はじめに
『ゼロからできるMCMC』の図とサンプルコードをR言語で再現します。本と一緒に読んでください。
この記事は2章の内容です。マルコフ連鎖を使わない素朴なモンテカルロ法の例を確認します。
【他の章の内容】
【この章の内容】
2.1 そもそも乱数とは
# 2章で利用するパッケージ library(tidyverse) library(gganimate)
gganimateパッケージは、gif画像を作成するパッケージです。推移をアニメーションで確認するのに使います。
2.1.1 一様乱数
この資料では、疑似乱数の生成に関しては踏み込まず、組み込み関数を使うことにします。
準備運動がてらに、簡単な処理から始めましょう。一様分布に従う乱数(一様乱数)は、runif()で生成できます。runif()の各引数(データ数n、最小値min、最大値max)にそれぞれ値を指定します。生成した乱数はデータフレームに格納しておきます。ggplot2パッケージを利用して作図するには、データフレームを渡す必要があるためです。
# 乱数の個数を指定 K <- 100000 # 一様分布の最小値を指定 a <- -2 # 一様分布の最大値を指定 b <- 3 # 一様乱数をデータフレームに格納 uniform_df <- tibble( x = runif(n = K, min = a, max = b) # 乱数を生成 ) # ヒストグラムをプロット ggplot(uniform_df, aes(x = x)) + geom_histogram(binwidth = 0.1) + # ヒストグラム labs(title = "Uniform Distribution", subtitle = paste0("K=", K))
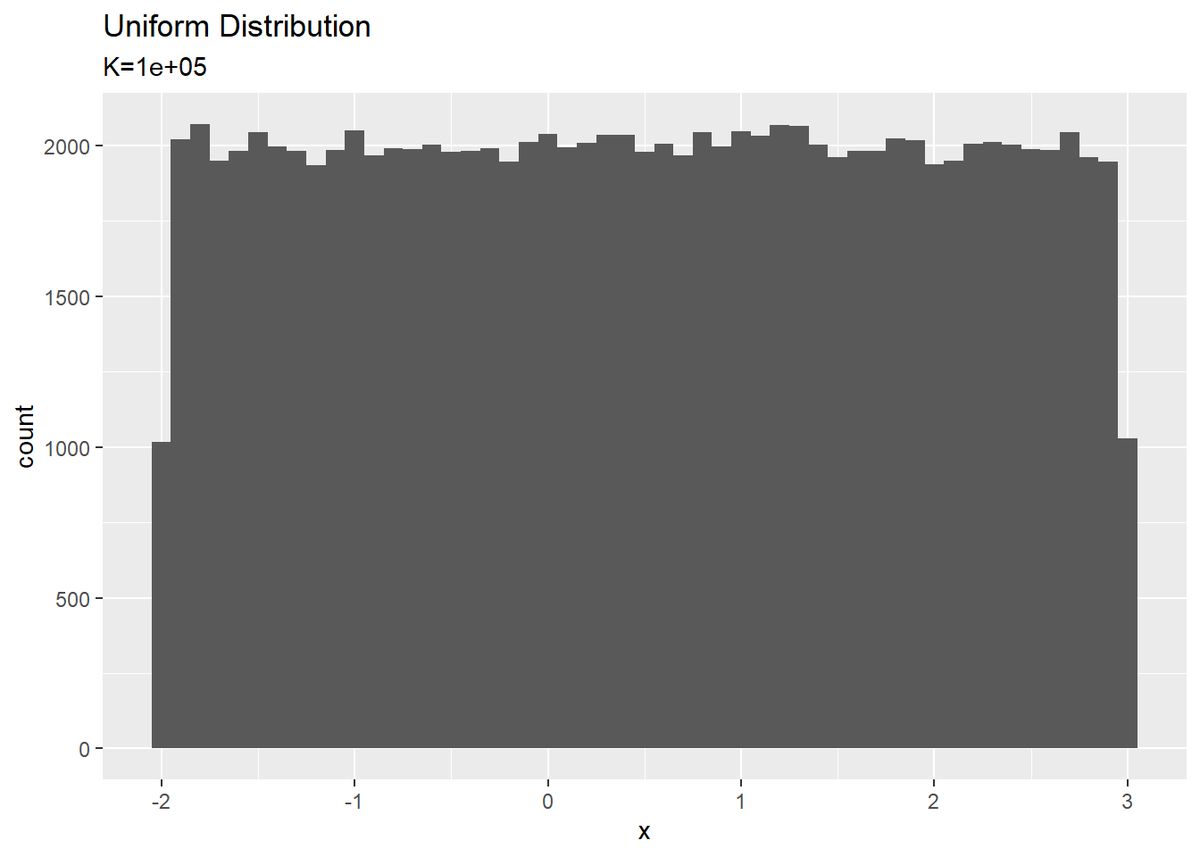
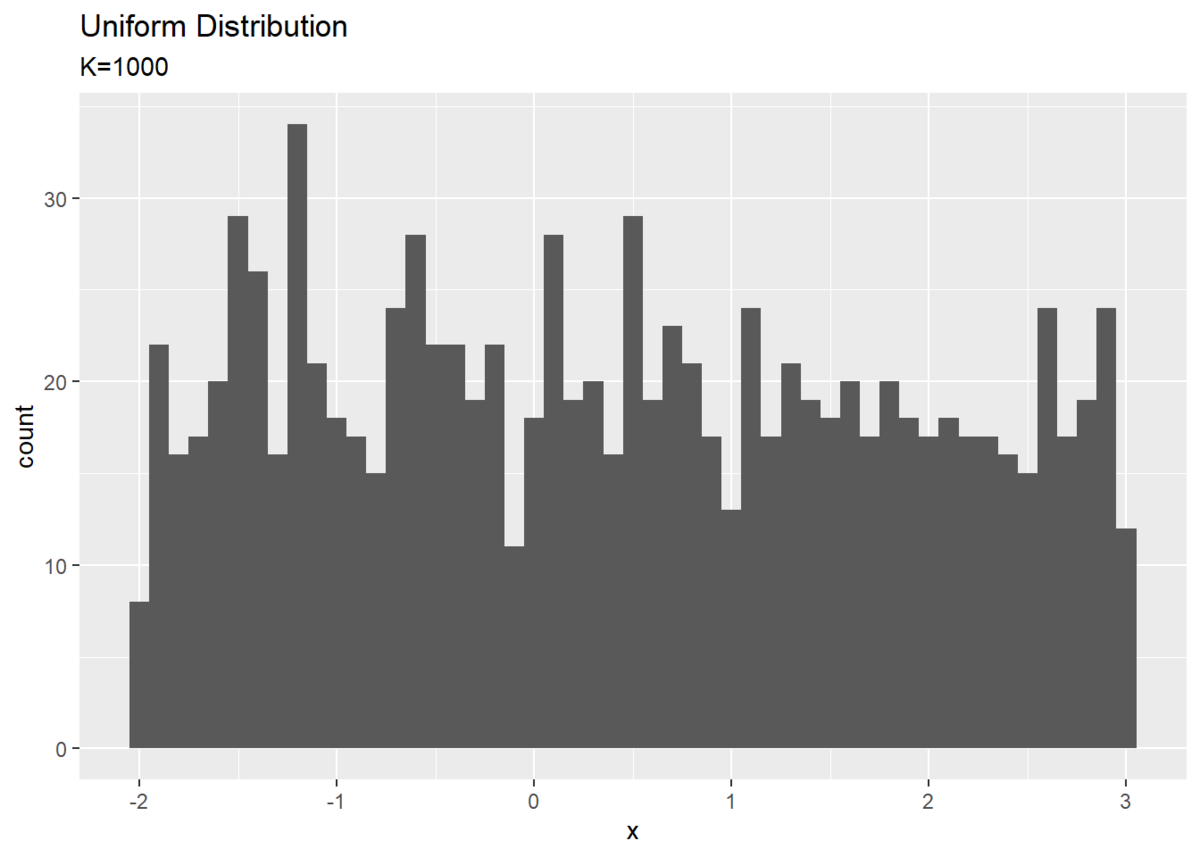
データ数$K$が大きくなるにつれてグラフが平らに近づく(満遍なく乱数が生成される)のを確認できます。
続いて、一様分布自体を確認しましょう。連続値の確率分布は、$P(x)$と表記しても確率ではなく確率密度であることに注意しましょう。一様分布の確率密度はdunif()で計算できます。第1引数xに指定した値に対応する確率密度を返します。
# x軸の値と対応する確率密度をデータフレームに格納 uniform_df <- tibble( x = seq(a - 1, b + 1, 0.01), # x軸の描画範囲 P_x = dunif(x = x, min = a, max = b) # 確率密度を計算 ) # 一様分布をプロット ggplot(uniform_df, aes(x = x, y = P_x)) + geom_line() + # 折れ線グラフ labs(title = "Uniform Distribution", subtitle = paste0("a=", a, ", b=", b), y = "density")
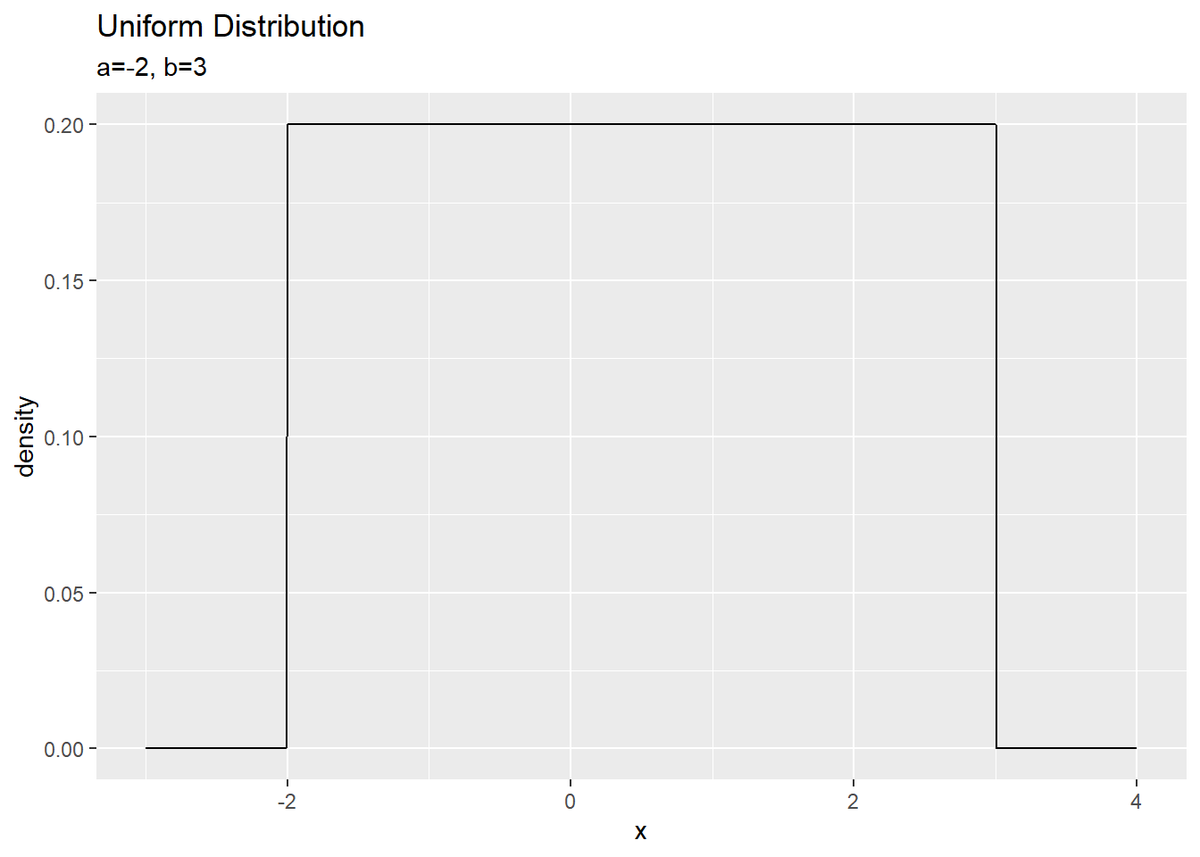
$a \leq x \leq b$のときどの$x$の確率密度も$P(x) = \frac{1}{b - a}$であり、$x < a,\ b < x$のとき$P(x) = 0$である分布です。また$a$から$b$の範囲の面積は$(b - a) P(x) = 1$になります。これを式で表すと$\int P(x) dx = 1$です。
この項では、(連続値の)一様分布を簡単に確認しました。次項では、(1次元の)ガウス分布について確認します。
2.1.2 ガウス乱数(正規乱数)
1次元ガウス分布(正規分布)について確認していきます。まずはガウス分布のもととなるガウス関数
をグラフで見ましょう。
# ガウス関数の計算結果をデータフレームに格納 gaussian_function_df <- tibble( x = seq(-4, 4, 0.01), f_x = exp(-x^2) ) # ガウス関数をプロット ggplot(gaussian_function_df, aes(x = x, y = f_x)) + geom_line() + labs(title = expression(f(x) == exp(-x^2)), y = "f(x)", x = "x")
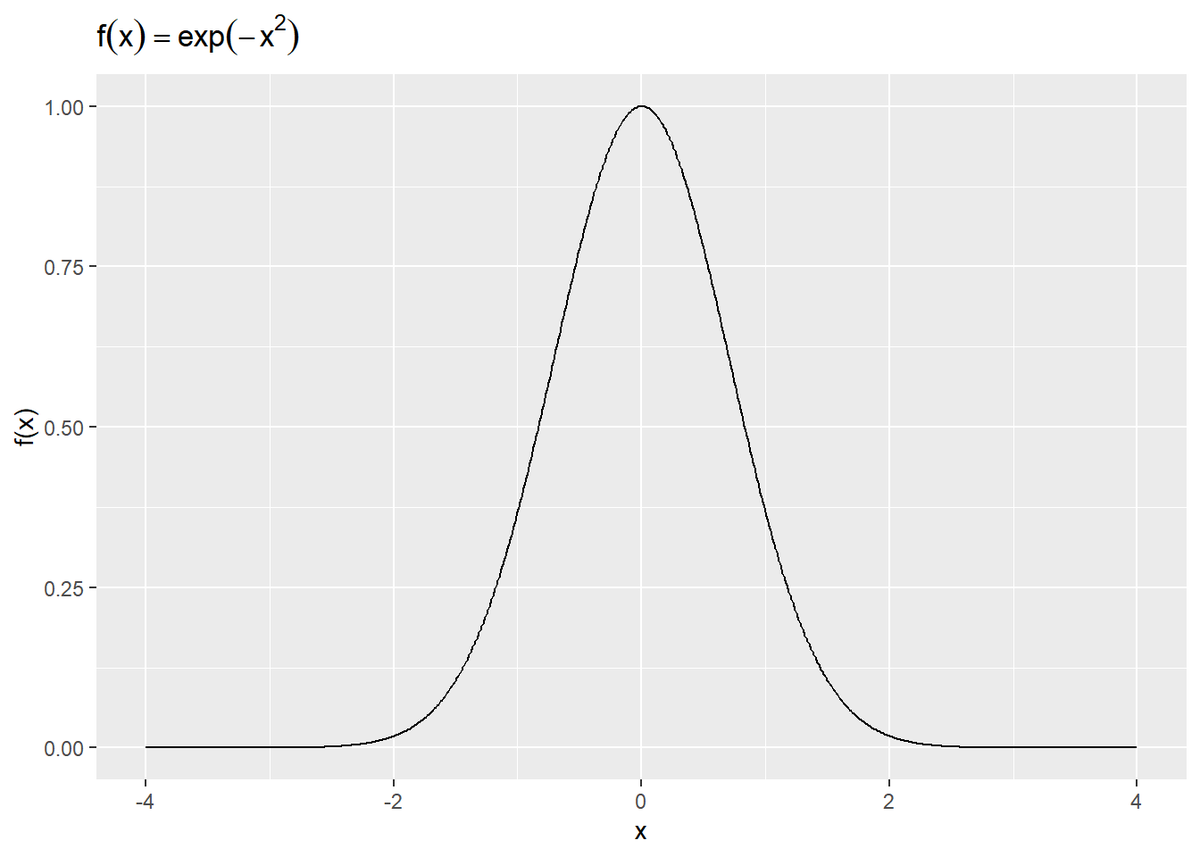
この関数の積分値は$\sqrt{\pi}$になります(この$\pi$は円周率のこと)。
そこで、関数全体を$\sqrt{\pi}$で割ります。
# 作図用のデータフレームを作成 gaussian_distribution_df <- tibble( x = seq(-4, 4, 0.01), P_x = exp(-x^2) / pi ) # ガウス分布をプロット ggplot(gaussian_distribution_df, aes(x = x, y = P_x)) + geom_line() + labs(title = expression(P(x) == exp(-x^2) / sqrt(pi)), y = "density", x = "x")
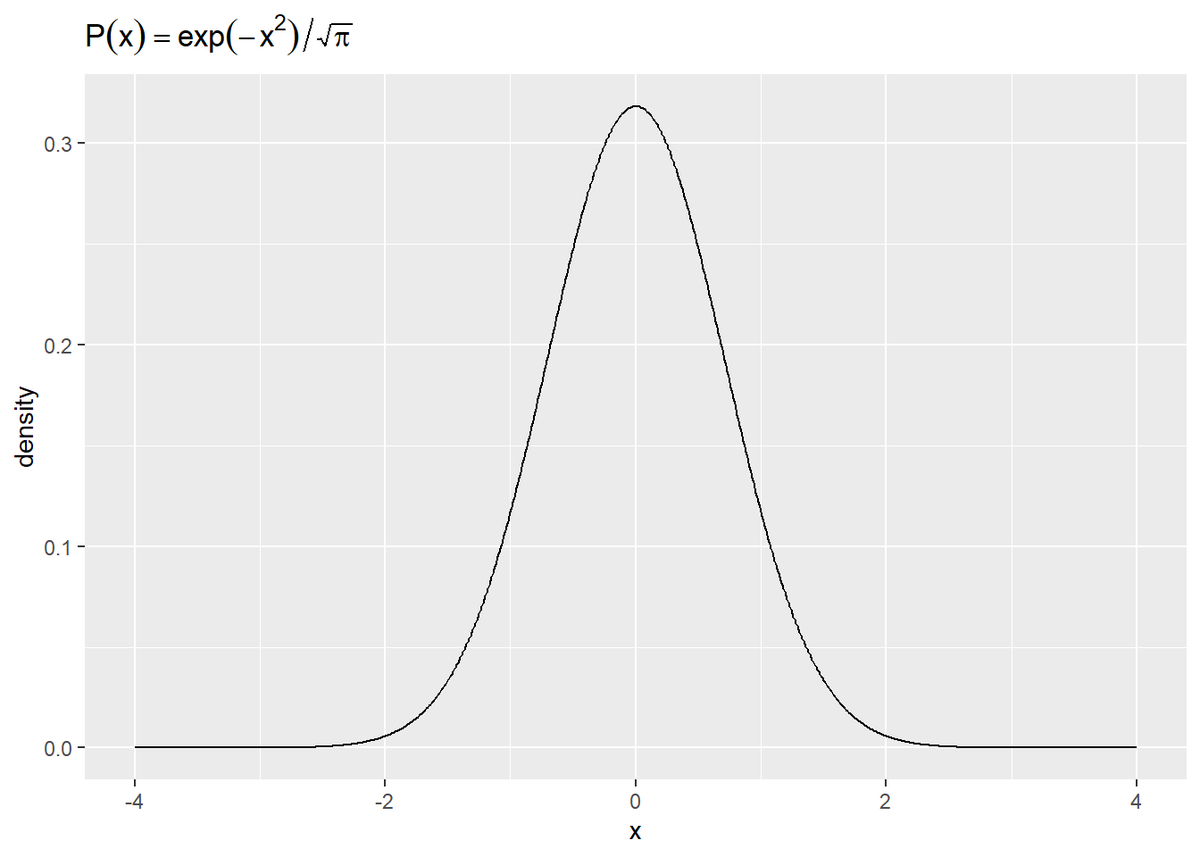
ガウス関数$\exp(-x^2)$を積分値$\sqrt{\pi}$で割ることで、その積分値が1になります($N$個のデータを総和で割って割合に変換するイメージ)。
