はじめに
『パターン認識と機械学習』の独学時のまとめです。一連の記事は「数式の行間埋め」または「R・Pythonでのスクラッチ実装」からアルゴリズムの理解を補助することを目的としています。本とあわせて読んでください。
この記事は、4.3.2項と4.3.3項の内容です。ニュートン法によるロジスティック回帰の最尤推定をPythonで実装します。
【数式読解編】
【前節の内容】
【他の節一覧】
【この節の内容】
4.3.2 ロジスティック回帰の実装:入力が2次元の場合
ニュートン-ラフソン法によるロジスティック回帰の最尤推定を実装します。
利用するライブラリを読み込みます。
# 4.3.2-3項で利用するライブラリ import numpy as np from scipy.stats import multivariate_normal # 多次元ガウス分布 import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
推定過程をアニメーション(gif画像)で可視化するのにMatplotlibライブラリのanimationモジュールを利用します。不要であれば省略してください。
・利用する関数の作成
推定に利用する関数を作成します。基底関数については「【Python】3.1.0:基底関数の作図【PRMLのノート】 - からっぽのしょこ」を、計画行列については「【Python】3.1.1:線形基底関数モデルの実装【PRMLのノート】 - からっぽのしょこ」を参照してください。
ロジスティックシグモイド関数を定義します。
# ロジスティックシグモイド関数を作成 def sigmoid(x): return 1.0 / (1.0 + np.exp(-x))
ロジスティックシグモイド関数は、次の式で定義されます。
非線形変換を行う基底関数$\phi_j(\mathbf{x})$を用いた計画行列
の計算を行う関数を作成します。この例では、0番目の基底関数について$\phi_0(\mathbf{x}_1) = 1$とします。
多項式基底関数の計画行列を定義します。
# 2次元多項式基底関数を作成 def phi_polynomial2d(x_d, j): # データごとに総和を計算 return np.sum(x_d**j, axis=1) # 2次元多項式基底関数の計画行列を作成 def Phi_polynomial2d(x_nd, M, _x_nd=None): # 変数を初期化 phi_x_nm = np.ones((len(x_nd), M)) # 2次元多項式基底関数による変換 for m in range(1, M): phi_x_nm[:, m] = phi_polynomial2d(x_nd, m) return phi_x_nm
ガウス基底関数の計画行列を定義します。
# 2次元ガウス基底関数を作成 def phi_gauss2d(x_d, mu_d, s_d): # m番目のパラメータを使って二次形式の計算 a_d = -0.5 * (x_d - mu_d)**2 / s_d**2 # データごとに総和を計算 a = np.sum(a_d, axis=1) # 指数をとる return np.exp(a) # 2次元ガウス基底関数の計画行列を作成:(対角線に標準化) def Phi_gauss2d(x_nd, M, _x_nd=None): # パラメータ設定用の入力値を設定 if _x_nd is None: _x_nd = x_nd.copy() # M-1個のパラメータを作成 s_d = np.std(_x_nd, axis=0) # 標準偏差で固定 if M == 2: # 入力値の平均 mu_md = np.array([[np.mean(_x_nd[:, 0]), np.mean(_x_nd[:, 1])]]) elif M == 3: # 調整幅を指定 sgm_d = s_d * 2.0 # 入力値の平均 mu_md = np.array( [[np.mean(_x_nd[:, 0]) - sgm_d[0], np.mean(_x_nd[:, 0]) - sgm_d[1]], [np.mean(_x_nd[:, 0]) + sgm_d[0], np.mean(_x_nd[:, 0]) + sgm_d[1]]] ) elif M > 3: # 調整幅を指定 sgm_d = s_d * 0.5 # 最小値から最大値を等分 mu_md = np.stack([ np.linspace(np.min(_x_nd[:, 0]) + sgm_d[0], np.max(_x_nd[:, 0] - sgm_d[1]), num=M-1), np.linspace(np.min(_x_nd[:, 1]) + sgm_d[0], np.max(_x_nd[:, 1] - sgm_d[1]), num=M-1) ], axis=1) # 変数を初期化 phi_x_nm = np.ones((len(x_nd), M)) # 2次元ガウス基底関数による変換 for m in range(1, M): phi_x_nm[:, m] = phi_gauss2d(x_nd, mu_md[m-1], s_d) return phi_x_nm
シグモイド基底関数の計画行列を定義します。
