください。
ちなみに、$x^0 = 1$なので(0乗は1なので)
に置き換えると、次の式に整理できます。
プログラム上の計算は式(1.6)で行います。
指数移動平均における重み$\alpha (1 - \alpha)^k$と過去のインデックス$k$との関係をグラフで確認します。
# 減衰率を指定 alpha = 0.1 # 試行回数を指定 n = 100 # x軸の値を作成 k = np.arange(n) # 指数移動平均の重みのグラフを作成 plt.figure(figsize=(8, 6)) plt.plot(k, alpha * (1 - alpha)**k) # 過去試行と重みの関係 plt.xlabel('k') plt.ylabel('y') plt.title('$\\alpha=' + str(alpha) +'$', loc='left') plt.suptitle('$y = \\alpha (1 - \\alpha)^k$', fontsize=20) plt.grid() plt.show()
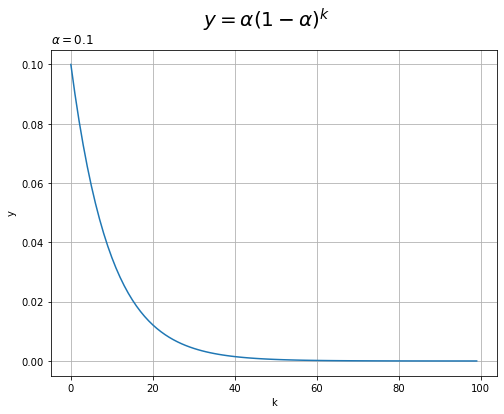
$k$が大きいほど過去の報酬の重みを表します。過去の報酬の重みほど値が小さくなり、ほとんど0になるのが分かります。つまり、過去の報酬の影響をほとんど受けなくなります。
この図は、x軸が左なほど新しい報酬($n$が大きく)、右なほど古い報酬($n$が小さい)です。x軸の値を$n - k$にすると、右に行くほど新しい報酬の重みになります(図1-19を再現できます)。
# 減衰率を指定 alpha = 0.1 # 試行回数を指定 n = 50 # 過去のインデックスを作成 k = np.arange(n) # 指数移動平均の重みのグラフを作成 plt.figure(figsize=(8, 6)) plt.bar(n - k, alpha * (1 - alpha)**k) # 過去試行と重みの関係 plt.xlabel('$R_n$', fontsize=15) plt.ylabel('Reward weight') plt.title('$\\alpha=' + str(alpha) +'$', loc='left') plt.suptitle('$y = \\alpha (1 - \\alpha)^k$', fontsize=20) plt.grid() plt.show()
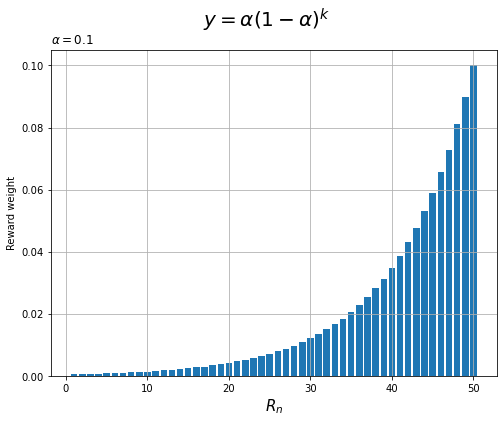
続いて、減衰率が異なるグラフを比較します。
# 減衰率を指定 alpha_list = [0.05, 0.1, 0.2, 0.4] # 試行回数を指定 n = 100 # x軸の値を作成 k = np.arange(n) # 指数移動平均の重みのグラフを作成 plt.figure(figsize=(8, 6)) for alpha in alpha_list: plt.plot(k, alpha * (1 - alpha)**k, alpha=0.9, label='$\\alpha='+str(alpha)+'$') # 試行回数と重みの関係 plt.xlabel('k') plt.ylabel('y') plt.suptitle('$y = \\alpha (1 - \\alpha)^k$', fontsize=20) plt.grid() plt.legend() plt.show()
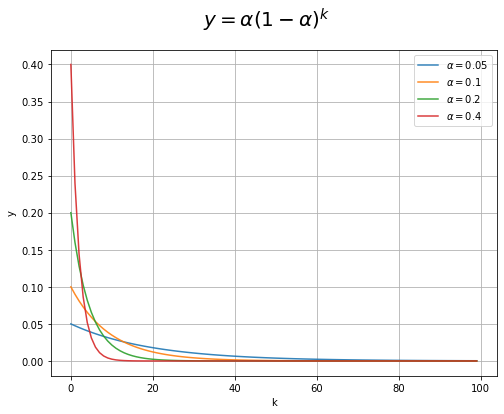
減衰率$\alpha$が大きいほど、新しい報酬に対する重みが大きく、古い報酬に対する重みが小さくなるのが分かります。つまり、減衰率が大きいほど新しい報酬を重視し、減衰率が小さいほど過去の報酬も利用して価値の推定値を計算します。
以上が、AlphaAgentクラスで行う計算です。
・実装
AlphaAgentクラスの実装は、次のページを参照してください。
実装したクラスを試してみます。
マシンの数とランダムに行動する確率を指定して、エージェントクラスのインスタンスを作成します。
# マシンの数を指定 action_size = 5 # ランダムにマシンを選ぶ確率を指定 epsilon = 0.5 # 減衰率を指定 alpha = 0.1 # インスタンスを作成 agent = AlphaAgent(epsilon, alpha, action_size) print(agent.Qs) print(agent.ns)
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
各マシンの価値の推定値Qsとプレイ回数nsの初期値は0です。
プレイするマシンをε-greedy法により決定して、価値の推定値を更新します。
# 試行回数を指定 N = 5 # N回試行 for n in range(N): # ε-greedy法によりマシンを決定 action = agent.get_action() # 確認用の報酬を設定 reward = 1 # action番目のマシンの推定価値(指数移動平均)を更新 agent.update(action, reward) print('n =', agent.ns, ' action =', action) print('Q =', np.round(agent.Qs, 3))
n = [1. 0. 0. 0. 0.] action = 0
Q = [0.1 0. 0. 0. 0. ]
n = [2. 0. 0. 0. 0.] action = 0
Q = [0.19 0. 0. 0. 0. ]
n = [3. 0. 0. 0. 0.] action = 0
Q = [0.271 0. 0. 0. 0. ]
n = [4. 0. 0. 0. 0.] action = 0
Q = [0.344 0. 0. 0. 0. ]
n = [4. 0. 1. 0. 0.] action = 2
Q = [0.344 0. 0.1 0. 0. ]
指数移動平均により価値の推定値を計算して、ε-greedy法により行動できました。
以上で、エージェントの機能を持つクラスを実装できました。次節では、実装したクラスを使って非定常バンディット問題を解きます。
参考文献
- 斎藤康毅『ゼロから作るDeep Learning 4 ――強化学習編』オライリー・ジャパン,2022年.
- サポートページ:GitHub - oreilly-japan/deep-learning-from-scratch-4
おわりに
1章は次がラストです。
【次節の内容】