積分して1になる関数は、確率分布(確率密度関数)として解釈できます。
このように積分して1となるように調整する項を規格化定数や正規化項と呼びます。さらに、平均(分布の中心)$\mu$と標準偏差(ばらつき具合)$\sigma$を導入します。
この確率分布(確率密度関数)を平均$\mu$、標準偏差$\sigma$(分散$\sigma^2$)の1次元ガウス分布(正規分布)と呼びます。また$\frac{1}{\sqrt{2 \pi} \sigma}$が規格化定数です。ちなみに式(2.1)は、$\mu = 0,\ \sigma = \frac{1}{\sqrt{2}}$のガウス分布であることが式から分かります。
では平均と標準偏差を指定してガウス分布をプロットしましょう。
# 平均を指定 mu <- 0 # 標準偏差を指定 sigma <- 4 # 作図用のデータフレームを作成 gaussian_distribution_df <- tibble( x = seq(-10, 10, 0.01), C_N = sqrt(2 * pi) * sigma, # 規格化係数 P_x = exp(-(x - mu)^2 / (2 * sigma^2)) / C_N, # 確率密度 #P_x = dnorm(x = x, mean = mu, sd = sigma) # 確率密度 ) # ガウス分布をプロット ggplot(gaussian_distribution_df, aes(x = x, y = P_x)) + geom_line() + labs(title = "Gaussian Distribution", subtitle = paste0("mu=", mu, ", sigma=", sigma), y = "density", x = "x")

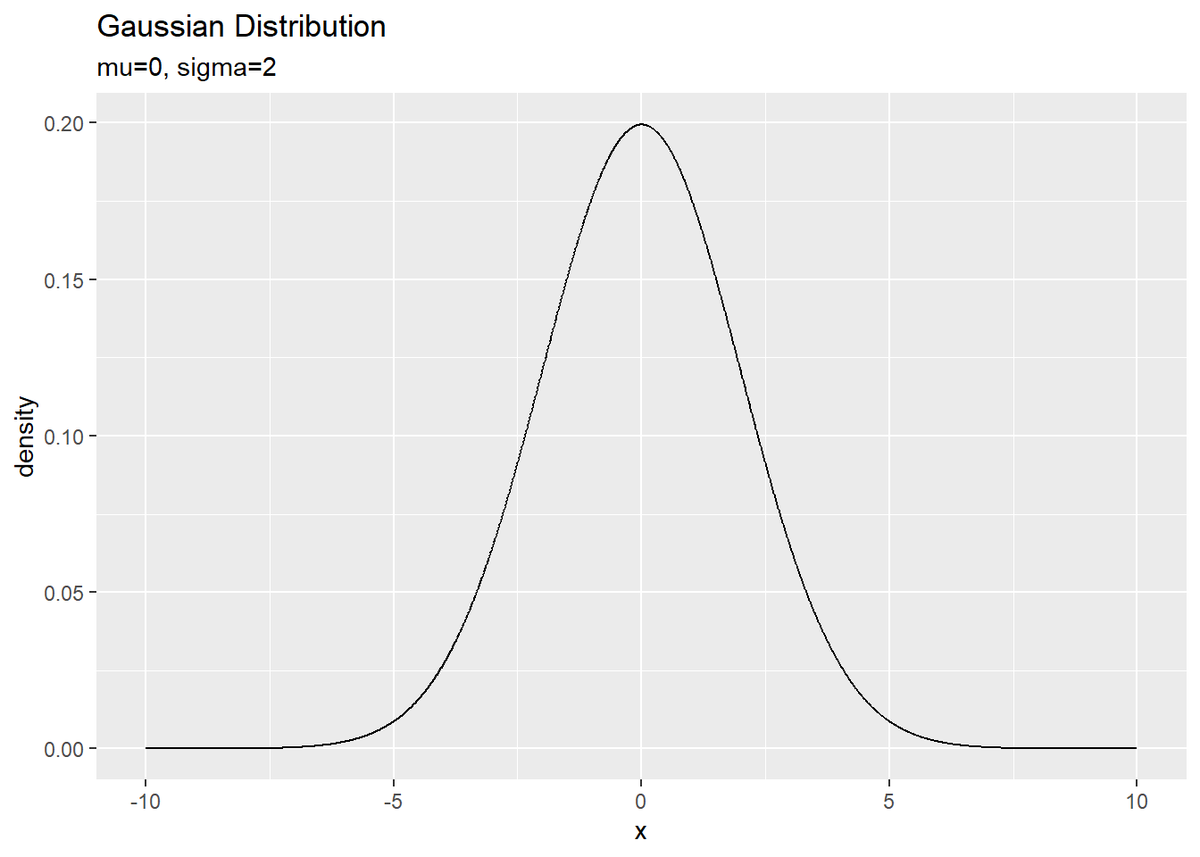
ちなみにガウス分布の確率密度は、dnorm()で計算できます。パラメータ(平均・標準偏差)を変更して分布の変化を確認しましょう。
ガウス分布自体の確認ができたので、次は一様乱数とガウス分布の関係について確認します。
$K$個の一様乱数を生成して、その和を計算します。これを1つのデータに加わる誤差とします。誤差を100万個作成してヒストグラムを見ます。
# 一様分布の範囲を指定 a <- -0.5 b <- 0.5 # 誤差の種類数を指定 K <- 100 # 誤差を生成 sum_error <- 0 # 変数を初期化 for(k in 1:K) { # 一様乱数生成 k_error <- runif(n = 1000000, min = a, max = b) # 誤差を加算 sum_error <- sum_error + k_error } # 作図用のデータフレームを作成 error_df = tibble( error = sum_error ) # 確認 head(error_df)
## # A tibble: 6 x 1 ## error ## <dbl> ## 1 -1.79 ## 2 -2.92 ## 3 -5.86 ## 4 1.01 ## 5 0.786 ## 6 1.64
$K$回のループ処理は、次のように1000000 * K個の乱数を生成することで一度の処理で行えます。
# for()無しver error_df <- runif(n = 1000000 * K, min = a, max = b) %>% matrix(ncol = K) %>% rowSums() %>% tibble(error = .) # 確認 head(error_df)
## # A tibble: 6 x 1 ## error ## <dbl> ## 1 -3.83 ## 2 -0.430 ## 3 3.23 ## 4 -2.15 ## 5 3.70 ## 6 9.67
乱数を生成(ランダムな処理を)するので、実行する度に結果が変わります。実行結果を再現したいときは、シードを設定します。
誤差のヒストグラムをプロットします。ただし一様分布の設定を変えても比較できるように、誤差を$\sqrt{K}$で割っておきます。
# ヒストグラムをプロット ggplot(error_df, aes(x = error / sqrt(K))) + geom_histogram(binwidth = 0.1) + labs(subtitle = (paste0("K=", K)), x = expression(x / K^0.5))
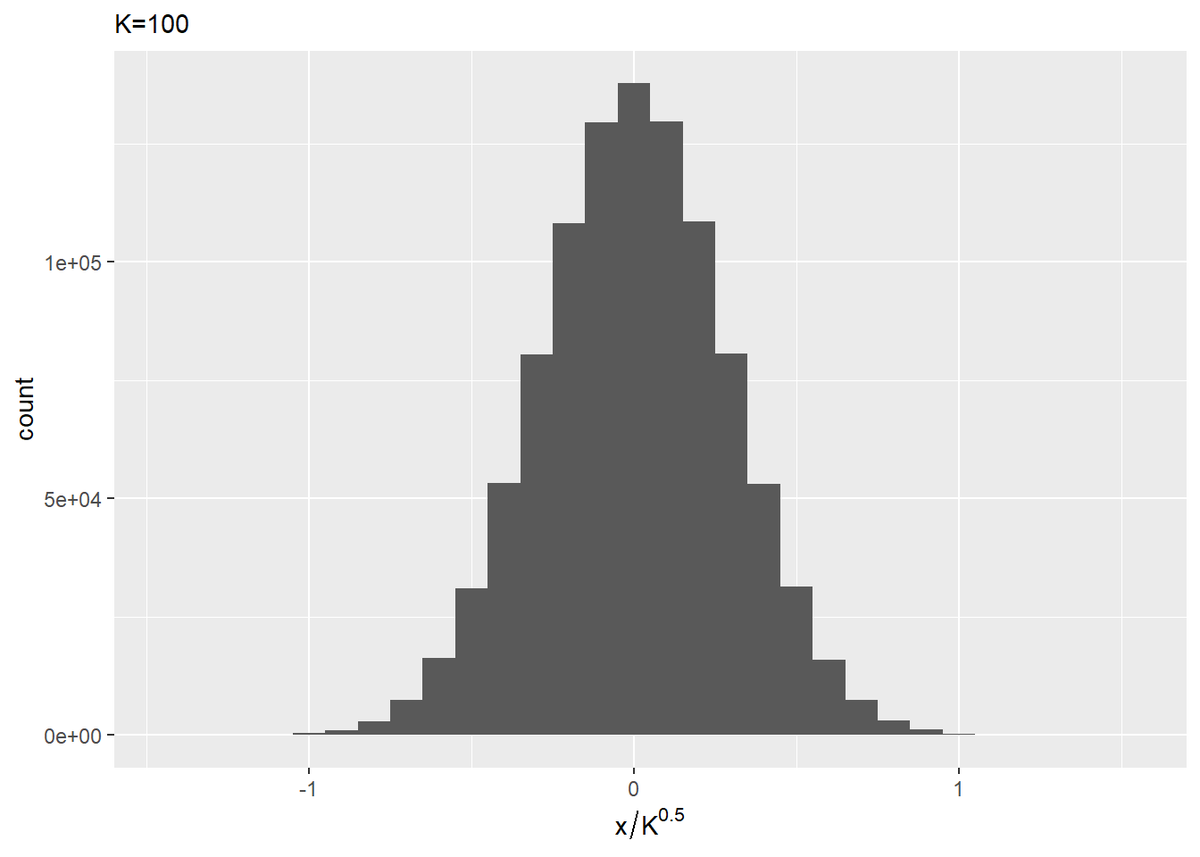
$K$が大きくなるほど、ガウス分布の形状に近づくのを確認できます。(ところで近似したガウス分布の平均・標準偏差はどうやって求めるの?)
$K$の変化と分布の変化をアニメーション(gif画像)で確認しましょう。
・コード(クリックで展開)