# 2次元シグモイド基底関数を作成 def phi_sigmoid2d(x_d, mu_d, s_d): # m番目のパラメータにより入力値を調整 a_d = (x_d - mu_d) / s_d # ロジスティックシグモイド関数の計算 y_d = sigmoid(a_d) # データごとに総和を計算 return np.sum(y_d, axis=1) / len(s_d) # 2次元シグモイド基底関数の計画行列を作成:(対角線に標準化) def Phi_sigmoid2d(x_nd, M, _x_nd=None): # パラメータ設定用の入力値を設定 if _x_nd is None: _x_nd = x_nd.copy() # M-1個のパラメータを作成 s_d = np.std(_x_nd, axis=0) # 標準偏差で固定 if M == 2: # 入力値の平均 mu_md = np.array([[np.mean(_x_nd[:, 0]), np.mean(_x_nd[:, 1])]]) elif M == 3: # 調整幅を指定 sgm_d = s_d * 2.0 # 入力値の平均 mu_md = np.array( [[np.mean(_x_nd[:, 0]) - sgm_d[0], np.mean(_x_nd[:, 0]) - sgm_d[1]], [np.mean(_x_nd[:, 0]) + sgm_d[0], np.mean(_x_nd[:, 0]) + sgm_d[1]]] ) elif M > 3: # 調整幅を指定 sgm_d = s_d * 0.5 # 最小値から最大値を等分 mu_md = np.stack([ np.linspace(np.min(_x_nd[:, 0]) + sgm_d[0], np.max(_x_nd[:, 0] - sgm_d[1]), num=M-1), np.linspace(np.min(_x_nd[:, 1]) + sgm_d[0], np.max(_x_nd[:, 1] - sgm_d[1]), num=M-1) ], axis=1) # 変数を初期化 phi_x_nm = np.ones((len(x_nd), M)) # 2次元シグモイド基底関数による変換 for m in range(1, M): phi_x_nm[:, m] = phi_sigmoid2d(x_nd, mu_md[m-1], s_d) return phi_x_nm
(2次元の基底関数を調べても見付けられなかったので、雰囲気で実装しました。正しい情報を教えて下さい。)
・データの生成
推定に利用するデータを人工的に作成します。
データ生成に関するパラメータを指定します。ここでは、2値(2クラス)分類なので$K = 2$で、入力が2次元の場合なので$D = 2$です。
# クラス割り当て確率を指定:(クラス0, クラス1) pi_k = np.array([0.4, 0.6]) # データ生成の平均を指定:(クラス0, クラス1) mu_kd = np.array([[-2.5, 1.5], [0.0, 2.0]]) # データ生成の分散共分散行列を指定:(クラス0, クラス1) sigma2_kdd = np.array( [[[0.25, 0.2], [0.2, 0.25]], [[0.25, -0.2], [-0.2, 0.25]]] )
(次にやる多クラス分類に繋がるように仰々しく記号を割り当てますが、データの生成にのみ使い推定には使いません。)
クラス0($t_n = 0$)となる確率$\pi_0$と、クラス1($t_n = 1$)となる確率$\pi_1$をまとめて$K$次元ベクトル$\boldsymbol{\pi} = (\pi_0, \pi_1)^{\top}$で表します。$\pi_0 + \pi_1 = 1$となるように1次元配列pi_kに値を指定します。
クラス0の平均を$D$次元ベクトル$\boldsymbol{\mu}_0 = (\mu_{0,1}, \mu_{0,2})^{\top}$で表します。クラス1の平均は$\boldsymbol{\mu}_1 = (\mu_{1,1}, \mu_{1,2})^{\top}$です。$\boldsymbol{\mu}_0, \boldsymbol{\mu}_1$をまとめて、2次元配列mu_kdとします。
同様に、クラス$k$の分散共分散行列を$D \times D$の行列$\boldsymbol{\Sigma}_k = (\sigma_{k,1,1}^2, \cdots, \sigma_{k,2,2}^2)$で表します。$\boldsymbol{\Sigma}_0, \boldsymbol{\Sigma}_1$をまとめて、3次元配列sigma2_kddとします。
指定したパラメータに従って観測データを作成します。
# データ数を指定 N = 150 # 真のクラスを生成 t_n = np.random.binomial(n=1, p=pi_k[1], size=N) # 真のクラスに従いデータを生成 x_nd = np.array( [np.random.multivariate_normal(mean=mu_kd[k], cov=sigma2_kdd[k], size=1).flatten() for k in t_n] ) # 確認 print(t_n[:5]) print(x_nd[:5])
[0 1 1 0 1]
[[-2.3781227 1.54672678]
[-0.77673486 2.25898085]
[ 0.3465757 1.58252552]
[-3.12770833 1.22538281]
[ 0.07619303 1.658932 ]]
データ数$N$を指定して、観測データ(目標値$\mathbf{t} = \{t_1, \cdots, t_N\}$、入力値$\mathbf{X} = \{\mathbf{x}_1, \cdots, \mathbf{x}_N\}$)を作成します。
$t_n$は$n$番目のデータのクラスを表し、$t_n = 0$であればクラス0、$t_n = 1$であればクラス1とします。
対応する入力($n$番目の入力)は$D$次元ベクトル$\mathbf{x}_n = (x_{n,1}, x_{n,2})^{\top}$です。
$\mathbf{t}$はベルヌーイ分布に従い生成します。ベルヌーイ分布に従う乱数は、二項分布の乱数生成関数np.random.binomial()の試行回数の引数nに1を指定することで生成できます。確率の引数pにクラス1となる確率pi_k[1]、データ数(サンプルサイズ)の引数sizeにNを指定します。
$\mathbf{X}$は2次元ガウス分布に従い生成します。多次元ガウス分布に従う乱数は、np.random.multivariate_normal()で生成できます。meanは平均、covは分散共分散行列の引数です。データごとに割り当てられたクラスに応じてパラメータを指定する必要があります。