# 一様分布の範囲を指定 a <- -0.5 b <- 0.5 # 誤差の種類を指定 K <- 100 # 作図用のデータフレームを作成 error_animation_df <- tibble() # 変数を初期化 for(k in 1:K) { # k種類の誤差を加算 tmp_df <- (runif(n = 10000 * k, min = a, max = b) / sqrt(k)) %>% # (x / √K)としている matrix(ncol = k) %>% rowSums() %>% tibble( error = ., k = as.factor(k) ) # 計算結果を結合 error_animation_df <- rbind(error_animation_df, tmp_df) } # 作図 error_animation <- ggplot(error_animation_df, aes(x = error)) + geom_histogram(binwidth = 0.1) + gganimate::transition_manual(k) + # フレーム labs(subtitle = "K={current_frame}", x = expression(x / K^0.5)) # gif画像を作成 gganimate::animate(error_animation, nframes = K, fps = 5)
gif画像のフレームを指定するための列を用意する必要があります。この例では、誤差の数$k$ごとにグラフを変えるために、k列をgganimate::transition_manual()に指定します。処理が重い場合は、乱数の数や誤差の種類数を変更してください。
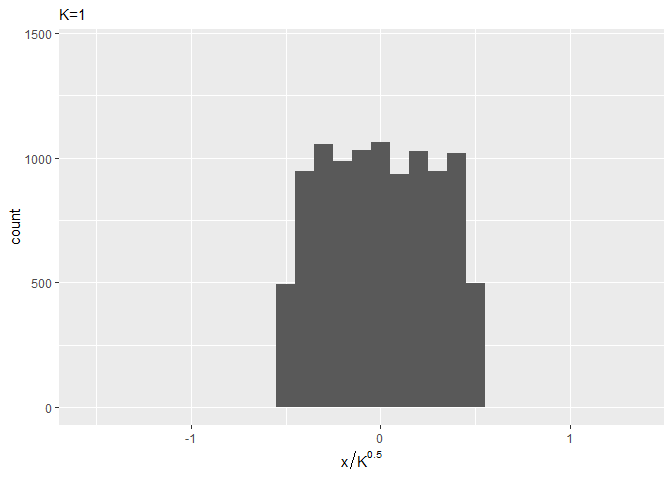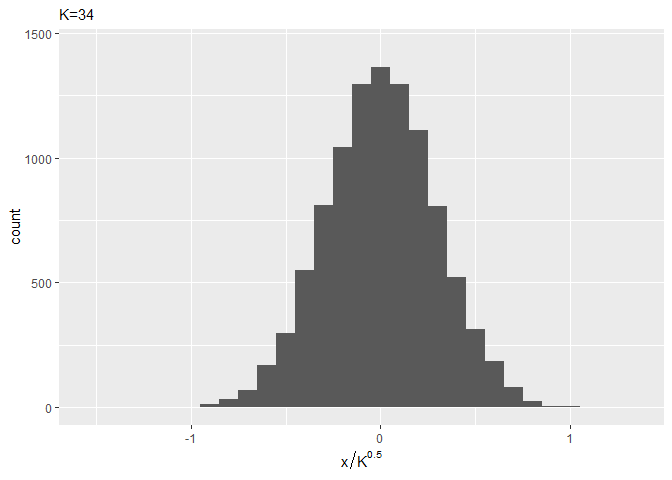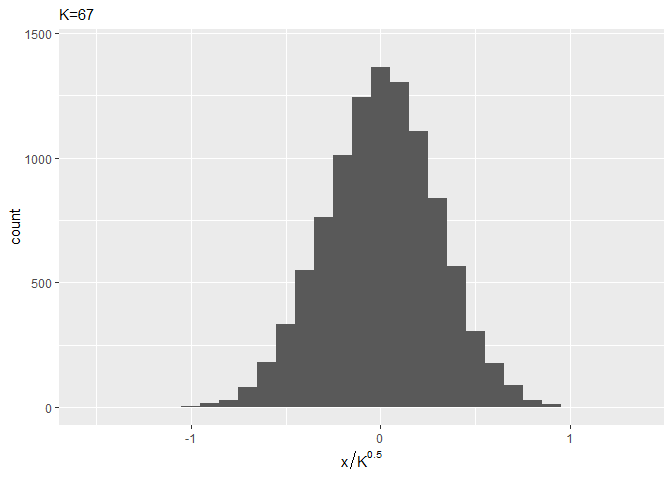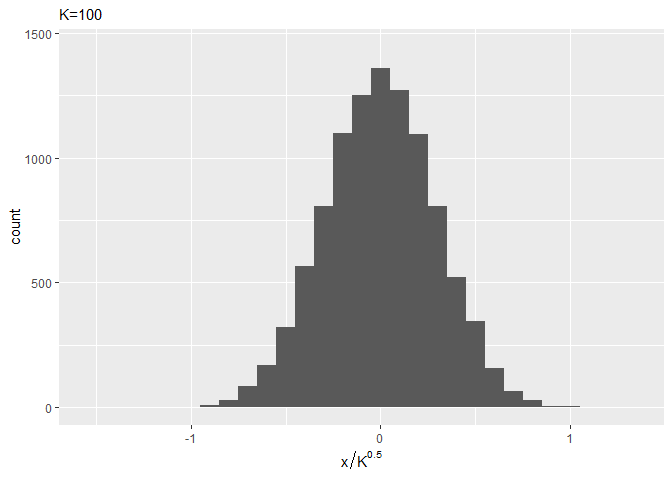
かなり早い段階でガウス分布のような形状になっていますね。binwidthの値を小さくするともう少し変化が分かると思います(この図は図2.3の間隔に合わせました)。
この節では、一様分布とガウス分布について確認しました。次節では、乱数を用いて積分の計算を近似する例を見ていきます。
2.2 一様乱数を用いた積分
2.2.1 一様乱数を用いた円周率の計算
原点(点$(0, 0)$)を中心とする半径1の円は、$x^2 + y^2 = 1$で表せます。この式を
と変形して、$0 \leq x \leq 1$、$0 \leq y \leq 1$の範囲をプロットしましょう。
# 扇形のラインのデータフレームを作成 circle_df <- tibble( x = seq(0, 1, 0.01), y = sqrt(1 - x^2) ) # 扇形のラインを作図 ggplot(circle_df, aes(x = x, y = y)) + geom_line() + coord_fixed() + # 縦横比を固定 labs(title = expression(x^2 + y^2 == 1))
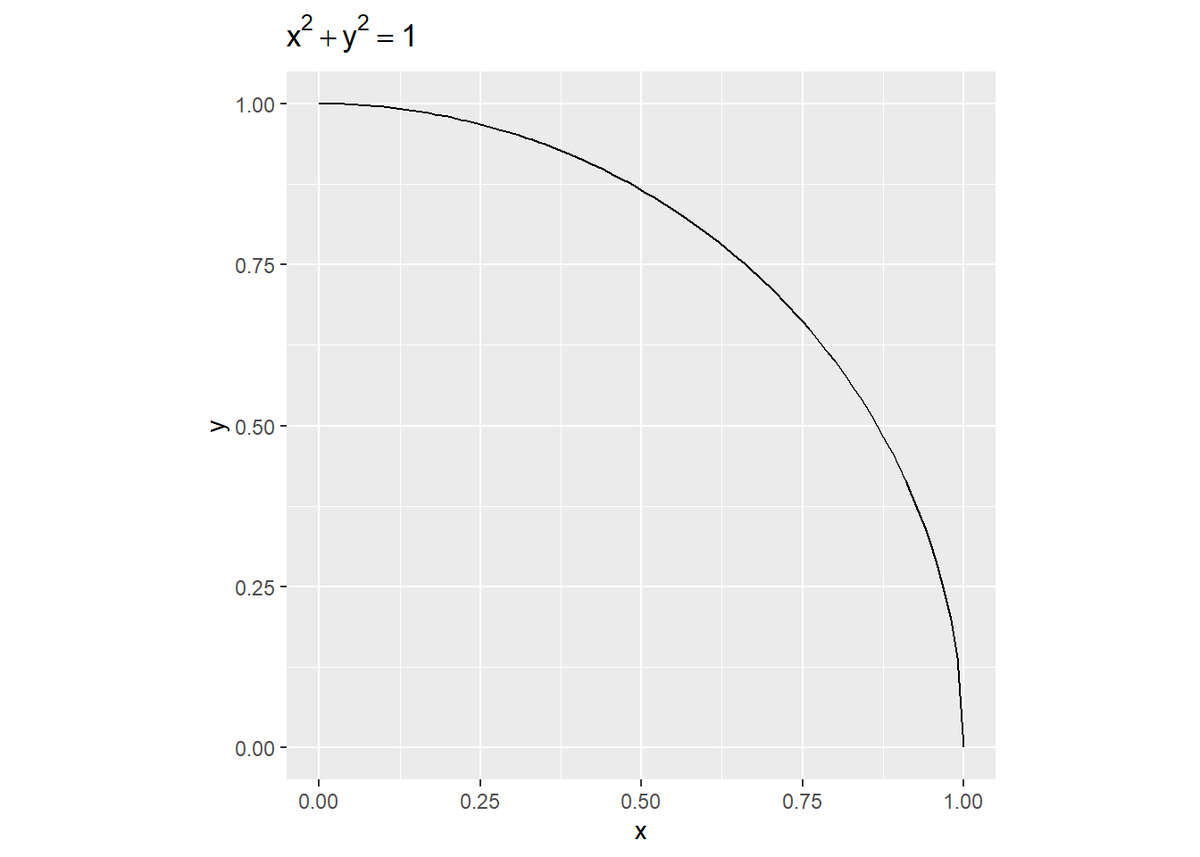
この4分の1の円(扇形)の面積について考えます。この扇形の面積は、積分計算により$\frac{\pi}{4} = 0.7853982$と求められます。ではこれを乱数を用いて求めましょう。
次のように考えます。$0 \leq x \leq 1$、$0 \leq y \leq 1$の範囲の面積は1ですね。この正方形の内に占める扇形の割合も$\frac{\pi}{4}$です。この$1 \times 1$の範囲に$K$個の点を等確率で生成してみます。すると$K$個の内、$\frac{\pi}{4}$割の数が扇形の中に入る($x^2 + y^2 < 1$になる)と考えられます。
では実際にやってみましょう。
# 繰り返し回数を指定 K <- 1000 # 変数を初期化 n_in <- 0 sample_x <- NULL sample_y <- NULL # Main loop for(k in 1:K) { # 乱数を生成 x <- runif(n = 1, min = 0, max = 1) y <- runif(n = 1, min = 0, max = 1) # サンプルを記録 sample_x <- c(sample_x, x) sample_y <- c(sample_y, y) # 扇形内のサンプルをカウント if(x^2 + y^2 < 1) { # 乱数が扇の中のとき n_in <- n_in + 1 } # 途中経過を表示 #print(paste0("iteration: ", k, ", rate: ", round(n_in / k, 3))) } # 乱数をデータフレームに格納 sample_df <- tibble( x = sample_x, y = sample_y, label = dplyr::if_else( x^2 + y^2 < 1, true = "in", false = "out" ) ) # 確認 head(sample_df)
## # A tibble: 6 x 3 ## x y label ## <dbl> <dbl> <chr> ## 1 0.265 0.0326 in ## 2 0.199 0.849 in ## 3 0.697 0.983 out ## 4 0.600 0.962 out ## 5 0.697 0.106 in ## 6 0.174 0.173 in
生成した乱数が扇形の中(in)か外(out)かをdplyr::if_else()を使って判定しています。
乱数を中(in)か外(out)かによって色分けしてプロットします。
# サンプルを確認 ggplot() + geom_line(data = circle_df, aes(x = x, y = y), size = 1) + # 扇形のライン geom_point(data = sample_df, aes(x = x, y = y, color = label)) + # 乱数の散布図 coord_fixed() + # 縦横比を固定 labs(title = expression(x^2 + y^2 < 1), subtitle = paste0("K=", K, ", N_in=", n_in))

中の数n_inを全体の数Kで割ると0.804となりました。
ただし、$K$の数が少ないとうまく近似できません。また、ランダムな処理を用いるため全く同じ結果にもなりません。そこで複数回実験を行い、点の数の増加による推定値の推移を確認しましょう。
# 繰り返し回数を指定 K <- 1000 # シミュレーション回数を指定 n_simu <- 100 # シミュレーション res_df <- tibble() # 変数を初期化 for(s in 1:n_simu) { # Main loopの処理 tmp_df <- tibble( x = runif(n = K, min = 0, max = 1), y = runif(n = K, min = 0, max = 1), label = dplyr::if_else( x^2 + y^2 < 1, true = TRUE, false = FALSE ), # 扇形の中か判定 k = 1:K, # 繰り返し回数 simulation = as.factor(s) # 何回目のシミュレーションか ) %>% dplyr::mutate(rate_in = cumsum(label) / k) # k回目におけるin率を計算 # 結果を結合 res_df <- rbind(res_df, tmp_df) # 途中経過を表示 #print(paste0( # "simulation: ", s, ", E: ", round(tmp_df[["rate_in"]][K], 3) #)) } # 確認 head(res_df)
## # A tibble: 6 x 6 ## x y label k simulation rate_in ## <dbl> <dbl> <lgl> <int> <fct> <dbl> ## 1 0.915 0.969 FALSE 1 1 0 ## 2 0.174 0.729 TRUE 2 1 0.5 ## 3 0.176 0.728 TRUE 3 1 0.667 ## 4 0.746 0.807 FALSE 4 1 0.5 ## 5 0.102 0.588 TRUE 5 1 0.6 ## 6 0.361 0.893 TRUE 6 1 0.667
先ほどは、Main loopの処理を定義通りループ処理で行いました。ここでは、データフレームの作成時に、$K$個の乱数を生成して一度の処理で行います。
また、"in"、"out"ではなくTRUE、FALSEを割り当てます。TRUEは1、FALSEは0として計算できるので、label列の和をとることで扇形内の点の数が得られます。cumsum()は、指定したデータフレームの列の1行目から各行までの総和を返します。つまりcumsum(label)とすることで、例えば6行目の要素は、1から6行目までのTRUEの数になります。これが、$x^{(1)}$から$x^{(6)}$の内扇形の中に入った点の数です。
では近似した面積の推移をグラフで確認します。
# 推移をプロット ggplot(res_df, aes(x = k, y = rate_in, color = simulation)) + geom_line(alpha = 0.5) + # 面積(in率)の推移 geom_hline(aes(yintercept = pi / 4), linetype = "dashed") + # 真の面積 theme(legend.position = "none") + # 凡例 labs(title = expression(N[("in")] / K), subtitle = paste0("simulation:", n_simu), y = "rate")

どのシミュレーションでも真の値に近づいていくのを確認できました。求めた値を4倍することで、円周率$\pi$の近似値が得られるとも言えます。
この項では、面積を求めるための積分計算を乱数と総和の計算で行えました。次項では、同じ例を使って定積分の計算を乱数を用いて近似します。
2.2.2 一様乱数を用いた定積分
先ほどの高さ$y$を求める式を
とおき、この関数を0から1まで積分します。
この計算は扇形の面積を求めていることになるので、$\frac{\pi}{4}$になります。この項では、この定積分の計算を一様乱数を用いて近似することを考えます。
前項と同様に、0から1の一様分布$P(x)$から生成した$K$個の乱数$x^{(1)}, \cdots, x^{(K)}$を用いて、$f(x^{(1)}), \cdots, f(x^{(K)})$を計算します。さらにその平均値$\mathbb{E}[f(x^{(k)})]$を求めます。
$K$が十分に大きいとき、定積分の計算(1)を平均値$\mathbb{E}[f(x^{(k)})]$で近似できます。