クラスに対応したパラメータの値は、次のようにして取り出しています。
# パラメータの取得 print(t_n[:5]) print(mu_kd[t_n[:5]])
[0 1 1 0 1]
[[-2.5 1.5]
[ 0. 2. ]
[ 0. 2. ]
[-2.5 1.5]
[ 0. 2. ]]
t_nには各データのクラスが保存されています。
クラス0のパラメータはmu_kd[0], sigma2_kdd[0]、クラス1のパラメータはmu_kd[1], sigma_kdd[1]なので、t_nの値がインデックスに対応します。
作図用と計算用の$\mathbf{x}$の値を作成します。
# 作図用のxの値を作成 x1 = np.linspace(np.min(x_nd[:, 0]) - 0.5, np.max(x_nd[:, 0]) + 0.5, num=100) x2 = np.linspace(np.min(x_nd[:, 1]) - 0.5, np.max(x_nd[:, 1]) + 0.5, num=100) # 作図用のxの点を作成 X1, X2 = np.meshgrid(x1, x2) # 計算用のxの点を作成 x_points = np.stack([X1.flatten(), X2.flatten()], axis=1) x_dims = X1.shape print(x_points.shape) print(x_dims)
(10000, 2)
(100, 100)
次元ごとに最小値から最大値までの値x1, x2を作成します。
x1, x2を格子状の点に変換して、作図用の値X1, X2とします。
X1, X2をそれぞれ1列に並べて、計算用の値x_pointsとします。
データの確認用に、入力$\mathbf{x}$の分布を計算します。
# 混合ガウス分布を計算 model_density = 0.0 for k in range(len(pi_k)): # クラスkの確率密度を加算 model_density += pi_k[k] * multivariate_normal.pdf(x=x_points, mean=mu_kd[k], cov=sigma2_kdd[k])
混合ガウス分布の確率密度は、次の式で計算します。
クラスごとの分布$\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}_k, \boldsymbol{\sigma}_k)$を、各クラスとなる確率$\pi_k$で加重平均を求めています。
観測データの散布図を混合分布に重ねて描画します。
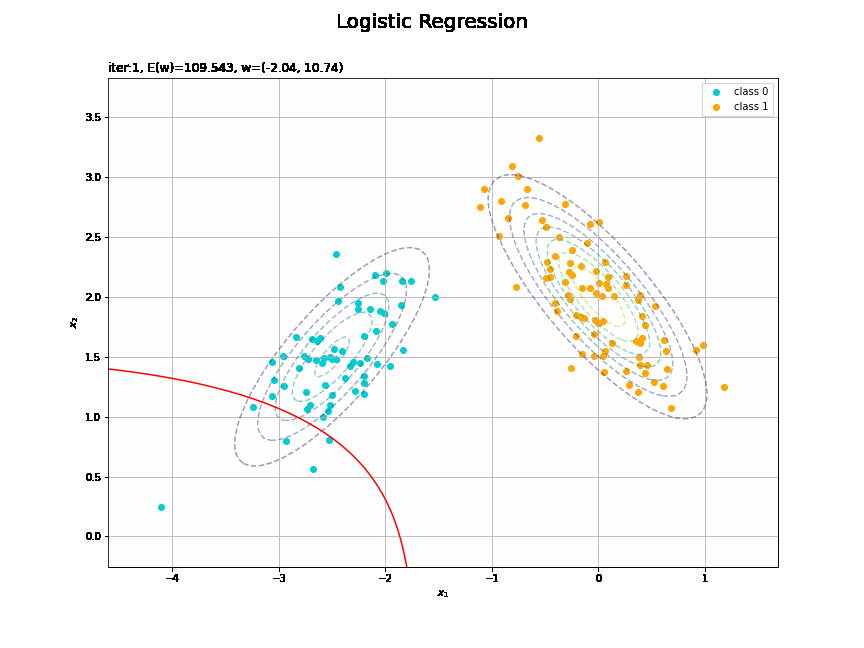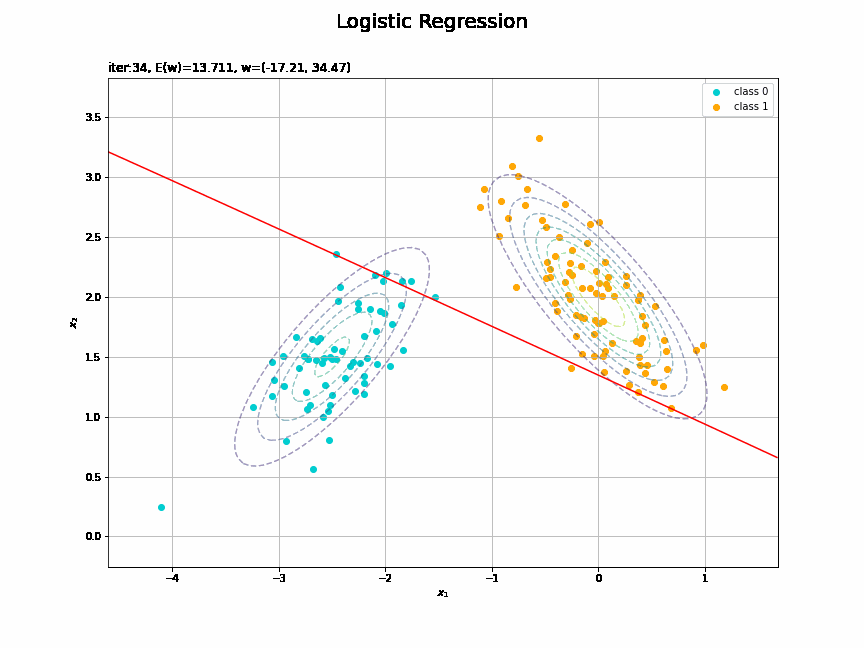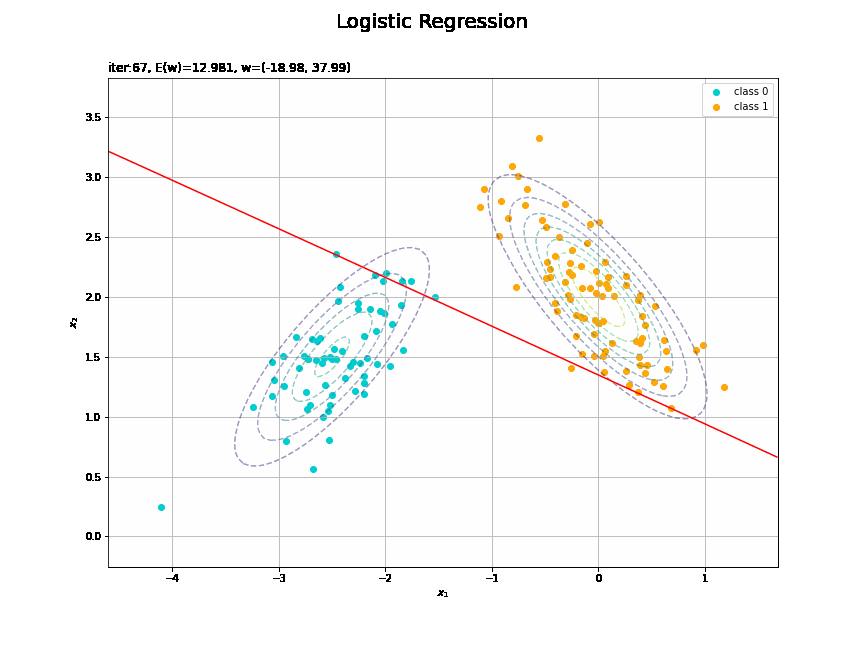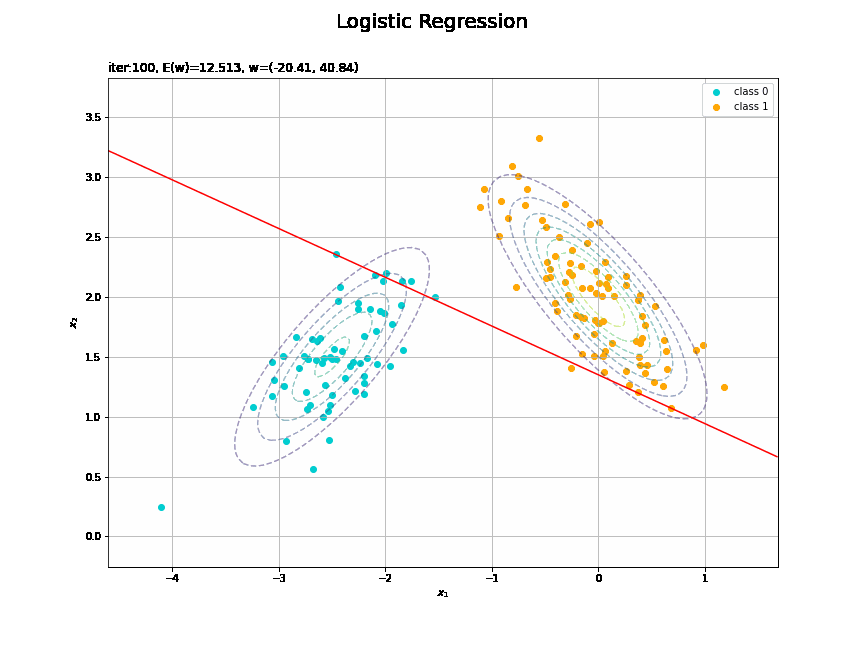
# 観測モデルを作図 plt.figure(figsize=(12, 9)) plt.scatter(x=x_nd[t_n == 0, 0], y=x_nd[t_n == 0, 1], color='darkturquoise', label='class 0') # クラス0の観測データ plt.scatter(x=x_nd[t_n == 1, 0], y=x_nd[t_n == 1, 1], color='orange', label='class 1') # クラス1の観測データ plt.contour(X1, X2, model_density.reshape(x_dims)) # データ生成分布 plt.xlabel('$x_1$') plt.ylabel('$x_2$') plt.suptitle('Observation Data', fontsize=20) plt.title('$\pi=(' + ', '.join([str(pi) for pi in pi_k]) + ')' + ', N_0=' + str(np.sum(t_n == 0)) + ', N_1=' + str(np.sum(t_n == 1)) + '$', loc='left') plt.colorbar(label='density') plt.legend() plt.grid() plt.show()
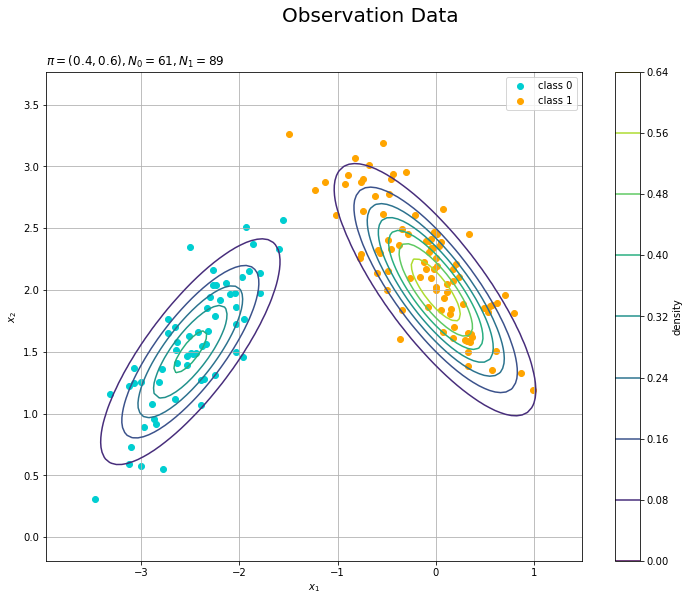
(ロジスティック回帰用のデータがこんな感じでいいのかはよく分かっていません。何か変なら教えてください。)
・ニュートン-ラフソン法による最尤推定
ニュートン-ラフソン法によりロジスティック回帰のパラメータの最尤解を求めます。
・処理の解説
まずは、繰り返し行う個々の処理を解説します。次に、それらをまとめて推定を行います。
基底関数を設定して、計画行列の計算を行い入力値を変換します。
# 基底関数の数を指定 M = 2 # 基底関数を指定 phi = Phi_polynomial2d #phi = Phi_gauss2d #phi = Phi_sigmoid2d # 基底関数により入力値を変換 phi_x_nm = phi(x_nd, M) # 確認 print(phi_x_nm[:5])
[[ 1. -0.83139592]
[ 1. 1.48224598]
[ 1. 1.92910123]
[ 1. -1.90232552]
[ 1. 1.73512503]]
利用する基底関数の計画行列Phi_***()を関数phi()として複製します。
phi()を使って計算します。
以降の推定処理は、入力が1次元の場合と同じです。
変換した入力値の重み付き和を計算します。
# 重みパラメータを初期化 w_m = np.random.uniform(-10.0, 10.0, size=M) # 重み付き和を計算 a_n = np.dot(phi_x_nm, w_m.reshape(-1, 1)).flatten() # 確認 print(w_m) print(a_n[:5])
[5.24742526 3.88057504]