これは、0から1の範囲で等確率で$x$が出現するとしたことから、式(1)の関数$f(x)$の$[0, 1]$の一様分布$P(x)$による期待値
とも考えられます。$P(x) = 1$は確率ではなく確率密度です。つまり次節の内容のように、期待値$\mathbb{E}[f(x)]$を乱数による平均$\mathbb{E}[f(x^{(k)})]$で近似しています。
では実際に計算してみましょう。積分する範囲をa、bを0、1とします(でないと正しく推定できません)。
# 繰り返し回数を指定 K <- 1000 # 積分する範囲を指定 a <- 0 b <- 1 # シミュレーション回数を指定 n_simu <- 100 # シミュレーション res_df <- tibble() # 初期化 for(s in 1:n_simu) { # Main loopの処理 tmp_df <- tibble( x = runif(n = K, min = a, max = b), # 乱数を生成 f_x = sqrt(1 - x^2), k = 1:K, # 繰り返し回数 simulation = as.factor(s) # 何回目のシミュレーションか ) %>% dplyr::mutate(E_f_x = cumsum(f_x) / k) # 平均値を計算 # 結果を結合 res_df <- rbind(res_df, tmp_df) # 途中経過を表示 #print(paste0( # "simulation: ", s, ", E: ", round(tmp_df[["E_f_x"]][K], 3) #)) } # 確認 head(res_df)
## # A tibble: 6 x 5 ## x f_x k simulation E_f_x ## <dbl> <dbl> <int> <fct> <dbl> ## 1 0.830 0.557 1 1 0.557 ## 2 0.482 0.876 2 1 0.717 ## 3 0.238 0.971 3 1 0.802 ## 4 0.916 0.402 4 1 0.702 ## 5 0.394 0.919 5 1 0.745 ## 6 0.299 0.954 6 1 0.780
0から1の範囲の$x$を乱数として生成して、$y = f(x^{(k)})$を計算しています。なので、全て扇形のライン上の点です。つまり$f(x^{(k)})$の平均は、x軸を底辺としたときの高さの平均と言えます。よって底辺1と高さ$\mathbb{E}[f(x^{(k)})]$の積で、扇形の面積を近似できます。
面積の近似の推移を描画します。
# 推移をプロット ggplot(res_df, aes(x = k, y = E_f_x, color = simulation)) + geom_line(alpha = 0.5) + # 面積の推移 geom_hline(aes(yintercept = pi / 4), linetype = "dashed") + # 真の値 theme(legend.position = "none") + # 凡例 labs(title = expression(f(x) == sqrt(1 - x^2)), subtitle = paste0("a=", a, ", b=", b, ", simulation:", n_simu), y = "E[f(x)]")
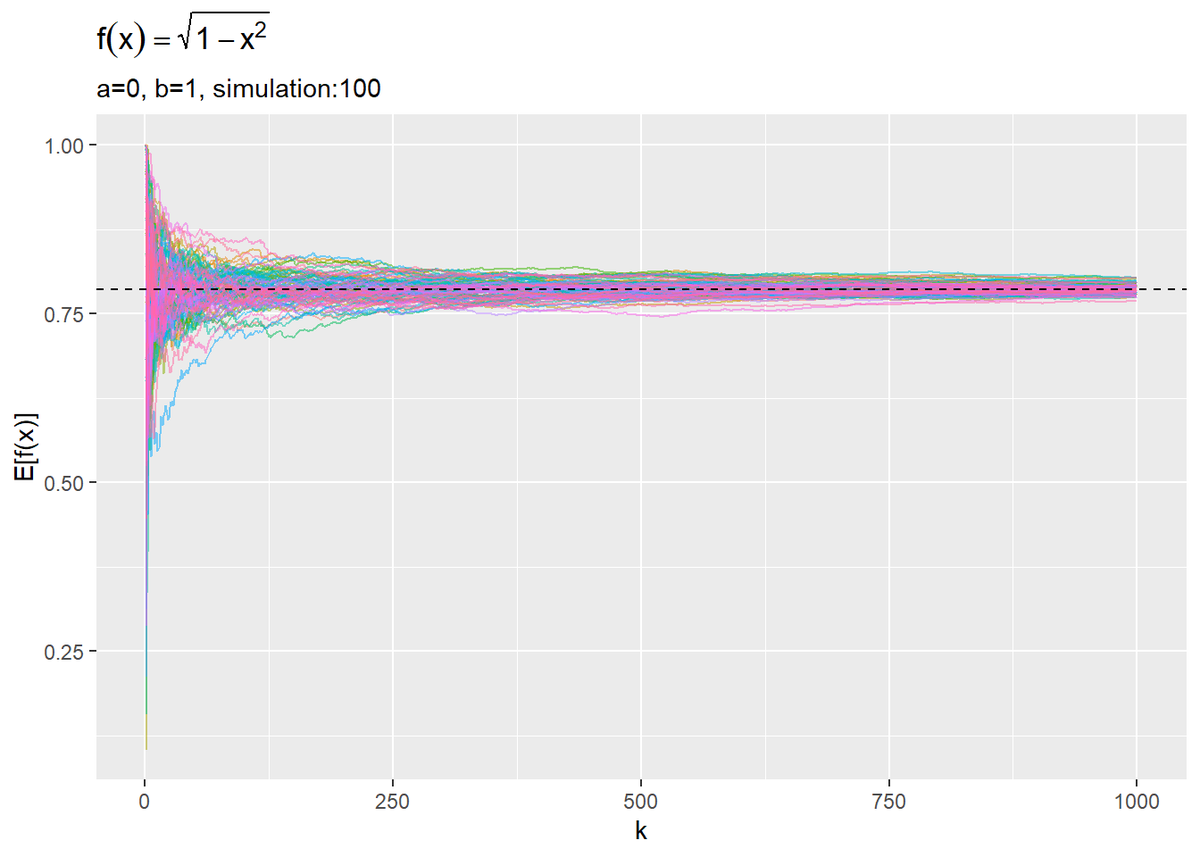
先ほどと同じく$\frac{\pi}{4}$に近づいています。
ここまでは、素朴なモンテカルロ法で積分を近似できる例を見てきました。次項では上手くいかない例として、ガウス分布に対する積分の近似を考えます。
2.2.3 ガウス積分
この項では、平均$\mu = 0$、標準偏差$\sigma = 1$のガウス分布(標準正規分布)
の$-a$から$a$の積分を考えます。
確率分布なので$a \rightarrow \infty$で1になります。
この分布をグラフで確認しておきましょう。
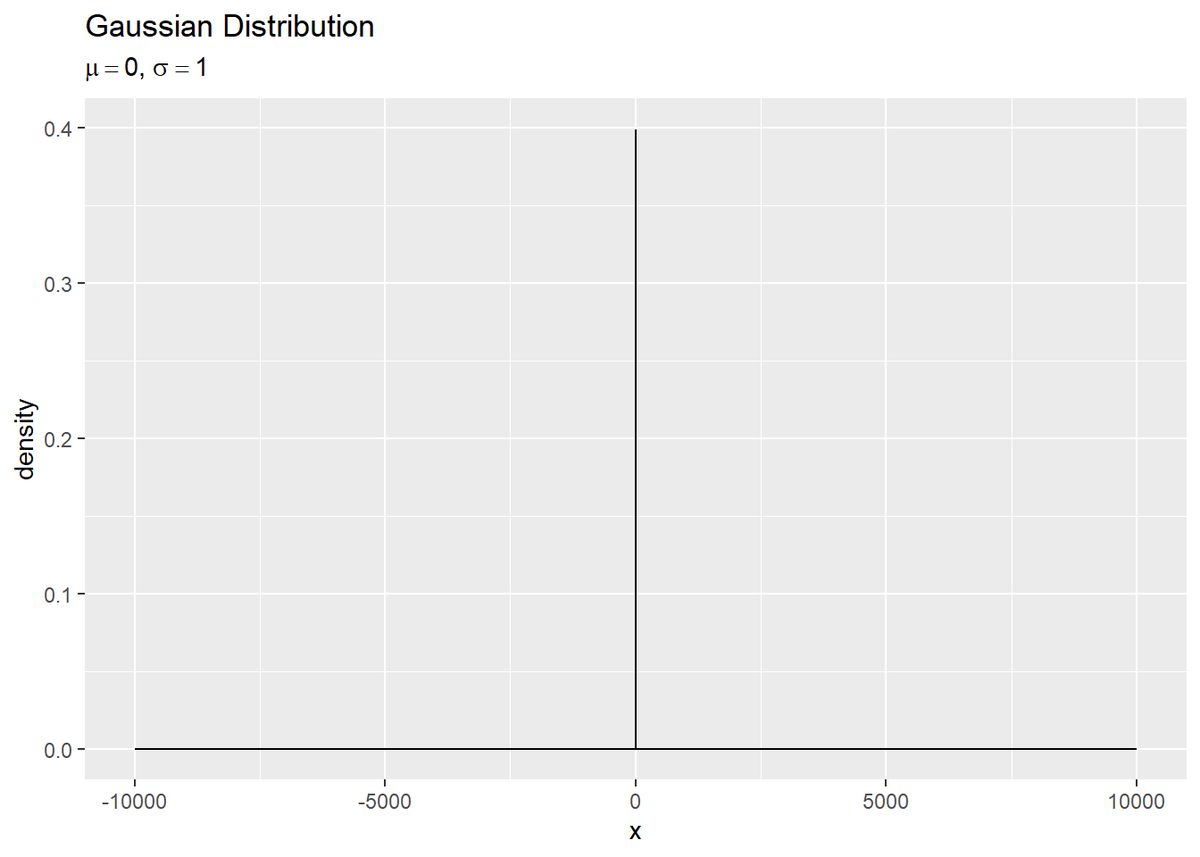
# 積分範囲を指定 a = 2 # ガウス分布のデータフレームを作成 gaussian_distribution_df <- tibble( x = seq(-a, a, 0.01), # x軸の描画範囲 P_x = exp(-x^2 / 2) / sqrt(2 * pi) # 確率密度 #P_x = dnorm(x = x, mean = 0, sd = 1) # 確率密度 ) # ガウス分布をプロット ggplot(gaussian_distribution_df, aes(x = x, y = P_x)) + geom_line() + labs(title = "Gaussian Distribution", subtitle = expression(paste(mu == 0, ", ", sigma == 1)), y = "density")

先ほどの扇形の高さを求める関数$f(x)$のときと同様に、生成した一様乱数$x^{(k)}$を用いて確率密度$P(x^{(k)})$を$K$回計算し、$P(x^{(k)})$の平均値$\mathbb{E}[P(x^{(k)})] = \frac{1}{K} \sum_{k=1}^K P(x^{(k)})$を計算します。
# 繰り返し回数を指定 K <- 1000 # シミュレーション回数を指定 n_simu <- 100 # シミュレーション res_df <- tibble() # 初期化 for(s in 1:n_simu) { # Main loopの処理 tmp_df <- tibble( x = runif(n = K, min = -a, max = a), # 乱数を生成 #P_x = exp(-x^2 / 2) / sqrt(2 * pi), # 確率密度 P_x = dnorm(x = x, mean = 0, sd = 1), # 確率密度 k = 1:K, # 繰り返し番号 simulation = as.factor(s) # シミュレーション番号 ) %>% dplyr::mutate(E_P_x = cumsum(P_x) / k) # 平均値を計算 # 結果を結合 res_df <- rbind(res_df, tmp_df) # 途中経過を表示 #print(paste0( # "simulation: ", s, ", E: ", round(tmp_df[["E_P_x"]][K], 3) #)) } # 確認 head(res_df)
## # A tibble: 6 x 5 ## x P_x k simulation E_P_x ## <dbl> <dbl> <int> <fct> <dbl> ## 1 -1.02 0.238 1 1 0.238 ## 2 -1.75 0.0858 2 1 0.162 ## 3 -1.41 0.148 3 1 0.157 ## 4 0.0611 0.398 4 1 0.218 ## 5 -1.72 0.0909 5 1 0.192 ## 6 0.258 0.386 6 1 0.225
扇形の例ではグラフで見たときの底辺が1だったので、高さの平均$\mathbb{E}[f(x^{(k)})]$と面積が一致しました。この例では、x軸の範囲(底辺)$2 a = a - (-a)$を掛けた値が面積になります。この面積$2 a \mathbb{E}[P(x^{(k)})]$が、$P(x)$の積分値$\int_{-a}^a P(x) dx$の近似値になります。
積分値の近似の推移を確認します。
# 推移をプロット ggplot(res_df, aes(x = k, y = E_P_x * 2 * a, color = simulation)) + geom_line(alpha = 0.5) + # 積分値の推移 geom_hline(aes(yintercept = 1), linetype = "dashed") + # 真の値 #ylim(c(0, 4)) + # y軸の表示範囲 theme(legend.position = "none") + # 凡例 labs(title = expression(f(x) == N(x, mu == 0, sigma == 1)), subtitle = paste0("a=", a), y = "E[f(x)]")
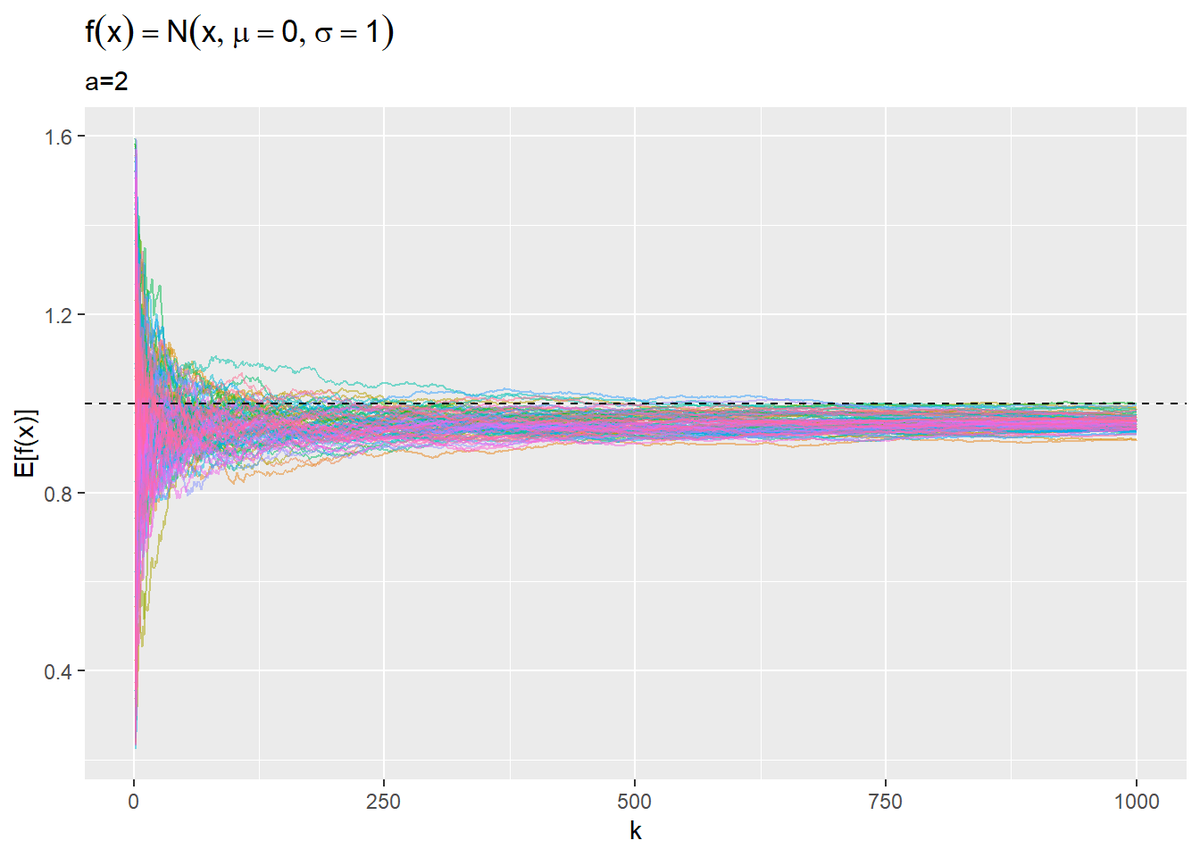
$a = 2$のとき積分値は0.95なので、近似できています。では$a$の値を大きくした場合はどうなるでしょうか。(ところでなんで図2.7は2付近に収束してるんだ??)
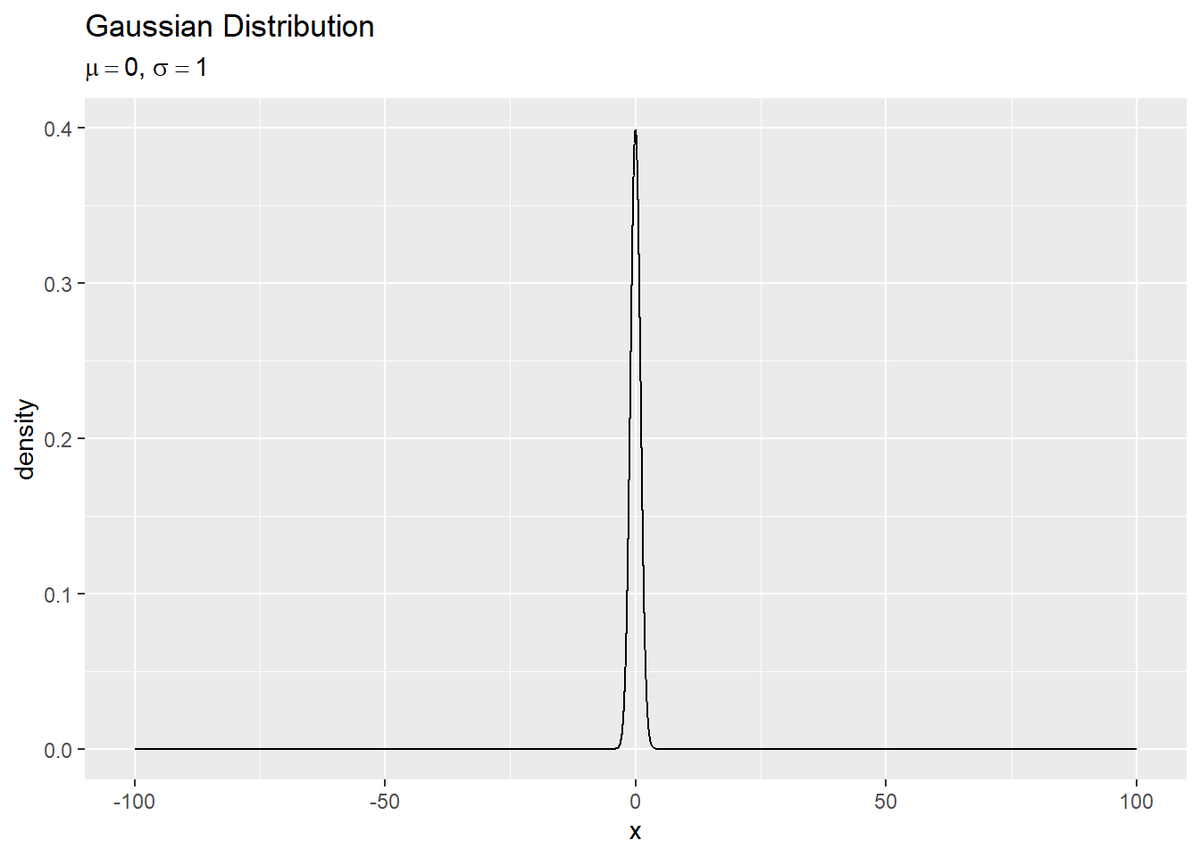
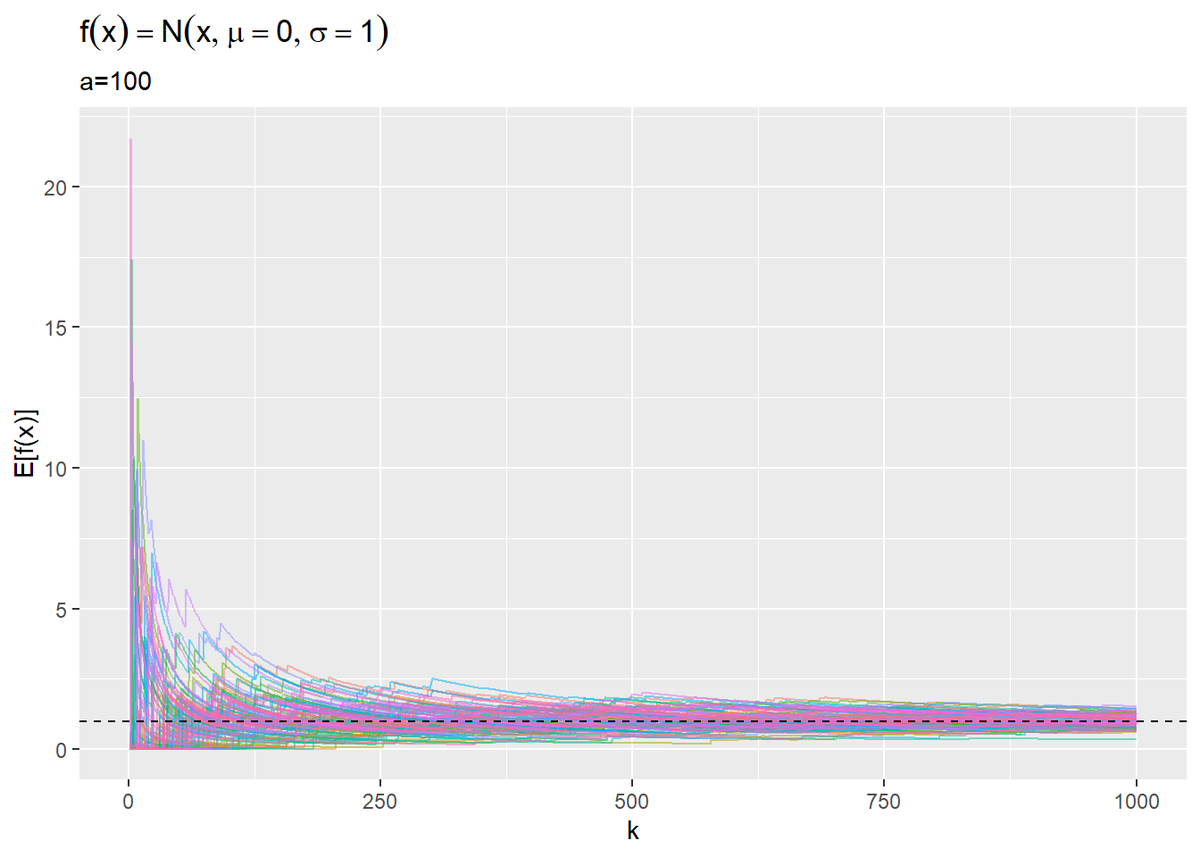
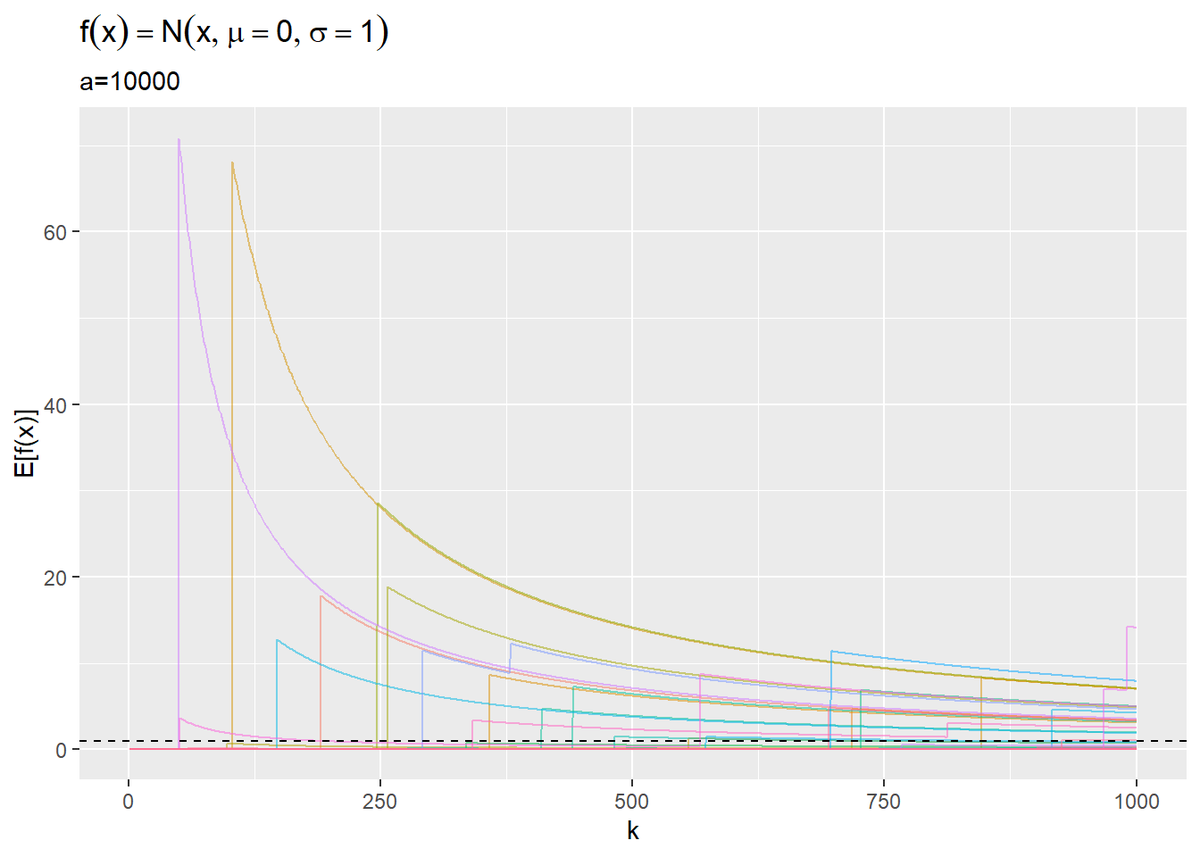
ガウス分布を見るとほとんどの範囲で確率密度がほぼ0です。ここからサンプルするのは非効率です。ではどうすれば効率よくできるのか?がこの本のテーマです。具体的な方法は追々やっていくとして、この章ではそのために必要な「積分を乱数を用いることで計算(近似)できる」ということに焦点を当てています。
この節では、関数や確率分布に対する積分を考えました。次節では、期待値の計算(関数と確率分布の積に対する積分)を考えます。
2.3 期待値と積分
原点(点$(0, 0, 0)$)を中心とする半径1の球は、$x^2 + y^2 + z^2 = 1$で表せます。この式を
と変形して、$0 \leq x \leq 1$、$0 \leq y \leq 1$の範囲における関数$f(x, y) = \sqrt{1 - x^2 - y^2}$を考えます。
期待値の計算を行うために、この関数$f(x, y)$に対応する確率分布$P(x, y)$を考えます。
z軸を高さとして、x軸とy軸を真上から見ると2.2.1項の扇形の形状をしています。この扇形上にのみ$x,\ y$が等確率で出現するような確率分布である必要があります。つまり、$0 \leq x \leq 1$、$0 \leq y \leq 1$かつ$x^2 + y^2 < 1$のとき確率密度が$\frac{4}{\pi}$であり、それ以外のとき0である確率分布を$P(x, y)$とします。$P(x, y) = \frac{4}{\pi}$は、$P(x, y)$を積分したとき$\int \int P(x, y) dx dy = 1$となるように決まります。別の表現をすると、扇形を底面としたとき体積が1となるような高さ$P(x, y)$として、扇形の面積$\frac{\pi}{4}$の逆数になります。
この項では、この関数と確率分布による期待値