[ 2.02113099 10.99939203 12.73344732 -2.13469167 11.98070815]
変換した入力値とロジスティック回帰のパラメータ$\mathbf{w} = (w_0, w_1)^{\top}$の内積を計算します。
この例では、重みパラメータw_mの初期値を一様乱数で設定します。
重み付き和をロジスティックシグモイド関数で変換します。
# ロジスティックシグモイド関数による変換 y_n = sigmoid(a_n) # 確認 print(y_n[:5])
[0.88299791 0.99998329 0.99999705 0.10577042 0.99999374]
始めに作成したsigmoid()で計算します。
出力$\mathbf{y} = \{y_1, \cdots, y_N\}$の各項は、$0 < y_n < 1$の値をとり、対応する入力$x_n$のクラスが1である確率の推定値を表します。
重みパラメータを更新します。
# 中間変数を計算 r_nn = np.diag(y_n) z_n = np.dot(phi_x_nm, w_m.reshape(-1, 1)).flatten() z_n -= np.dot(np.linalg.inv(r_nn), (y_n - t_n).reshape(-1, 1)).flatten() w_term_mm = phi_x_nm.T.dot(r_nn).dot(phi_x_nm) w_term_m1 = phi_x_nm.T.dot(r_nn).dot(z_n.reshape(-1, 1)) # パラメータを更新 w_m = np.dot(np.linalg.inv(w_term_mm), w_term_m1).flatten() # 確認 print(w_m)
[4.49018675 4.22437502]
次の式でパラメータ$\mathbf{w}$を更新します。
以上が1回の試行で行う処理(計算)です。
・全体のコード
ニュートン-ラフソン法によりパラメータの最尤解を計算します。
多項式基底関数Phi_polynomial2d()・多項式基底関数Phi_gauss2d・シグモイド基底関数Phi_sigmoid2d()を関数phi()として複製して利用します。
# 試行回数を指定 max_iter = 100 # 基底関数の数を指定 M = 2 # 基底関数を指定 phi = Phi_polynomial2d #phi = Phi_gauss2d #phi = Phi_sigmoid2d # 基底関数により入力値を変換 phi_x_nm = phi(x_nd, M) # 重みパラメータを初期化 w_m = np.random.uniform(-10.0, 10.0, size=M) # 推移の記録用の配列を作成 trace_w_arr = np.zeros((max_iter, M)) # 重みパラメータ trace_E_list = np.zeros(max_iter) # 負の対数尤度 # ニュートン-ラフソン法による推定 for i in range(max_iter): # 重み付き和を計算 a_n = np.dot(phi_x_nm, w_m.reshape(-1, 1)).flatten() # ロジスティックシグモイド関数による変換 y_n = sigmoid(a_n) # 中間変数を計算 r_nn = np.diag(y_n) z_n = np.dot(phi_x_nm, w_m.reshape(-1, 1)).flatten() z_n -= np.dot(np.linalg.inv(r_nn), (y_n - t_n).reshape(-1, 1)).flatten() w_term_mm = phi_x_nm.T.dot(r_nn).dot(phi_x_nm) w_term_m1 = phi_x_nm.T.dot(r_nn).dot(z_n.reshape(-1, 1)) # パラメータを更新 w_m = np.dot(np.linalg.inv(w_term_mm), w_term_m1).flatten() # 負の対数尤度関数を計算 y_n = sigmoid(np.dot(phi_x_nm, w_m.reshape(-1, 1)).flatten()) #E_val = -np.sum(t_n * np.log(y_n) + (1.0 - t_n) * np.log(1.0 - y_n)) E_val = -np.sum(np.log(y_n**t_n) + np.log((1.0 - y_n)**(1.0 - t_n))) # 値を記録 trace_w_arr[i] = w_m.copy() trace_E_list[i] = E_val # 途中経過を表示 #print(i + 1)
試行回数max_iterを指定して、重みパラメータw_mの値を繰り返し更新します。
また、推移の確認用にパラメータをtrace_w_arrに、負の対数尤度(交差エントロピー誤差)をtrace_E_listに格納していきます。
交差エントロピー誤差は、次の式で計算します。
計算に利用するy_nは、更新したパラメータw_mを使って再計算しています(y_nを2回計算しており明らかに非効率ですが、推定の流れの分かりやすさを優先しました)。誤差は、学習の推移を確認するためのもので、推定には必要ありません。
重みパラメータの初期値によっては(?)、z_nにおける逆行列の計算、E_valにおける対数の計算でエラーになることがあります。
・推定結果の可視化
推定結果と収束過程をグラフで確認します。
推定したパラメータを使って回帰曲面を計算します。
# 回帰曲面を計算 #phi_x_vals = phi(x_points, M) # 多項式基底関数の場合 phi_x_vals = phi(x_points, M, x_nd) # ガウス・シグモイド基底関数の場合 a_vals = np.dot(phi_x_vals, w_m).flatten() y_vals = sigmoid(a_vals) # 確認 print(a_vals[:5]) print(y_vals[:5])
[-235.89068128 -233.25002079 -230.6093603 -227.9686998 -225.32803931]