を乱数を用いて近似します。
2.2.2項の扇形の面積のときと同様にして、$K$個の一様乱数から条件に合うもので求めた$f(x, y)$の平均値
により式(2.7)の期待値を近似します。
また高さの平均に対応する$\mathbb{E}[f(x^{(k)}, y^{(k)})]$と底面となる扇形の面積$\frac{\pi}{4}$から、球の体積$V$を求めます。今は球を$0 \leq x \leq 1$、$0 \leq y \leq 1$の範囲で切り分け考えているので、扇形の面積と高さの平均値の積は球の体積全体の8分の1になります。
両辺に8を掛けると
球の体積$V = \frac{4 \pi}{3}$の近似値が得られます。
2.2.1項のときと同様にして、実際に計算します。
# 繰り返し回数を指定 K <- 1000 # シミュレーション回数を指定 n_simu <- 100 # シミュレーション res_df <- tibble() # 初期化 for(s in 1:n_simu) { # Main loopの処理 tmp_df <- tibble( x = runif(n = K, min = 0, max = 1), # 乱数を生成 y = runif(n = K, min = 0, max = 1), # 乱数を生成 label = dplyr::if_else( x^2 + y^2 < 1, true = TRUE, false = FALSE ), # 扇形の中か判定 f_xy = dplyr::if_else( label == TRUE, true = sqrt(1 - x^2 - y^2), false = 0 ), # 扇形の中のとき面積を計算:式(2.9) k = 1:K, # 繰り返し番号 simulation = as.factor(s) # シミュレーション番号 ) %>% dplyr::mutate(n_in = cumsum(label)) %>% # 扇形の中の数 dplyr::mutate(E_f_xy = cumsum(f_xy) / n_in) # zの平均値を計算 # 結果を結合 res_df <- rbind(res_df, tmp_df) # 途中経過を表示 #print(paste0( # "simulation: ", s, ", E: ", round(tmp_df[["E_f_xy"]][K], 3) #)) } # 確認 head(res_df)
## # A tibble: 6 x 8 ## x y label f_xy k simulation n_in E_f_xy ## <dbl> <dbl> <lgl> <dbl> <int> <fct> <int> <dbl> ## 1 0.649 0.631 TRUE 0.424 1 1 1 0.424 ## 2 0.163 0.444 TRUE 0.881 2 1 2 0.653 ## 3 0.335 0.710 TRUE 0.619 3 1 3 0.642 ## 4 0.0961 0.424 TRUE 0.901 4 1 4 0.706 ## 5 0.335 0.452 TRUE 0.827 5 1 5 0.730 ## 6 0.921 0.756 FALSE 0 6 1 5 0.730
$\mathbb{E}[f(x, y)]$が得られました。$P(x, y)$の計算は、扇形の中に入るかどうかが対応しています。(計算結果がNaNになったっていうwarningメッセージが出るけど、0で上書きされるはずだしたぶん大丈夫。)
最後に式(2.9)の計算を行い、体積の近似の推移を確認します。
# 推移をプロット ggplot(res_df, aes(x = k, y = E_f_xy * 2 * pi, color = simulation)) + geom_line(alpha = 0.5) + # 体積の推移 geom_hline(aes(yintercept = 4 * pi / 3), linetype = "dashed") + # 真の体積 theme(legend.position = "none") + # 凡例 labs(title = expression(f(x, y) == 2 * pi * sqrt(1 - x^2 - y^2)), subtitle = paste0("simulation: ", n_simu), y = "E[f(x, y)]")
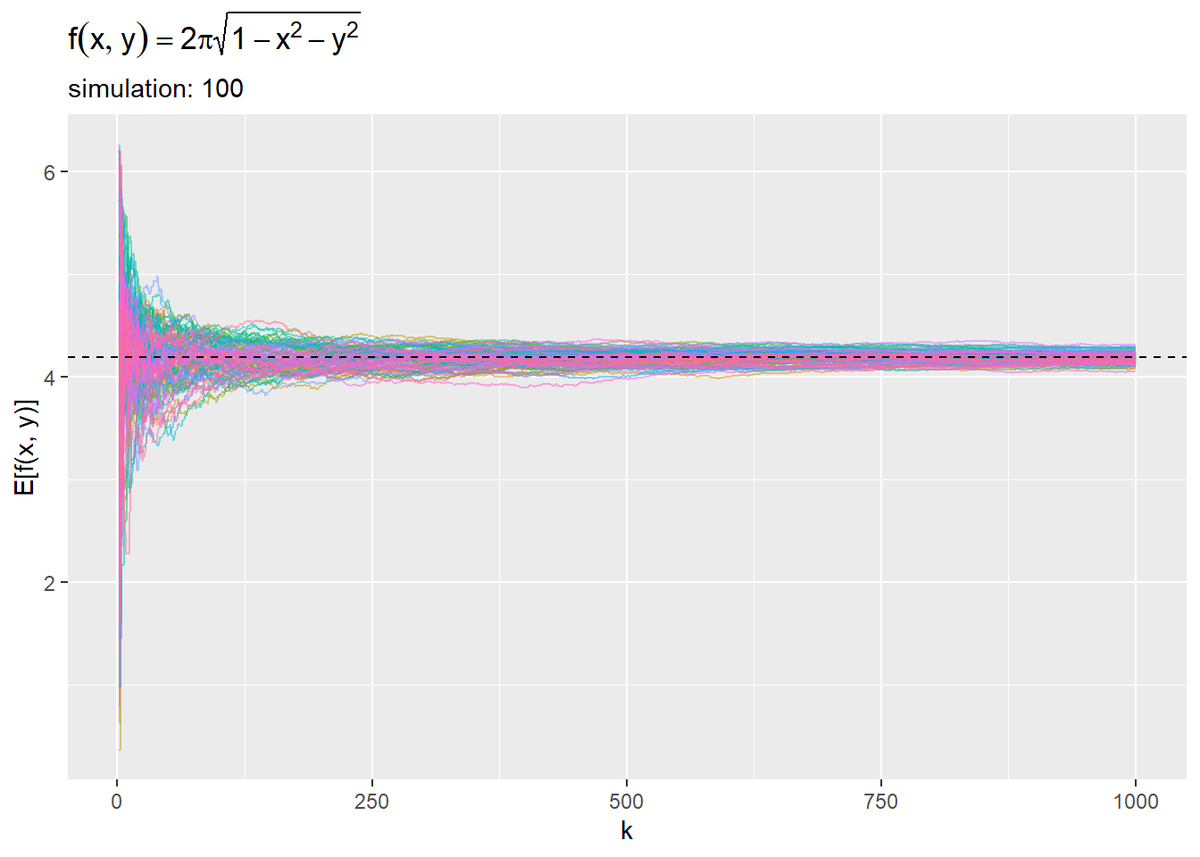
うまく近似できているのを確認できます。
これまでは、一様分布を用いて乱数を生成しました。次節では、ガウス分布に従う乱数を用います。
2.4 ガウス乱数を用いた期待値の計算
2.4.2 ガウス分布から得られる期待値
関数$f(x)$と確率分布$P(x)$の積を積分することで、関数$f(x)$の期待値$\mathbb{E}[f(x)]$を計算できます。
この例では、平均$\mu = 0$、標準正規$\sigma = 1$のガウス分布$\mathcal{N}(x | \mu = 0, \sigma = 1)$とします。この期待値計算をガウス分布に従う乱数(ガウス乱数)を用いて近似します。
ガウス乱数を生成することを次のように書きます。
$K$個のガウス乱数$x^{(1)}, \cdots, x^{(K)}$を用いて、$f(x) = x$とした場合の期待値$\mathbb{E}[x]$