[3.58078945e-103 5.02114851e-102 7.04088658e-101 9.87305666e-100
1.38444565e-098]
$x_1$軸と$x_2$軸の値x_pointsの各要素に対して次の計算を行い、各点ごとにクラス1となる確率(z軸の値)を求めます。
ただし、phi_x_nmの全ての要素を一度に処理するために$\boldsymbol{\Phi} \mathbf{w}_{\mathrm{Logistic}}$で計算します。
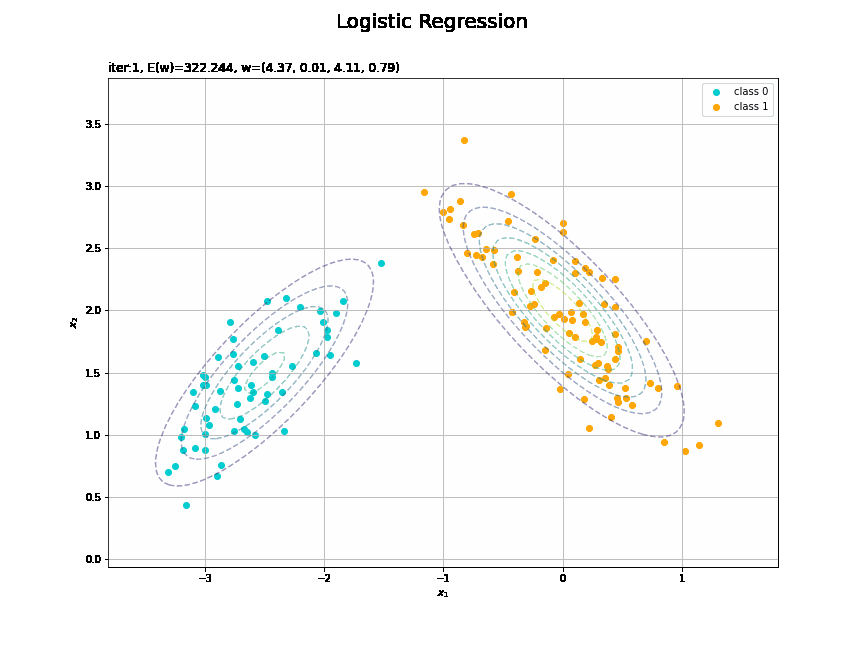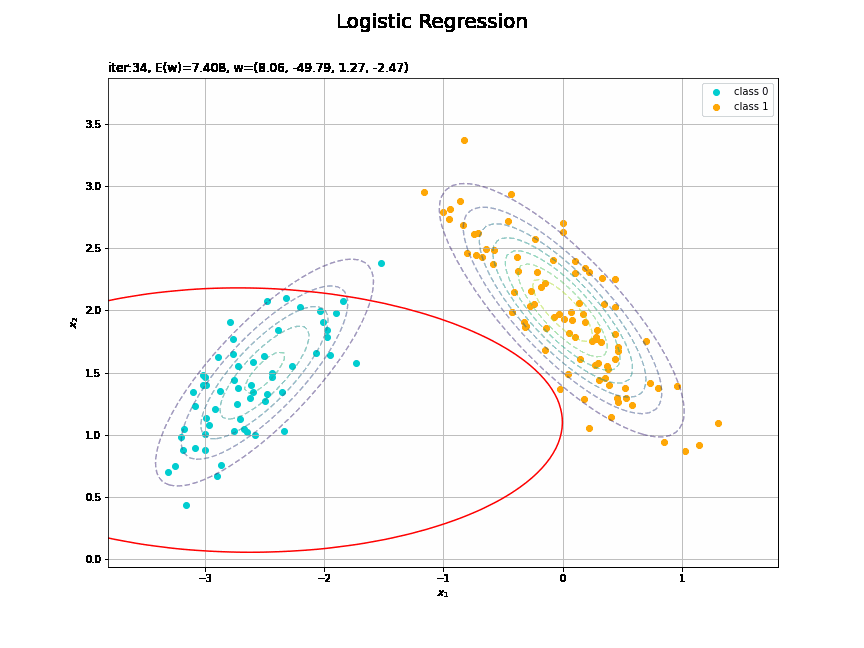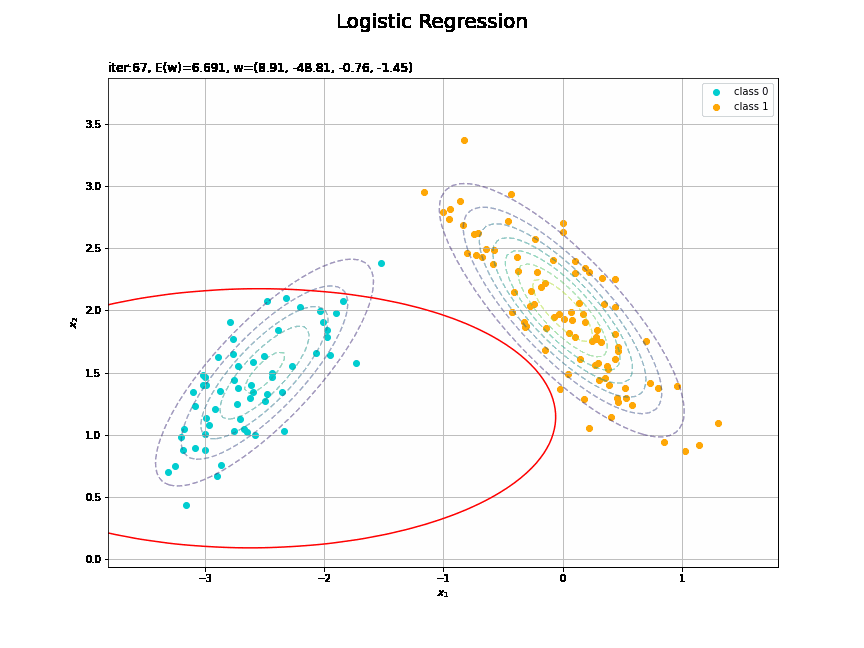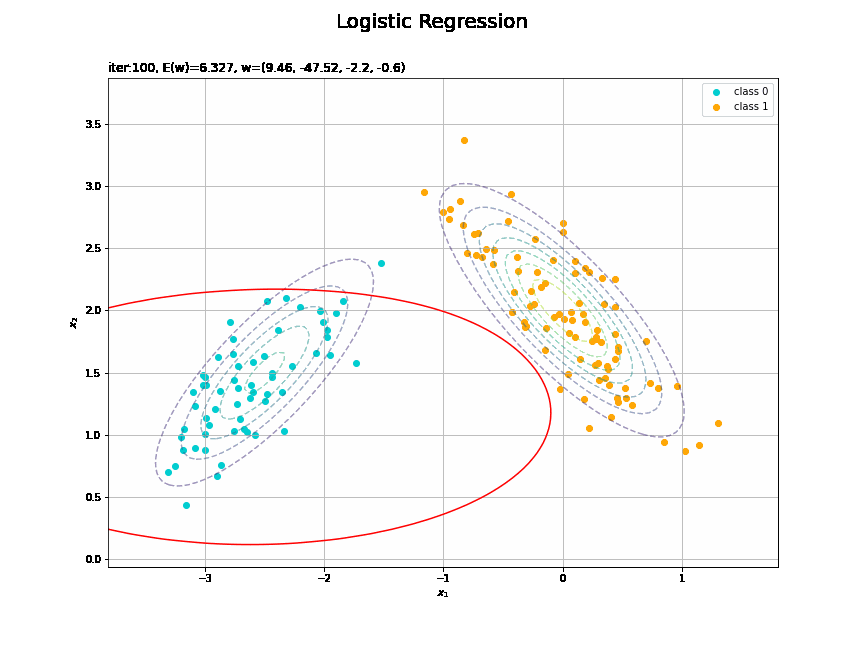
決定境界を作図します。
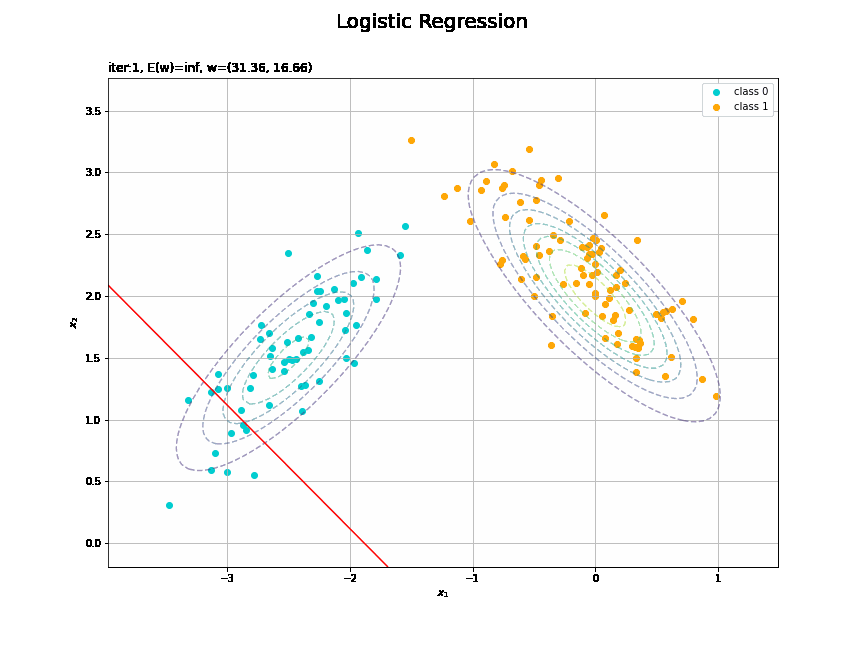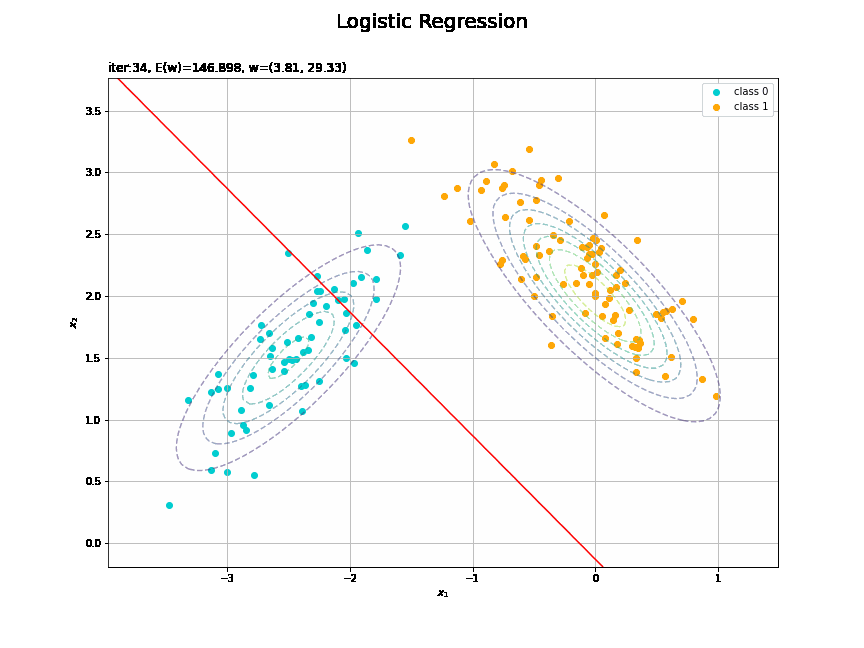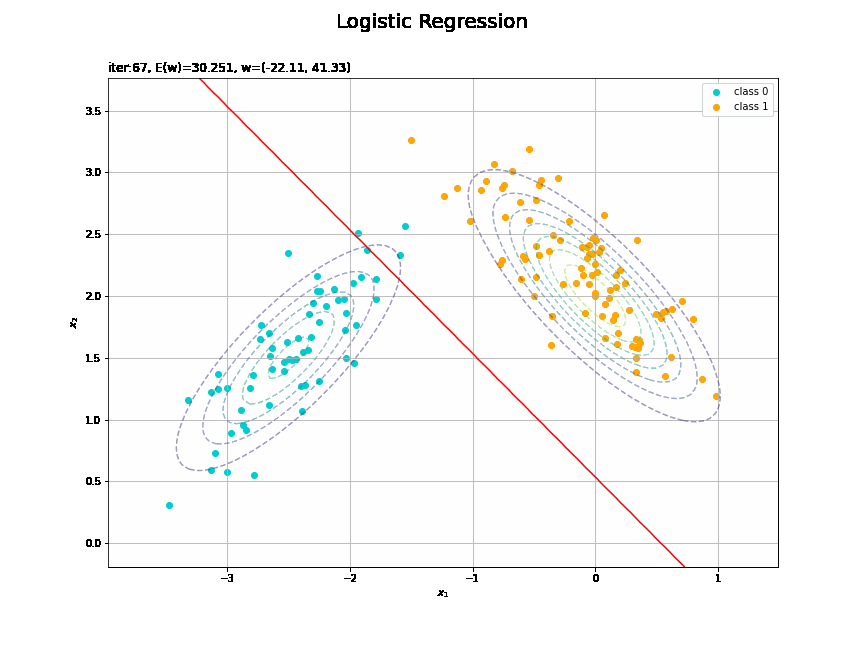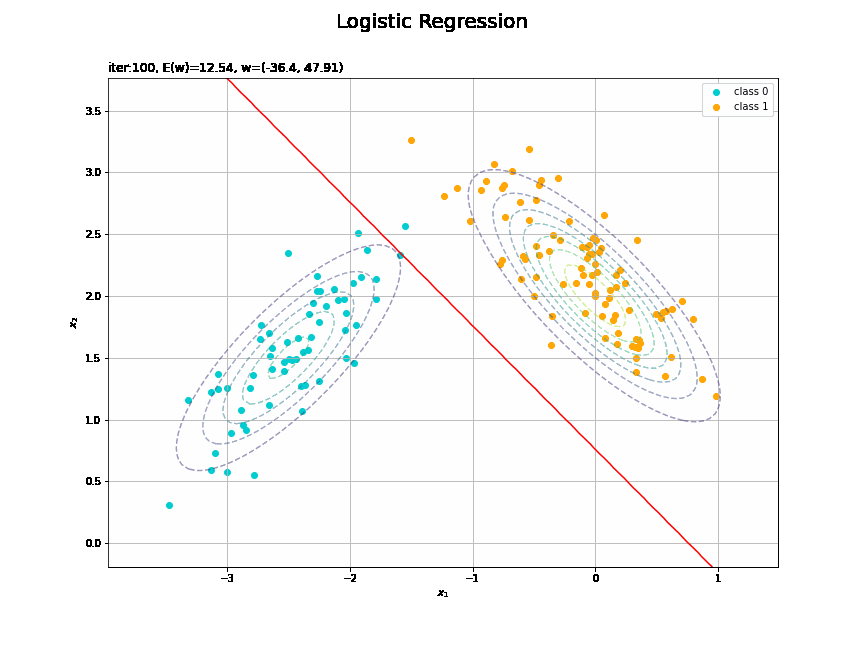
# 決定境界を作図 plt.figure(figsize=(12, 9)) plt.scatter(x=x_nd[t_n == 0, 0], y=x_nd[t_n == 0, 1], color='darkturquoise', label='class 0') # クラス0の観測データ plt.scatter(x=x_nd[t_n == 1, 0], y=x_nd[t_n == 1, 1], color='orange', label='class 1') # クラス1の観測データ plt.contour(X1, X2, model_density.reshape(x_dims), alpha=0.5, linestyles='--') # データ生成分布 plt.contour(X1, X2, y_vals.reshape(x_dims), colors='red', levels=[0.0, 0.5, 1.0]) # 決定境界 plt.xlabel('$x_1$') plt.ylabel('$x_2$') plt.suptitle('Logistic Regression', fontsize=20) plt.title('iter:' + str(max_iter) + ', N=' + str(N) + ', E(w)=' + str(np.round(E_val, 3)) + ', w=(' + ', '.join([str(w) for w in np.round(w_m, 2)]) + ')', loc='left') plt.colorbar(label='t') plt.legend() plt.grid() plt.show()
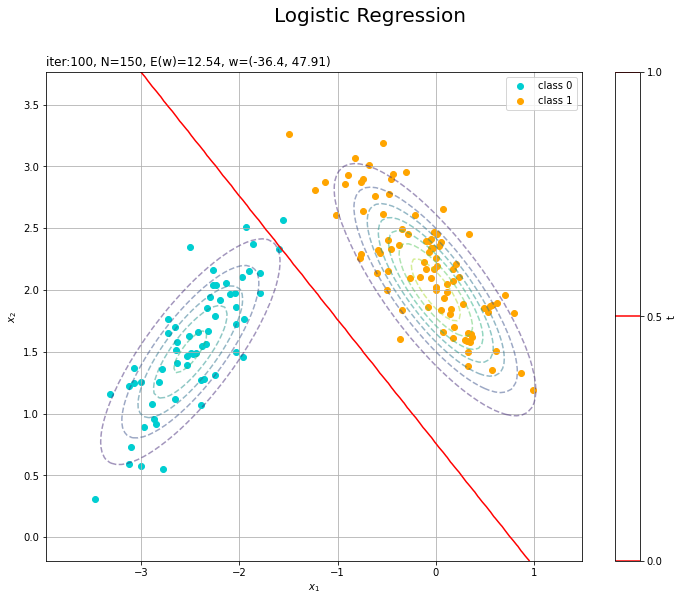
未知の入力$\mathbf{x}_{*}$に対して、$y_{*} > 0.5$であればクラス1($t_{*} = 1$)、$y_{*} < 0.5$であればクラス0($t_{*} = 0$)に分類します。そこで、クラスの境界線となる$y = 0.5$で決定境界(赤色の曲線)を引きます。
回帰曲面を作図します。
# 回帰曲面を作図 fig = plt.figure(figsize=(12, 9)) ax = fig.add_subplot(projection='3d') # 3D用の設定 ax.scatter(x_nd[t_n == 0, 0], x_nd[t_n == 0, 1], np.repeat(0, np.sum(t_n == 0)), c='darkturquoise', label='class 0') # クラス0の観測データ ax.scatter(x_nd[t_n == 1, 0], x_nd[t_n == 1, 1], np.repeat(1, np.sum(t_n == 1)), c='orange', label='class 1') # クラス1の観測データ ax.scatter(x_nd[t_n == 0, 0], x_nd[t_n == 0, 1], np.repeat(0.0, np.sum(t_n == 0)), facecolor='none', edgecolors='darkturquoise', linestyles='--') # クラス0の観測データ:(底面) ax.scatter(x_nd[t_n == 1, 0], x_nd[t_n == 1, 1], np.repeat(0.0, np.sum(t_n == 1)), facecolor='none', edgecolors='orange', linestyles='--') # クラス1の観測データ:(底面) plt.contour(X1, X2, model_density.reshape(x_dims), alpha=0.5, linestyles=':', offset=0.0) # データ生成分布:(底面) ax.plot_surface(X1, X2, y_vals.reshape(x_dims), cmap='jet', alpha=0.5) # 回帰曲面 surf = ax.contour(X1, X2, y_vals.reshape(x_dims), colors='red', levels=[0.0, 0.5, 1.0], offset=0.5) # 決定境界 ax.contour(X1, X2, y_vals.reshape(x_dims), colors='red', alpha=0.5, linestyles='--', levels=[0.5], offset=0.0) # 決定境界:(底面) ax.set_xlabel('$x_1$') ax.set_ylabel('$x_2$') ax.set_zlabel('t') fig.suptitle('Logistic Regression', fontsize=20) ax.set_title('iter:' + str(max_iter) + ', N=' + str(N) + ', E(w)=' + str(np.round(E_val, 3)) + ', w=(' + ', '.join([str(w) for w in np.round(w_m, 2)]) + ')', loc='left') fig.colorbar(surf, shrink=0.5, aspect=10, label='t') ax.legend() #ax.view_init(elev=0, azim=315) # 表示アングル:(横から) #ax.view_init(elev=90, azim=270) # 表示アングル:(上から) plt.show()
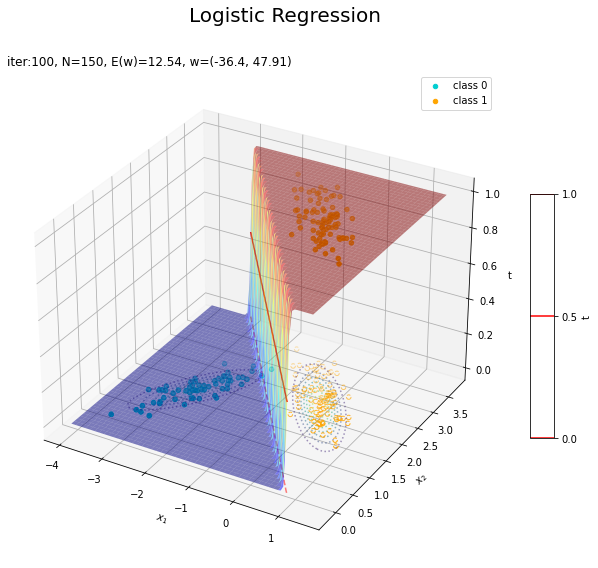
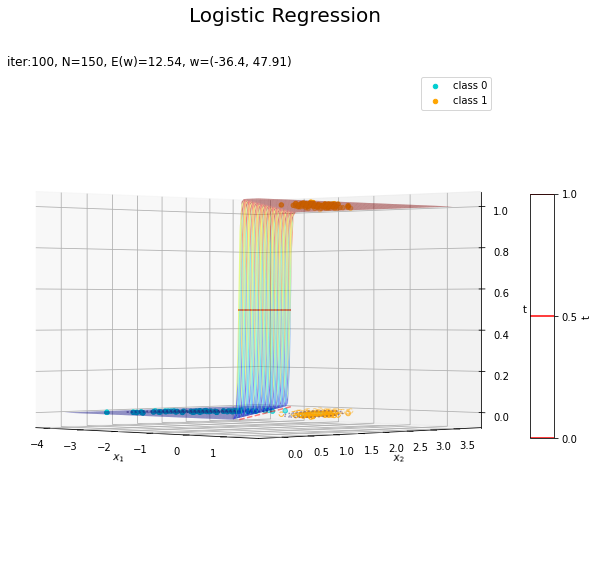
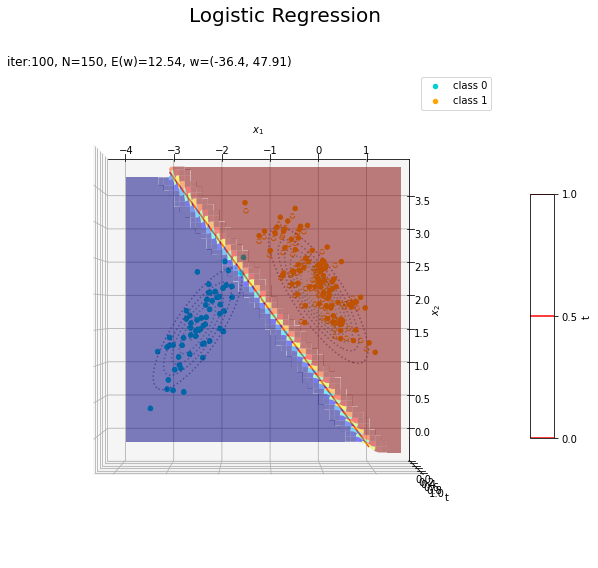
真上から見た図が、決定境界の図に対応します。
収束する過程をアニメーションで確認します。
・作図コード(クリックで展開)
決定境界の推移を作図します。
# 図を初期化 fig = plt.figure(figsize=(12, 9)) fig.suptitle('Logistic Regression', fontsize=20) # 作図処理を関数として定義 def update(i): # 前フレームのグラフを初期化 plt.cla() # i回目のパラメータを取得 w_m = trace_w_arr[i] E = trace_E_list[i] # 回帰曲面を計算 a_vals = np.dot(phi_x_vals, w_m).flatten() y_vals = sigmoid(a_vals) # 決定境界を作図 plt.scatter(x=x_nd[t_n == 0, 0], y=x_nd[t_n == 0, 1], c='darkturquoise', label='class 0') # クラス0の観測データ plt.scatter(x=x_nd[t_n == 1, 0], y=x_nd[t_n == 1, 1], c='orange', label='class 1') # クラス1の観測データ plt.contour(X1, X2, model_density.reshape(x_dims), alpha=0.5, linestyles='--') # データ生成分布 plt.contour(X1, X2, y_vals.reshape(x_dims), colors='red', levels=[0.0, 0.5, 1.0]) # 決定境界 plt.xlabel('$x_1$') plt.ylabel('$x_2$') plt.title('iter:' + str(i+1) + ', E(w)=' + str(np.round(E, 3)) + ', w=(' + ', '.join([str(w) for w in np.round(w_m, 2)]) + ')', loc='left') plt.legend() plt.grid() # gif画像を作成 anime_logistic = FuncAnimation(fig, update, frames=max_iter, interval=100) # gif画像を保存 anime_logistic.save('ch4_3_2_LogisticRegression2D_cnt.gif')
回帰曲面の推移を作図します。
# 図を初期化 fig = plt.figure(figsize=(12, 9)) ax = fig.add_subplot(projection='3d') # 3D用の設定 fig.suptitle('Logistic Regression', fontsize=20) # 作図処理を関数として定義 def update(i): # 前フレームのグラフを初期化 plt.cla() # i回目のパラメータを取得 w_m = trace_w_arr[i] E = trace_E_list[i] # 回帰曲面を計算 a_vals = np.dot(phi_x_vals, w_m).flatten() y_vals = sigmoid(a_vals) # 回帰曲面を作図 ax.scatter(x_nd[t_n == 0, 0], x_nd[t_n == 0, 1], np.repeat(0, np.sum(t_n == 0)), c='darkturquoise', label='class 0') # クラス0の観測データ ax.scatter(x_nd[t_n == 1, 0], x_nd[t_n == 1, 1], np.repeat(1, np.sum(t_n == 1)), c='orange', label='class 1') # クラス1の観測データ ax.scatter(x_nd[t_n == 0, 0], x_nd[t_n == 0, 1], np.repeat(0.0, np.sum(t_n == 0)), facecolor='none', edgecolors='darkturquoise', linestyles='--') # クラス0の観測データ:(底面) ax.scatter(x_nd[t_n == 1, 0], x_nd[t_n == 1, 1], np.repeat(0.0, np.sum(t_n == 1)), facecolor='none', edgecolors='orange', linestyles='--') # クラス1の観測データ:(底面) plt.contour(X1, X2, model_density.reshape(x_dims), alpha=0.5, linestyles=':', offset=0.0) # データ生成分布:(底面) ax.plot_surface(X1, X2, y_vals.reshape(x_dims), cmap='jet', alpha=0.5) # 回帰曲面 ax.contour(X1, X2, y_vals.reshape(x_dims), colors='red', levels=[0.5], offset=0.5) # 決定境界 ax.contour(X1, X2, y_vals.reshape(x_dims), colors='red', alpha=0.5, linestyles='--', levels=[0.5], offset=0.0) # 決定境界:(底面) ax.set_xlabel('$x_1$') ax.set_ylabel('$x_2$') ax.set_zlabel('t') ax.set_title('iter:' + str(i+1) + ', E(w)=' + str(np.round(E, 3)) + ', w=(' + ', '.join([str(w) for w in np.round(w_m, 2)]) + ')', loc='left') ax.legend() #ax.view_init(elev=0, azim=315) # 表示アングル:(横から) #ax.view_init(elev=90, azim=270) # 表示アングル:(上から) # gif画像を作成 anime_logistic = FuncAnimation(fig, update, frames=max_iter, interval=100) # gif画像を保存 anime_logistic.save('ch4_3_2_LogisticRegression2D_srf.gif')
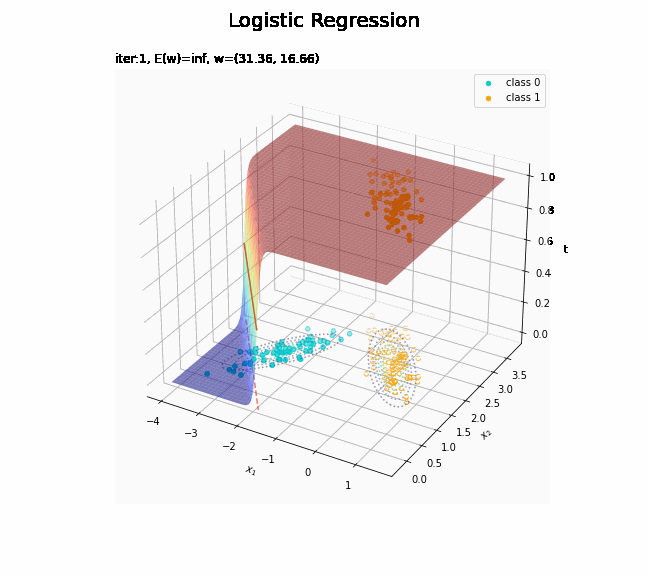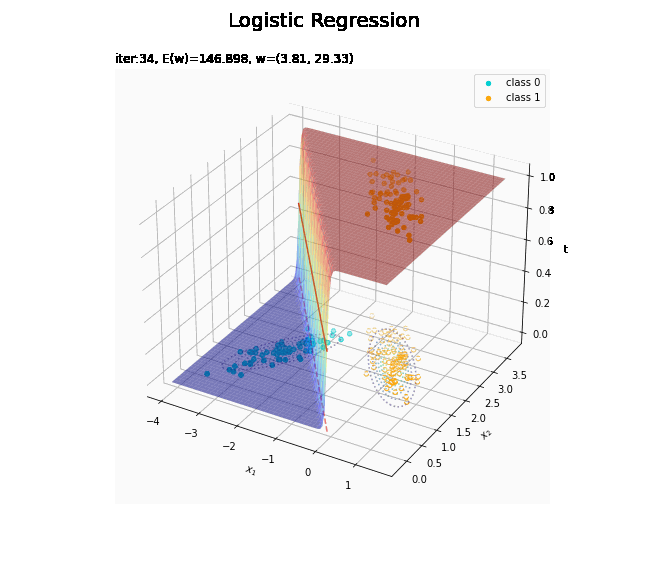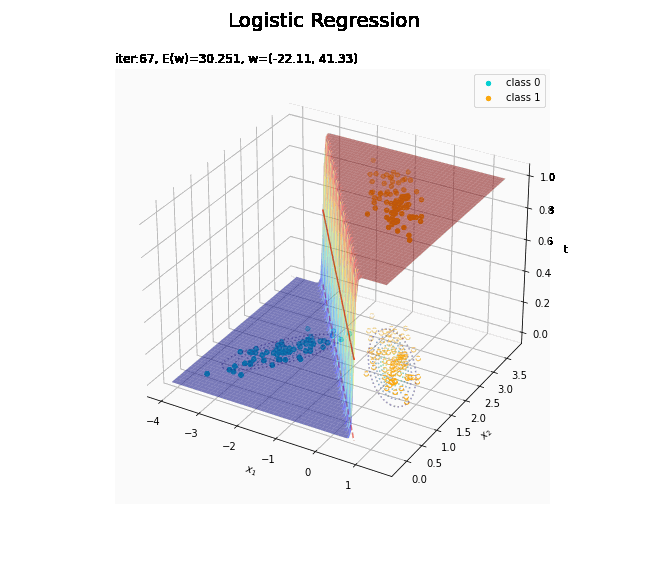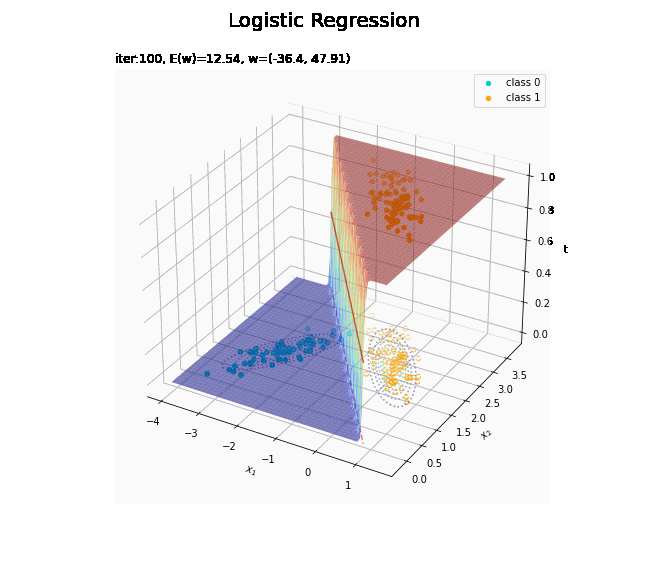
徐々にデータに適合していくのを確認できます。
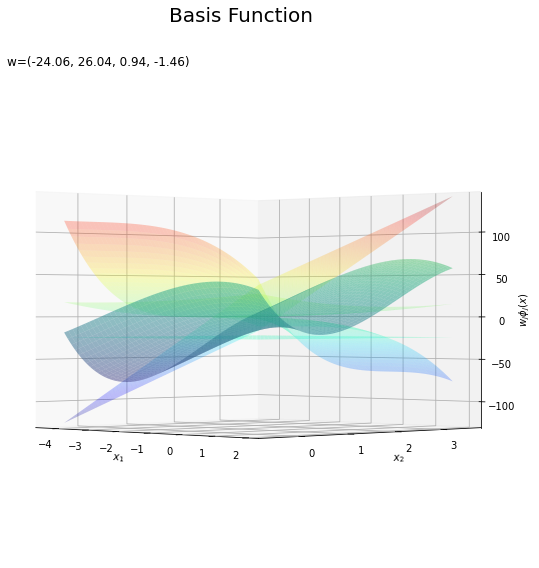
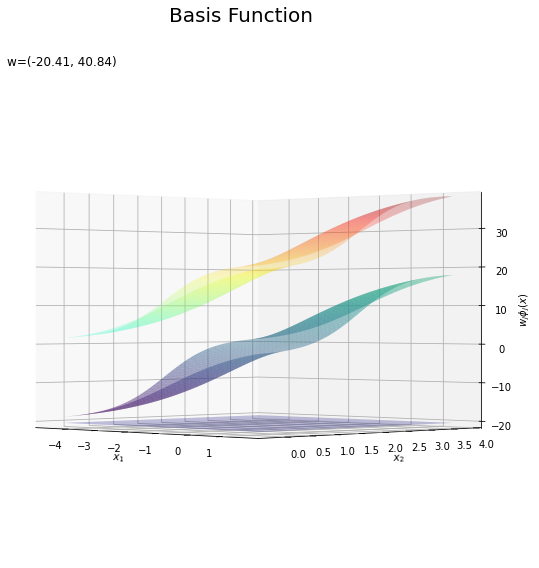
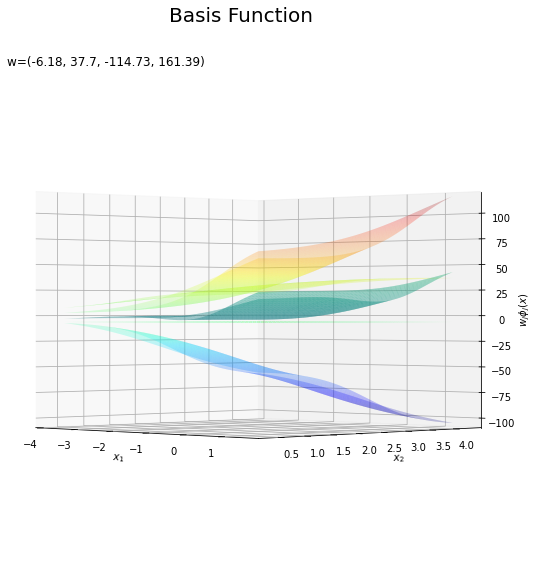
基底関数と重みパラメータの関係を確認します。基底関数ごとに対応するパラメータで重み付けしてグラフを描画します。
# 基底関数ごとに重み付け weight_phi_x_vals = w_m * phi_x_vals # 重み付けした基底関数を作図 fig = plt.figure(figsize=(12, 9)) ax = fig.add_subplot(projection='3d') # 3D用の設定 for m in range(M): ax.plot_surface(X1, X2, phi_x_vals[:, m].reshape(x_dims), cmap='jet', vmin=np.min(phi_x_vals), vmax=np.max(phi_x_vals), alpha=0.25) # 基底関数 #ax.plot_surface(X1, X2, weight_phi_x_vals[:, m].reshape(x_dims), # cmap='jet', vmin=np.min(weight_phi_x_vals), vmax=np.max(weight_phi_x_vals), alpha=0.25) # 重み付け基底関数 #ax.plot_surface(X1, X2, a_vals.reshape(x_dims), # cmap='viridis', vmin=np.min(weight_phi_x_vals), vmax=np.max(weight_phi_x_vals), alpha=0.5) # 重み付き和 ax.set_xlabel('$x_1$') ax.set_ylabel('$x_2$') ax.set_zlabel('$\phi_j(x)$') # 基底関数 #ax.set_zlabel('$w_j \phi_j(x)$') # 重み付け基底関数 fig.suptitle('Basis Function', fontsize=20) ax.set_title('w=(' + ', '.join([str(w) for w in np.round(w_m, 2)]) + ')', loc='left') #ax.view_init(elev=0, azim=315) # 表示アングル plt.show()
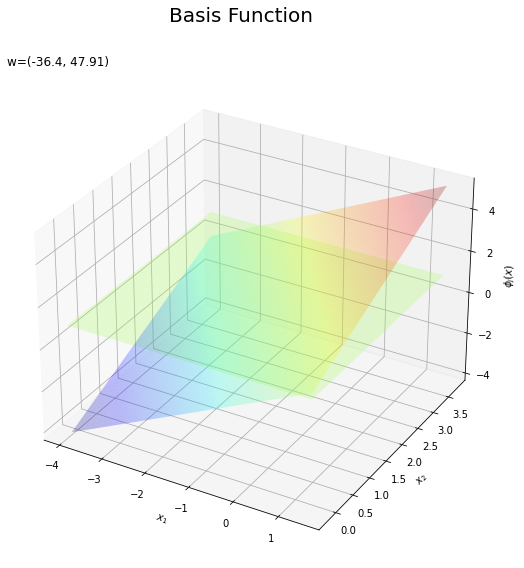
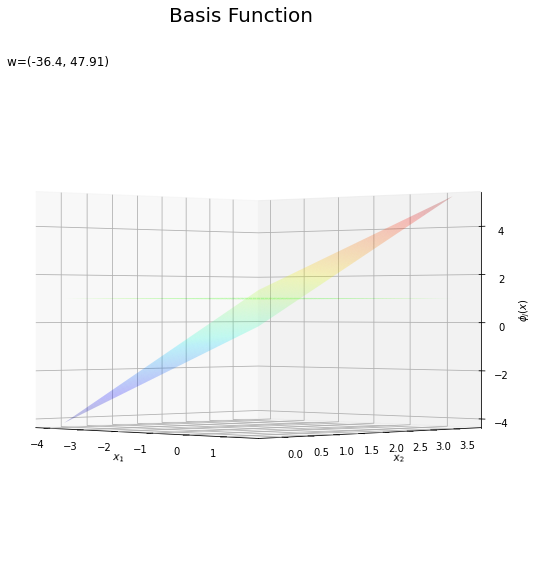
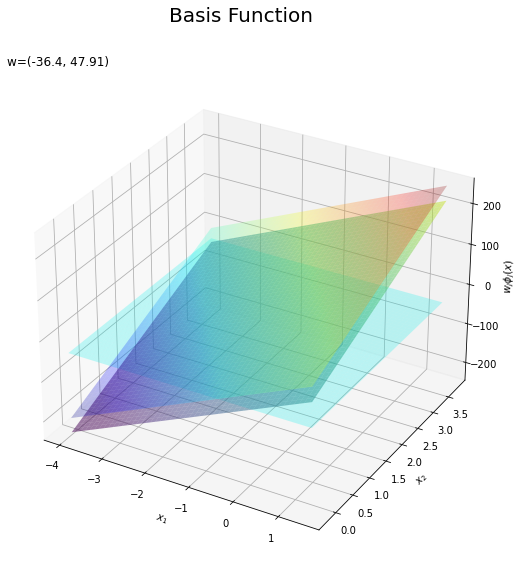
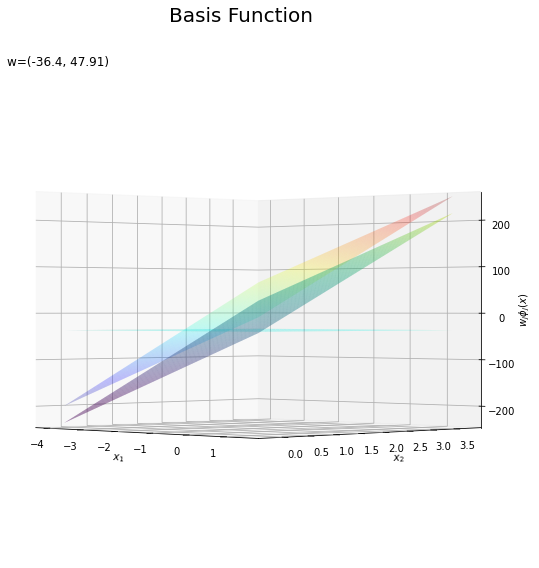
上の図は基底関数で、下の図は重み付けした基底関数と重み付き和のグラフです。$m = 0$の項はバイアスパラメータなので、$\phi_0(\mathbf{x}) = 1$、$w_0 \phi_0(\mathbf{x}) = w_0$で水平になります。
重み付けした基底関数(青から赤のグラデーション)をz軸方向に和をとったものが重み付き和(紫から黄のグラデーション)です。
重み付き和をシグモイド関数によって0から1の値に変換しものが回帰曲面です。
誤差の推移のグラフを作成します。
# 誤差の推移を作図 plt.figure(figsize=(12, 9)) plt.plot(np.arange(1, max_iter+1), trace_E_list) plt.xlabel('iteration') plt.ylabel('E(w)') plt.suptitle('Cross-Entropy Error', fontsize=20) plt.title('$E(w^{(' + str(max_iter) + ')})=' + str(np.round(trace_E_list[max_iter-1], 3)) + '$', loc='left') plt.grid() plt.show()
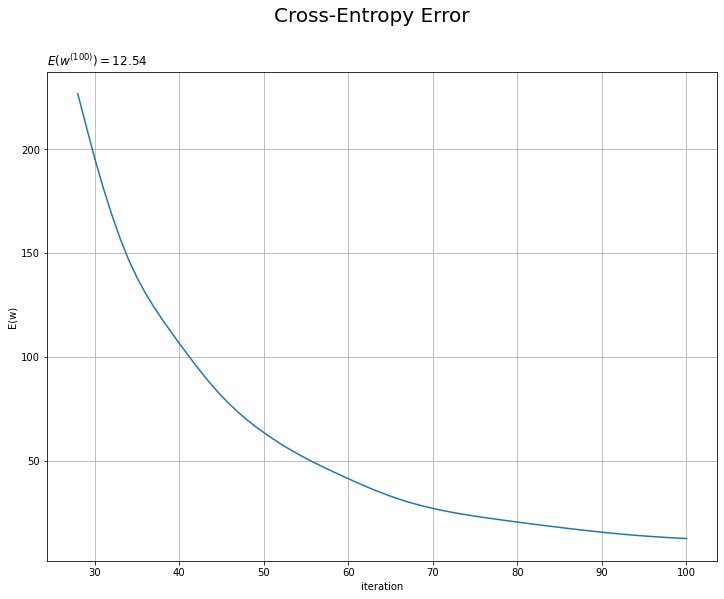
試行回数が増えるにしたがって誤差が小さくなっているのを確認できます。交差エントロピー誤差(負の対数尤度関数)の値が下がるのは、尤度関数の値が上がるのを意味します。
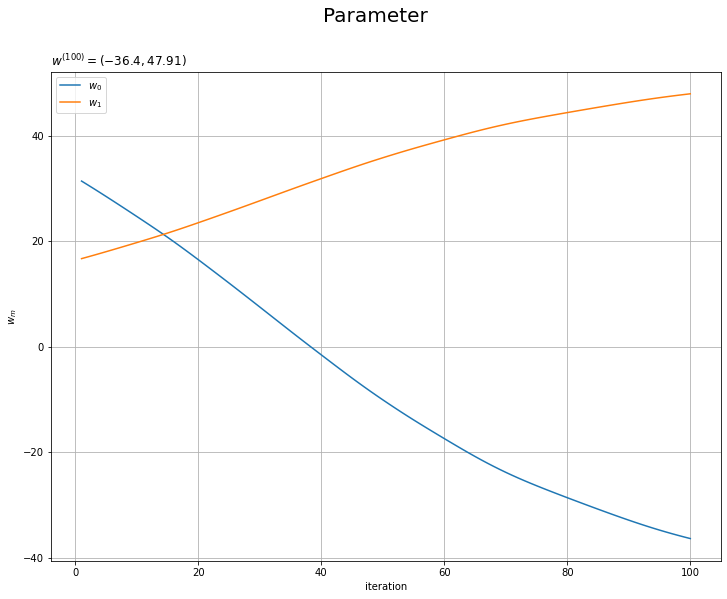
重みパラメータの推移のグラフを作成します。
# 重みの推移を作図 plt.figure(figsize=(12, 9)) for m in range(M): plt.plot(np.arange(1, max_iter+1), trace_w_arr[:, m], label='$w_' + str(m) + '$') plt.xlabel('iteration') plt.ylabel('$w_m$') plt.suptitle('Parameter', fontsize=20) plt.title('$w^{(' + str(max_iter) + ')}=(' + ', '.join([str(w) for w in np.round(trace_w_arr[max_iter-1], 2)]) + ')$', loc='left') plt.legend() plt.grid() plt.show()
以上で、ロジスティック回帰の最尤推定を実装と結果の可視化ができました。
他の設定での推定結果をいくつか見ます。
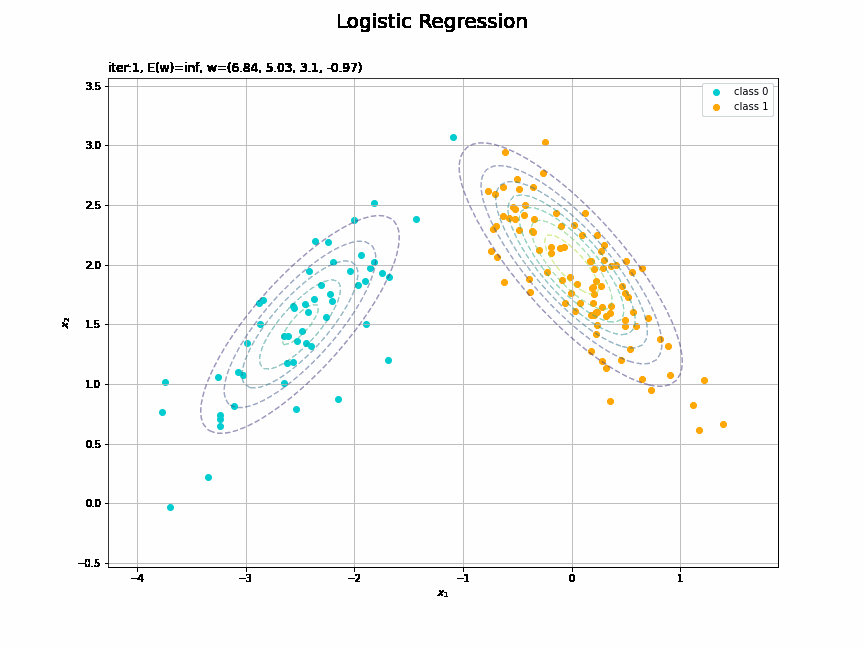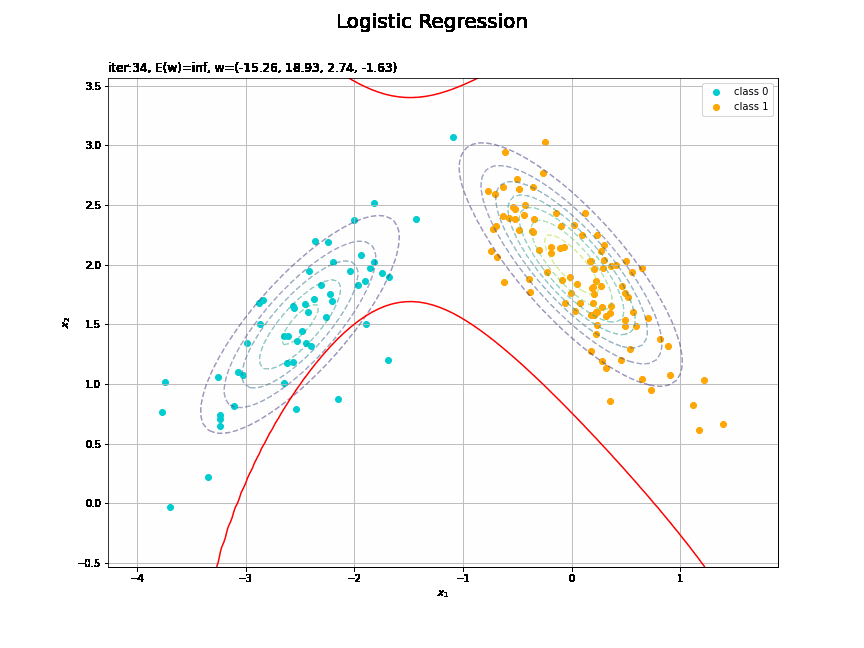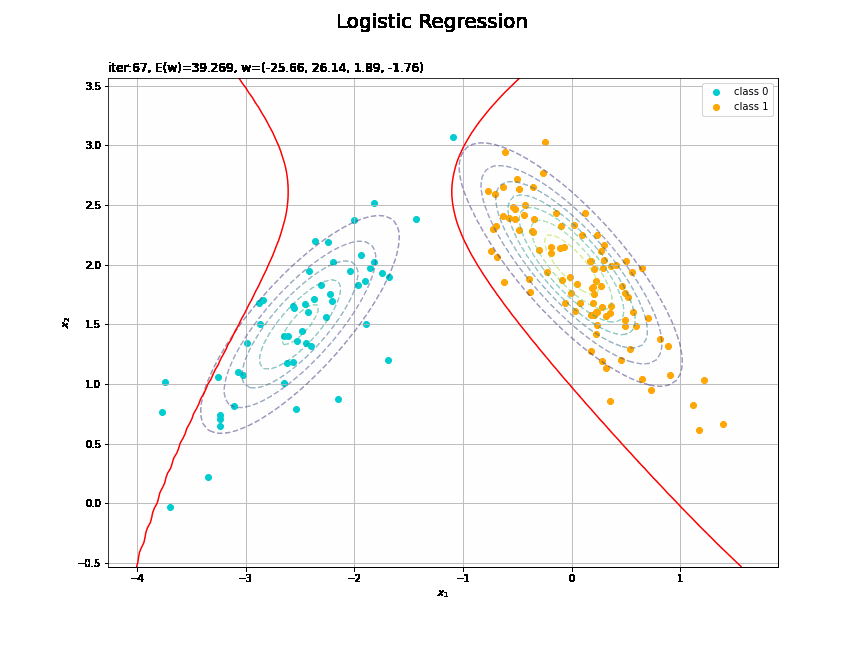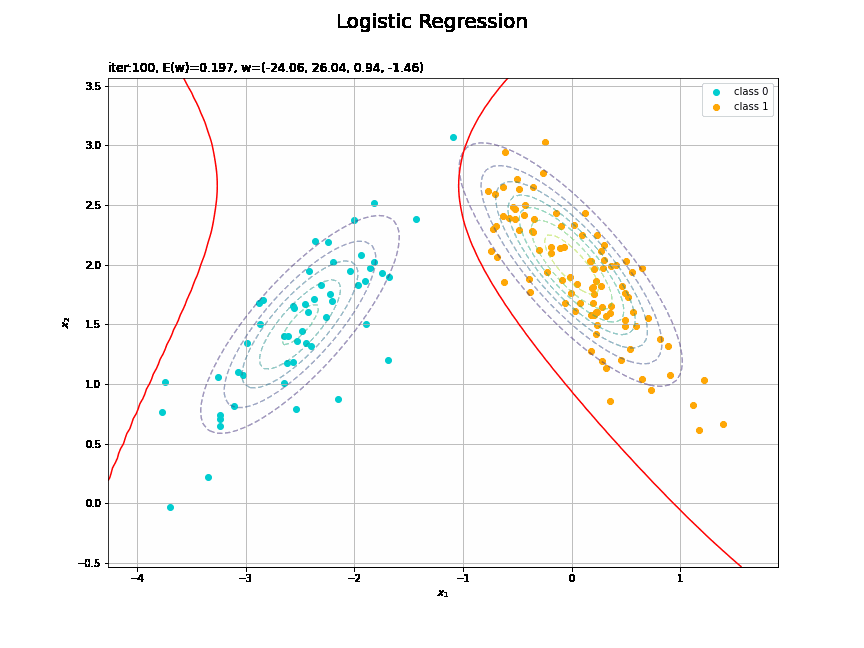
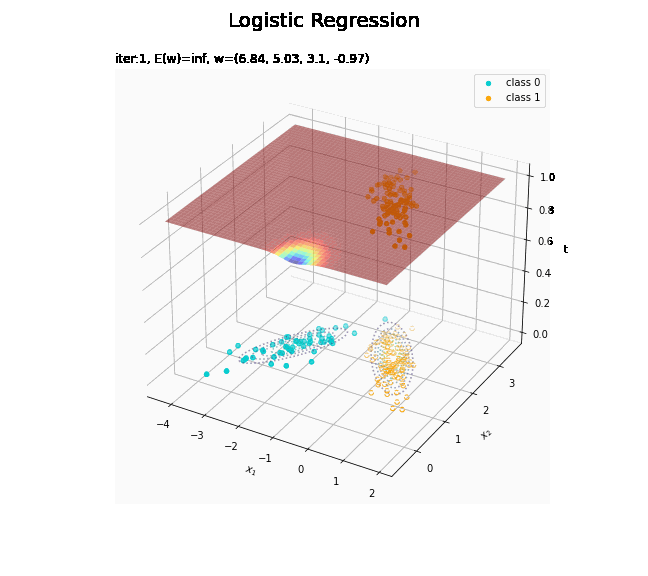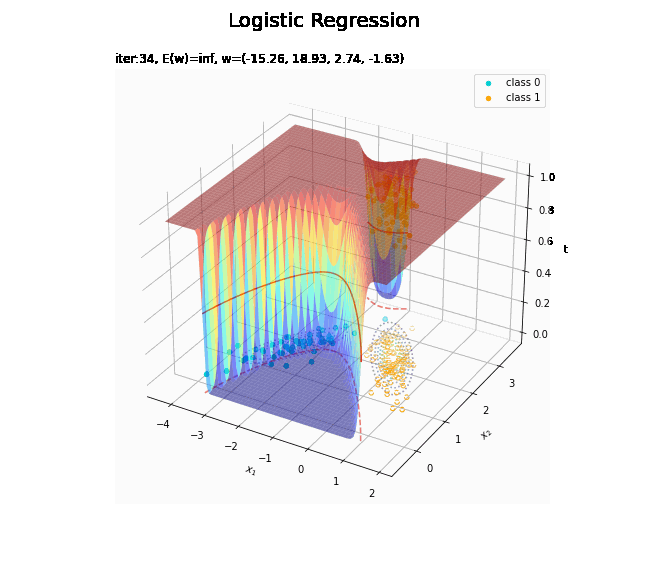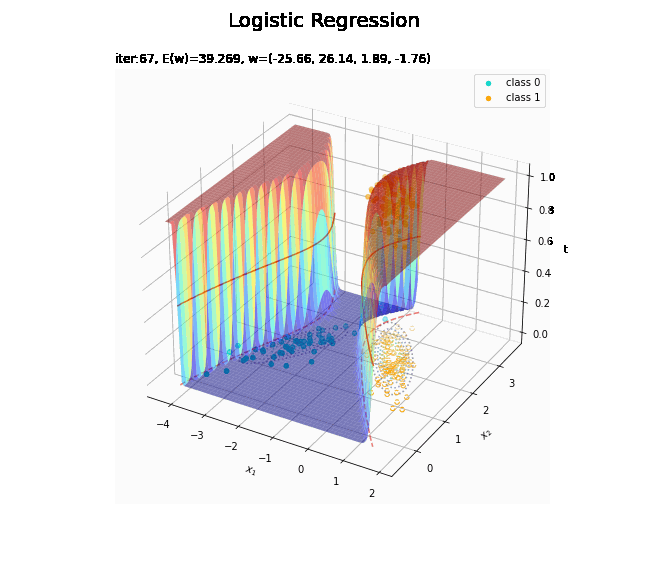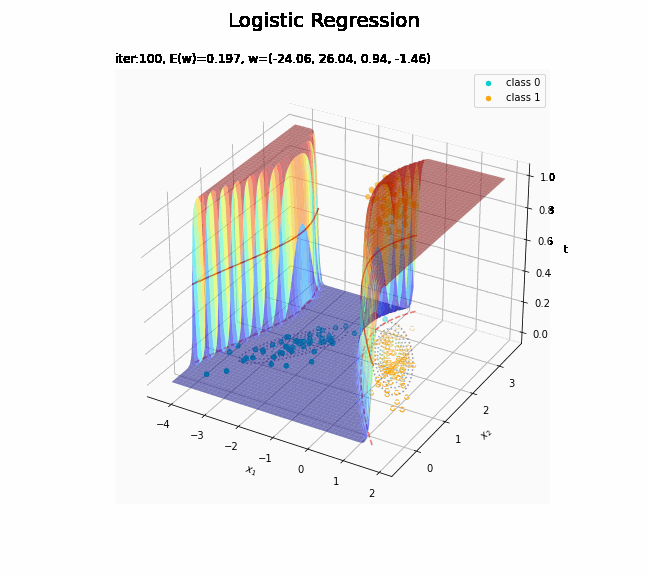
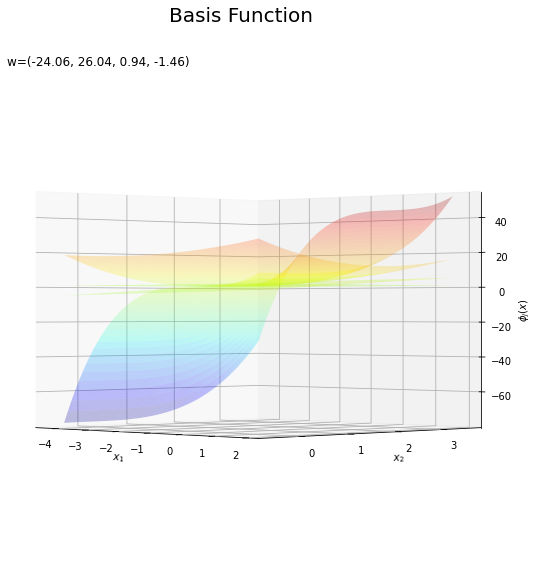
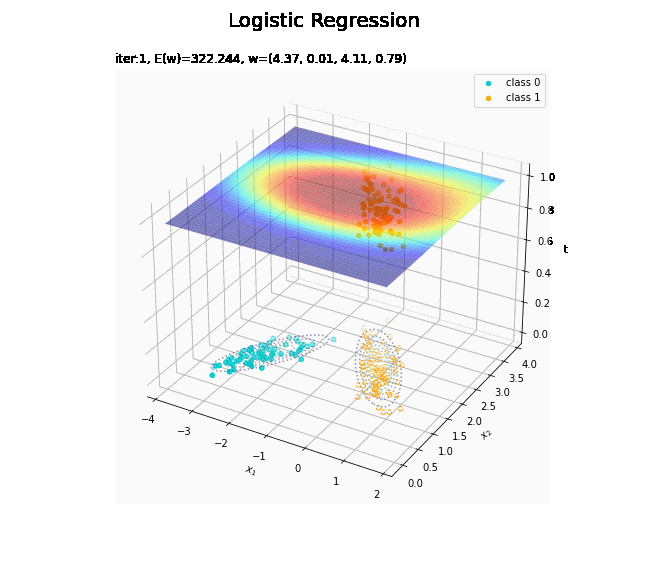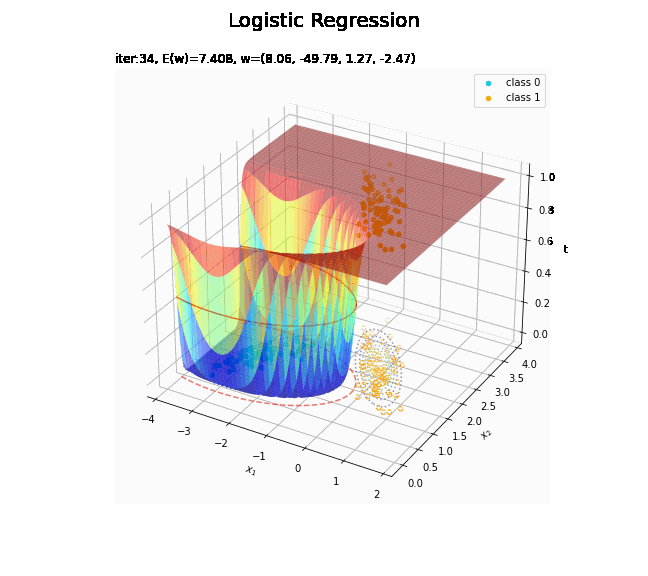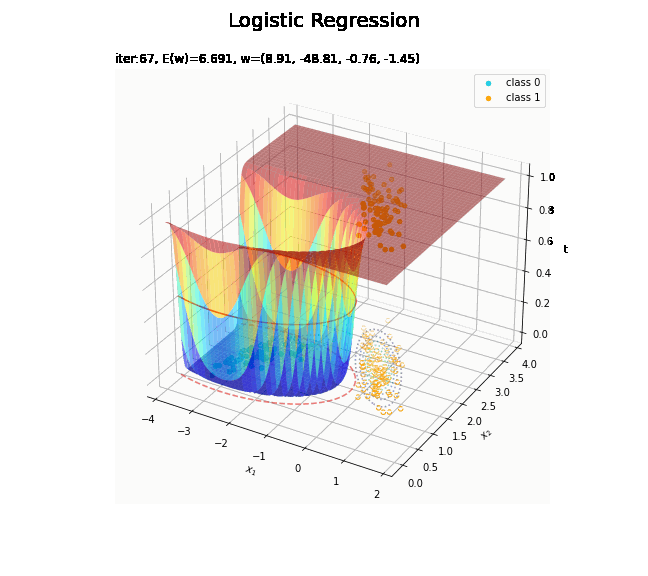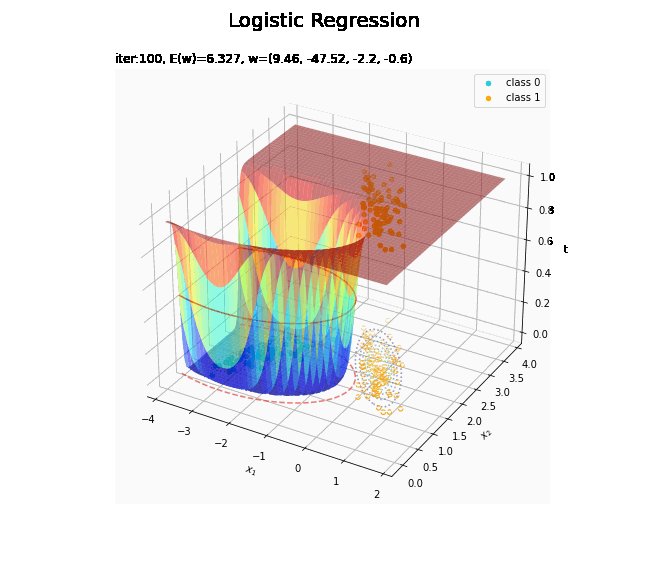
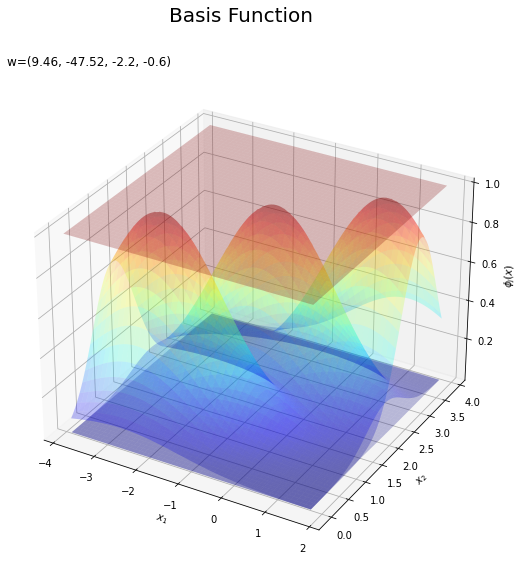
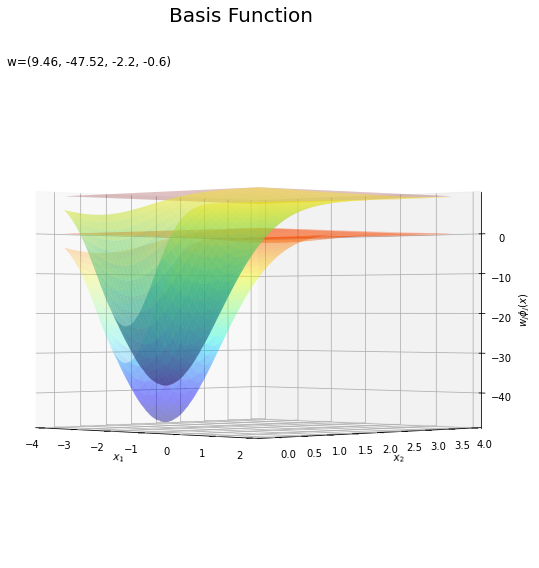
(対角線に基底関数(の平均)を並べる限界を感じる。)
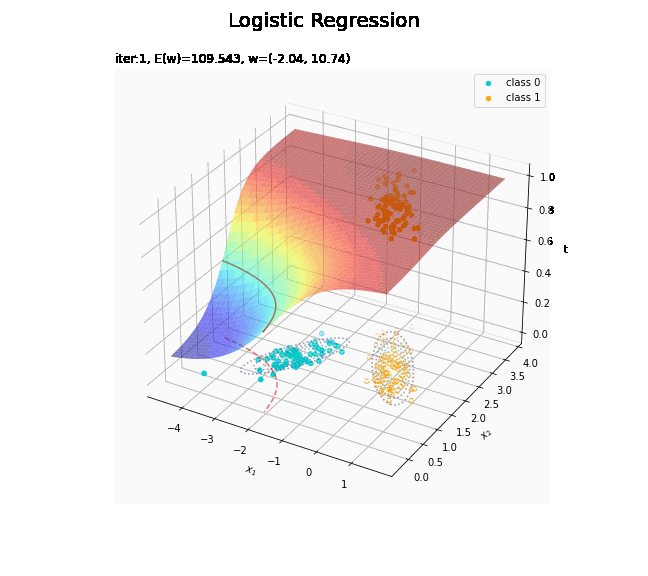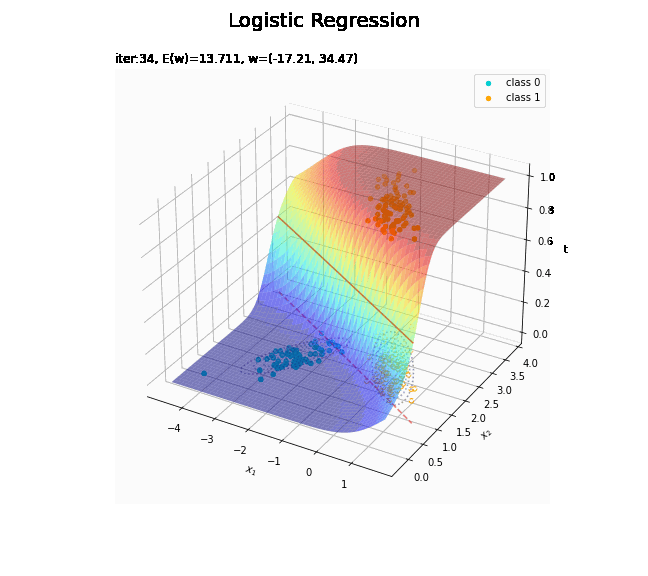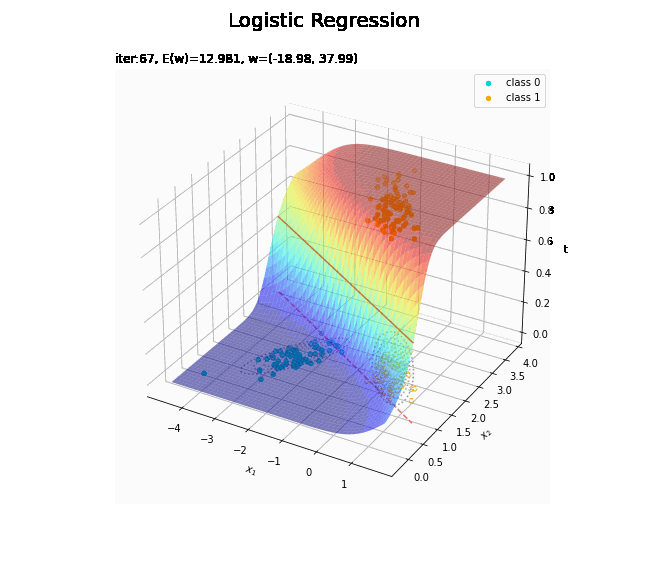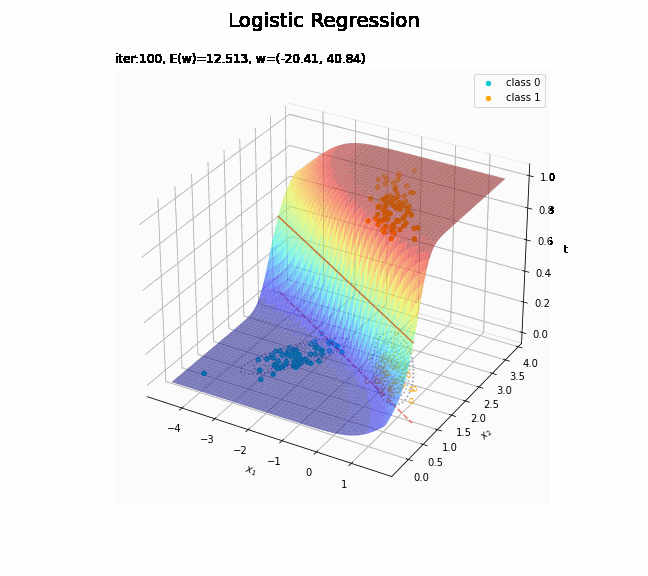
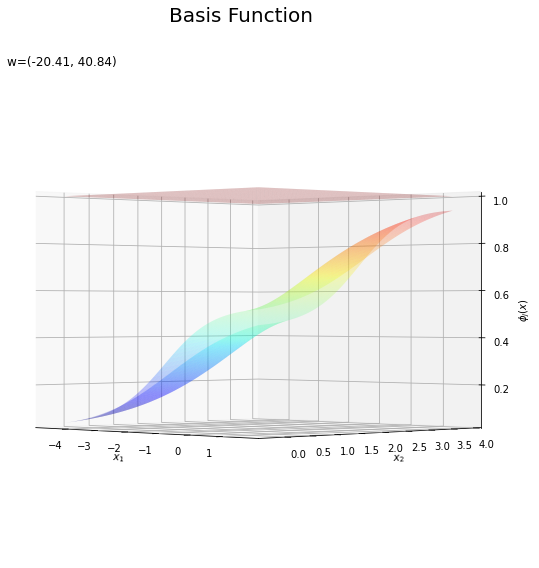
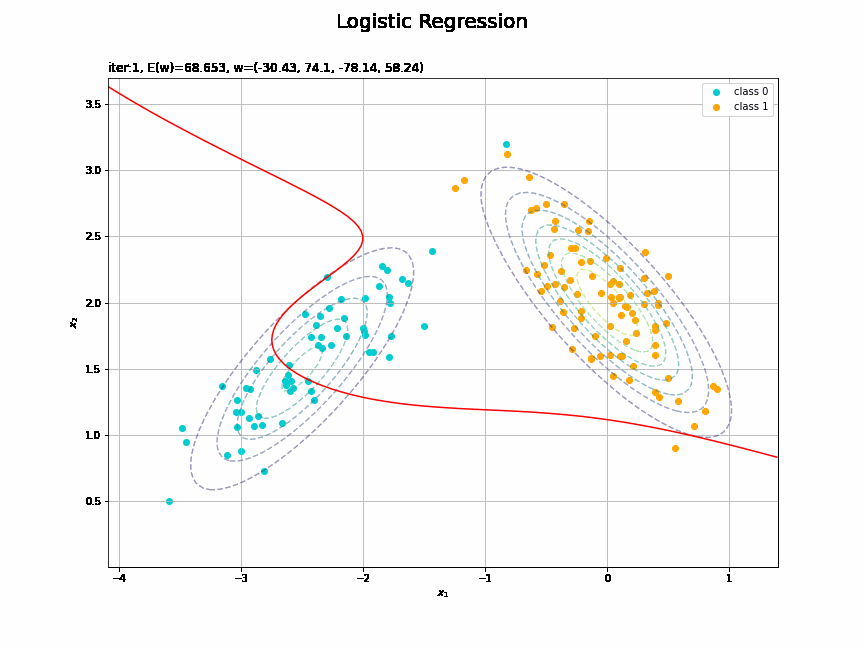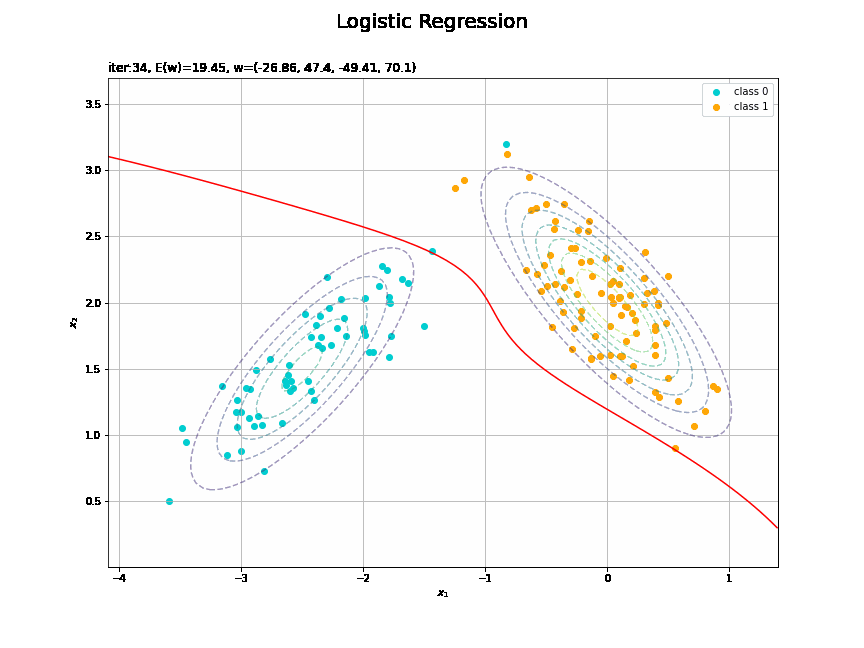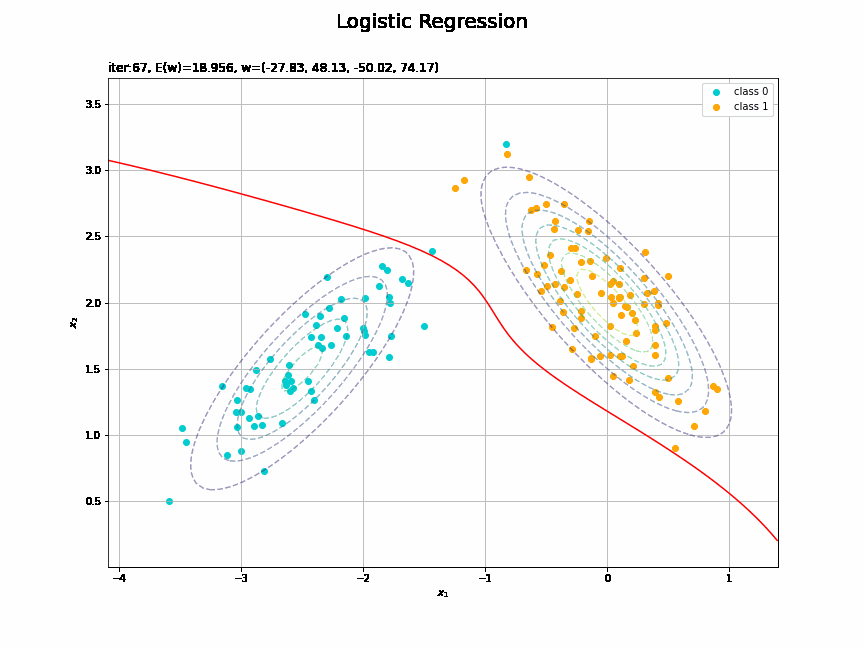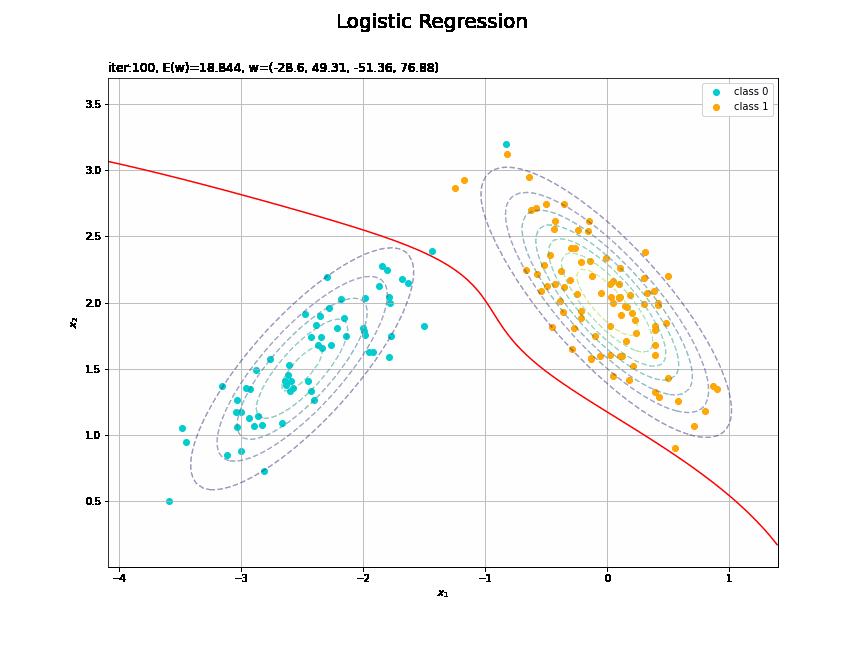
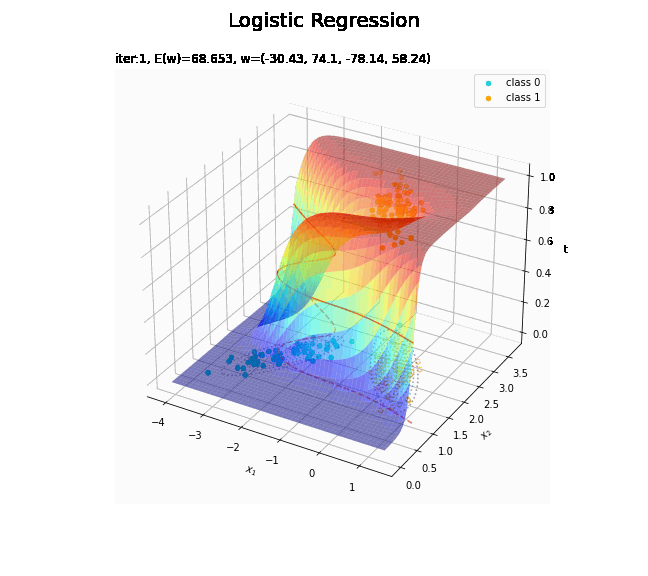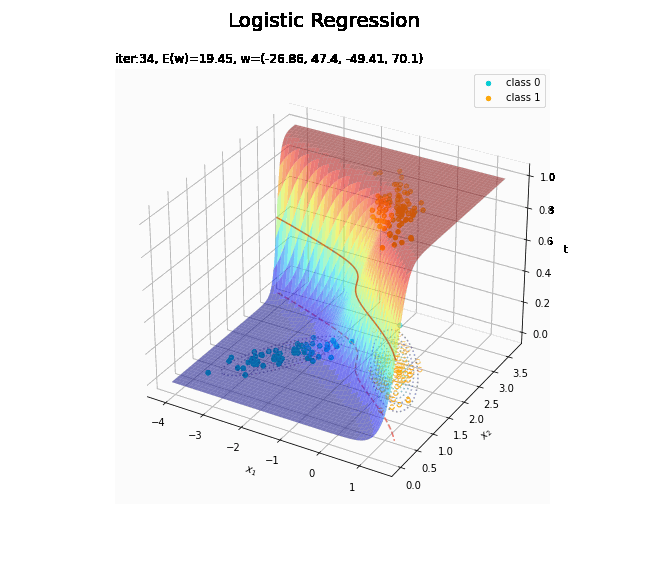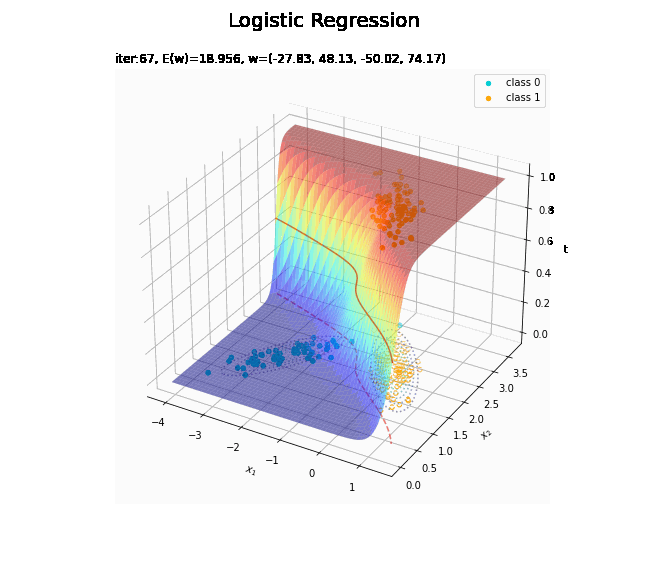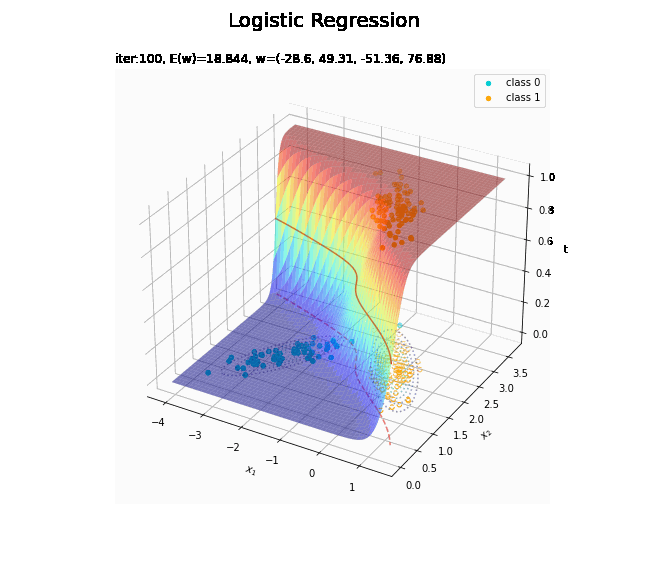
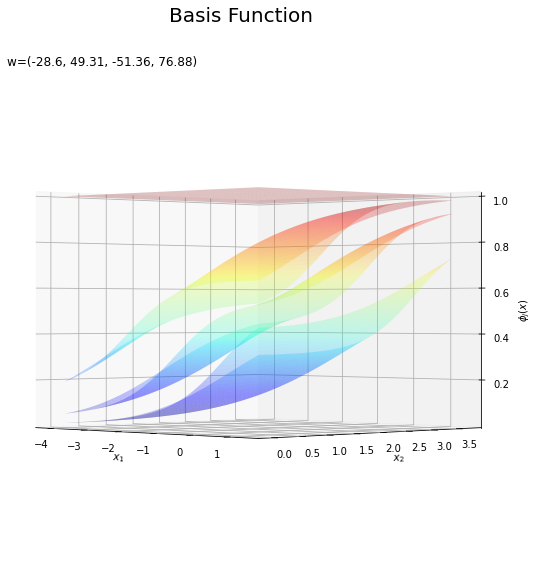
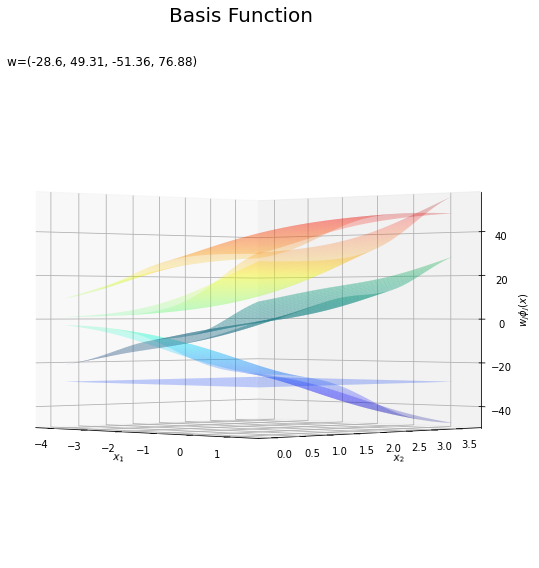
どの基底関数でも$M$を増やすと過学習が起きてそうな感じです。ただ、このデータの配置はシグモイド基底関数の配置的に境界線を引きやすくなっていると思うので、データ生成のパラメータを変えてみます。
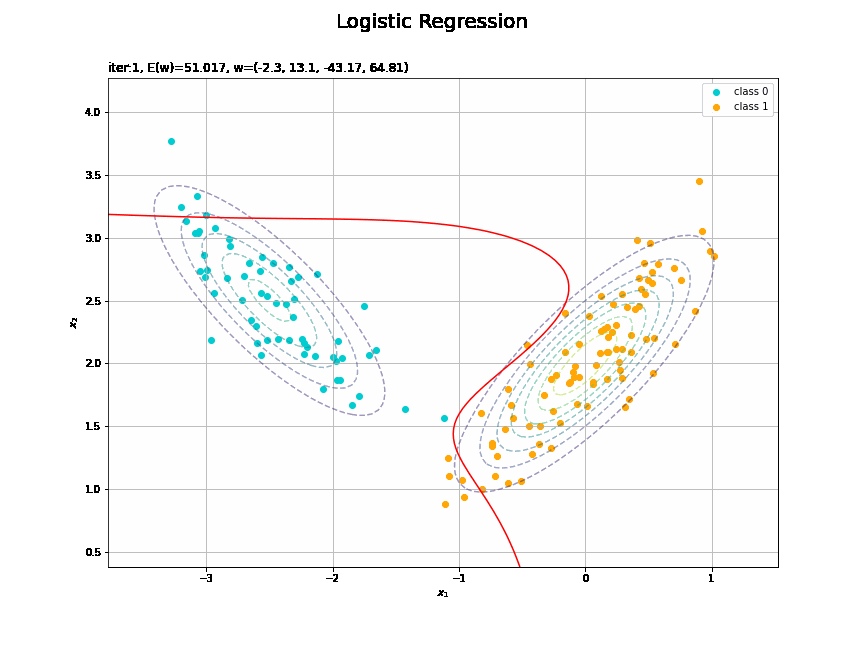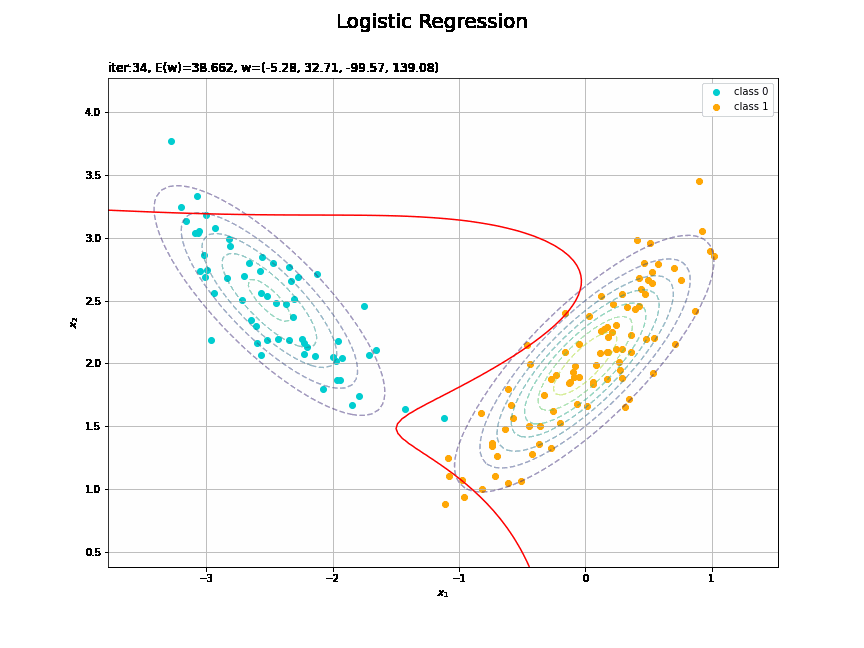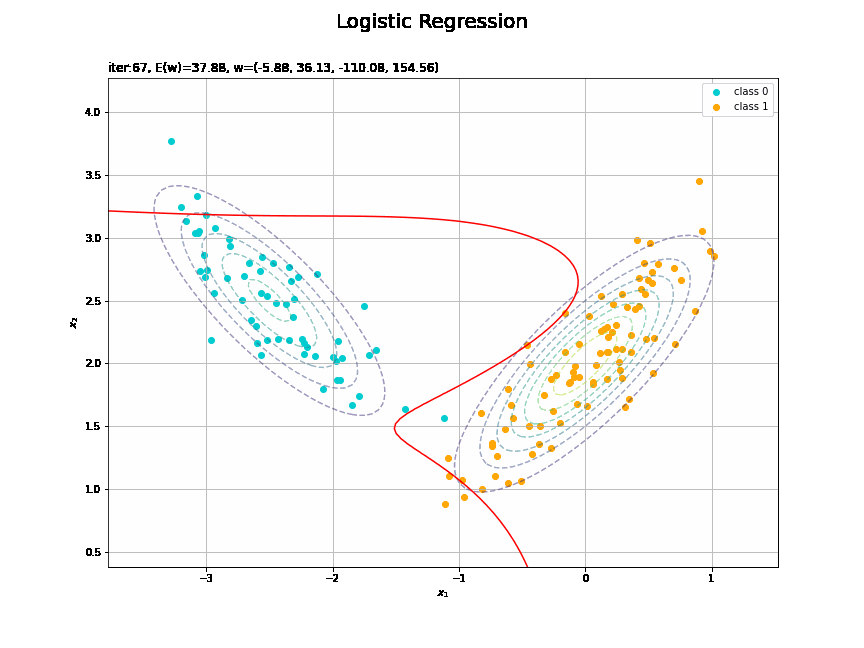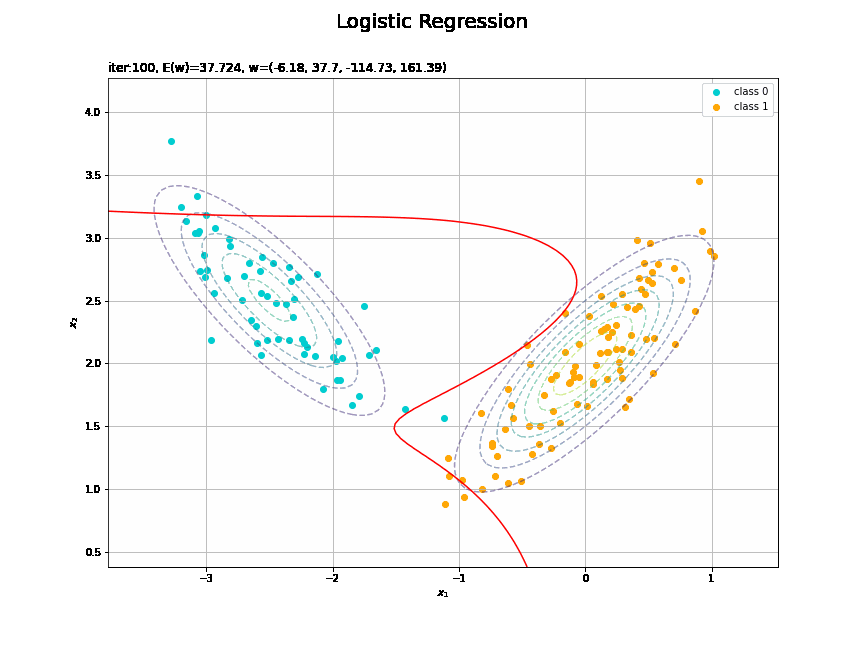
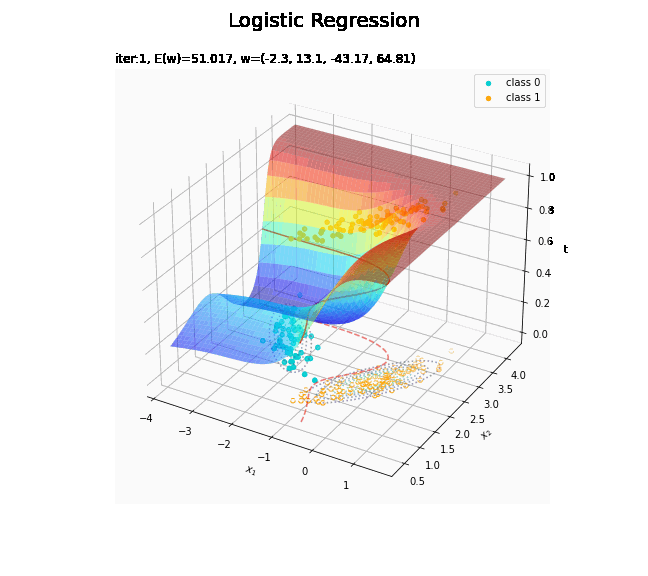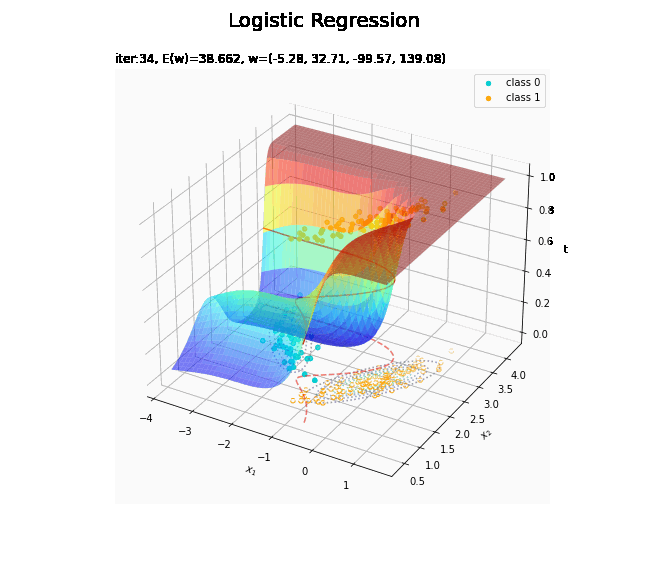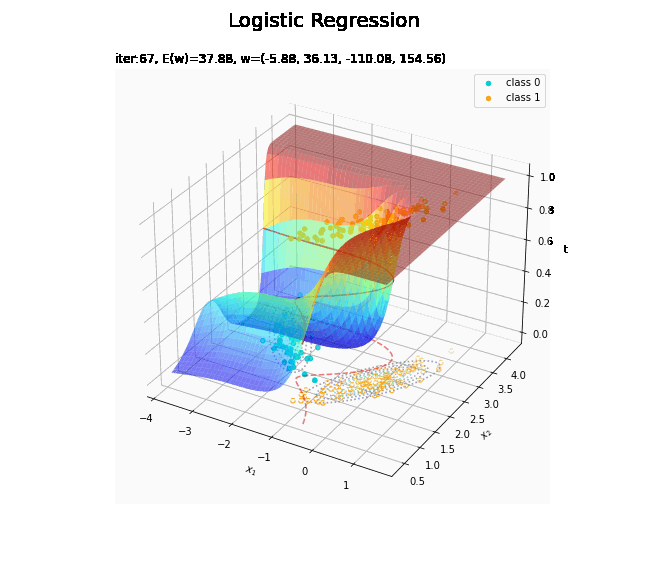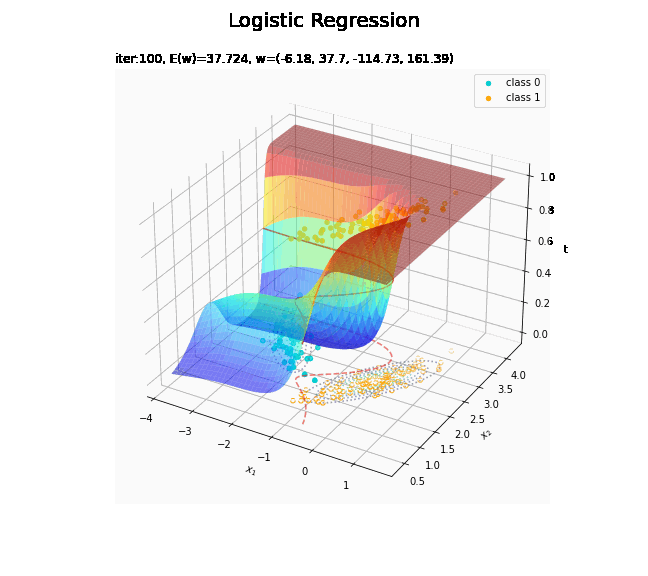
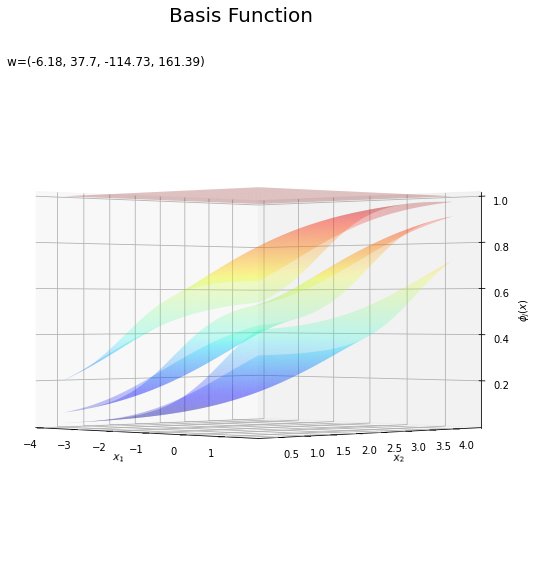
これは過学習なのかどうなのか。もう少しスマートに実装したい。
参考文献
- C.M.ビショップ著,元田 浩・他訳『パターン認識と機械学習 上下』,丸善出版,2012年.
おわりに
基底関数の実装がゆるふわなんですが、とりあえずできたので良し。
【次節の内容】