と、$f(x) = x^2$とした場合の期待値$\mathbb{E}[x^2]$
を求めます。$x$の期待値$\mathbb{E}[x]$は$\mu$(この例だと0)、$x$の2乗の期待値$\mathbb{E}[x^2]$は$\mu^2 + \sigma^2$(つまり1)になります。
これまでと同様に計算できます。ただし、ガウス乱数の生成には組み込み関数rnorm()を使います。
# 繰り返し回数を指定 K <- 1000 # パラメータを指定 mu <- 0 sigma <- 1 # シミュレーション回数を指定 n_simu <- 100 # シミュレーション res_df <- tibble() # 初期化 for(s in 1:n_simu) { # Main loopの処理 tmp_df <- tibble( x = rnorm(n = K, mean = mu, sd = sigma), # 乱数を生成 f_x = x, f_x2 = x^2, k = 1:K, # 繰り返し番号 simulation = as.factor(s) # シミュレーション番号 ) %>% dplyr::mutate(E_f_x = cumsum(f_x) / k)%>% # 平均値を計算 dplyr::mutate(E_f_x2 = cumsum(f_x2) / k) # 平均値を計算 # 結果を結合 res_df <- rbind(res_df, tmp_df) # 途中経過を表示 #print(paste0( # "simulation: ", s, # ", E[x]: ", round(tmp_df[["E_f_x"]][K], 3), # ", E[x^2]: ", round(tmp_df[["E_f_x2"]][K], 3) #)) } # 確認 head(res_df)
## # A tibble: 6 x 7 ## x f_x f_x2 k simulation E_f_x E_f_x2 ## <dbl> <dbl> <dbl> <int> <fct> <dbl> <dbl> ## 1 0.0698 0.0698 0.00487 1 1 0.0698 0.00487 ## 2 0.590 0.590 0.348 2 1 0.330 0.177 ## 3 0.777 0.777 0.603 3 1 0.479 0.319 ## 4 -0.254 -0.254 0.0645 4 1 0.296 0.255 ## 5 0.351 0.351 0.123 5 1 0.307 0.229 ## 6 -0.266 -0.266 0.0709 6 1 0.211 0.203
推定した$x$の期待値と$x$の2乗の期待値の推移をプロットします。
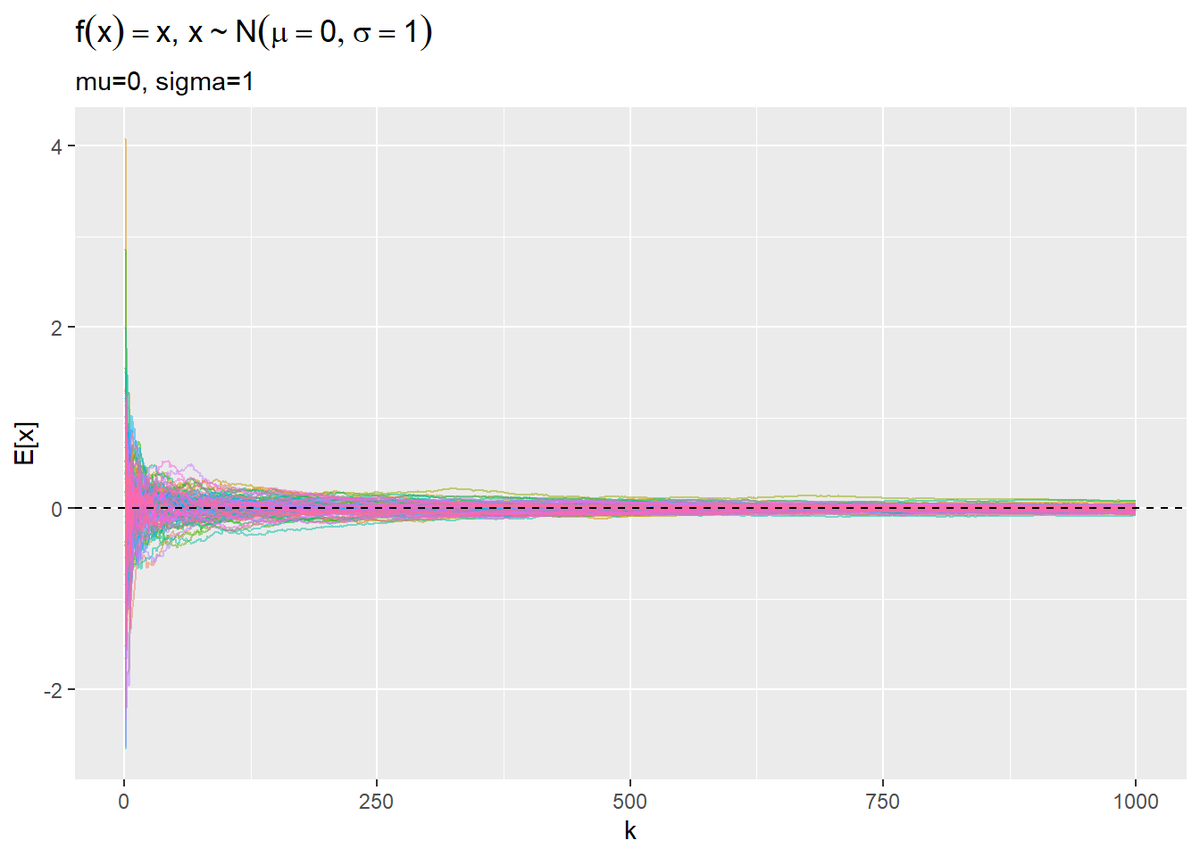
# xの期待値の推移をプロット ggplot(res_df, aes(x = k, y = E_f_x, color = simulation)) + geom_line(alpha = 0.5) + # 期待値の推移 geom_hline(aes(yintercept = mu), linetype = "dashed") + # 真の値 theme(legend.position = "none") + # 凡例 labs(title = expression(paste(f(x) == x, ", ", x %~% N(mu == 0, sigma == 1))), subtitle = paste0("mu=", 0, ", sigma=", 1), y = "E[x]")
# xの2乗の期待値の推移をプロット ggplot(res_df, aes(x = k, y = E_f_x2, color = simulation)) + geom_line(alpha = 0.5) + # 期待値の推移 geom_hline(aes(yintercept = mu^2 + sigma^2), linetype = "dashed") + # 真の値 theme(legend.position = "none") + # 凡例 labs(title = expression(paste(f(x) == x^2, ", ", x %~% N(mu == 0, sigma == 1))), subtitle = paste0("mu=", 0, ", sigma=", 1), y = "E[x^2]")
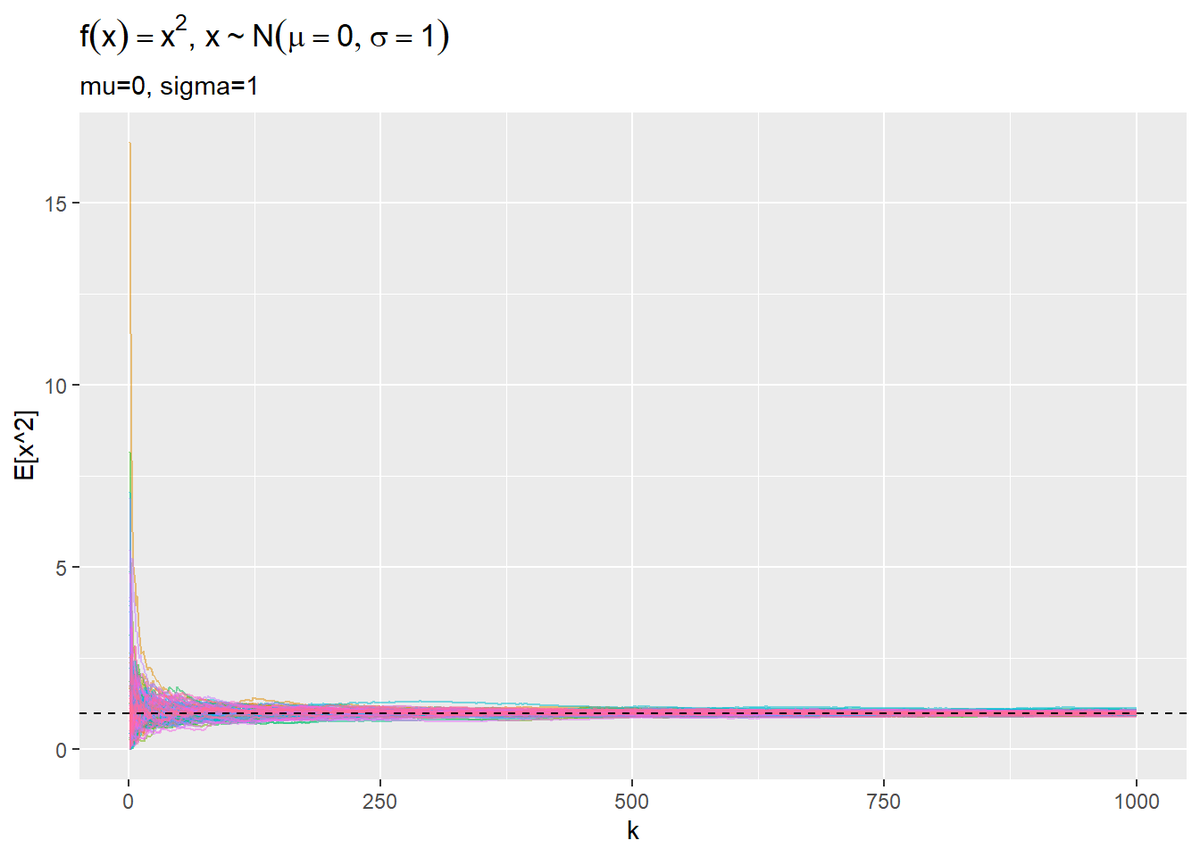
どちらも$K$が増えることで真の値に近づいていくを確認できます。(既にパラメータの分かっている分布から乱数を生成して、同じ分布の統計量を推定してるのだからまぁそうよね。)
以上で2章の内容は完了です。この章では、マルコフ連鎖モンテカルロ法(MCMC)のモンテカルロ法について説明しました。次章では、マルコフ連鎖について説明します。
参考文献
- 花田政範・松浦壮『ゼロからできるMCMC』講談社,2020年.
おわりに
色々な本をやり切らないまま新しい本をやり始めました!いやぁでもMCMCにはずっと入門したかったので。
2章で扱う例の数からいっても、この本は細かく丁寧にアルゴリズム解説している良い本の感触は十分なんですが、なんとなく解説文のレベルで自分とフィットしていないようで文の意図を汲み取るのが微妙に難しい。物理寄りの界隈では一般的な雰囲気だったりするのかなぁ、しかし積分の表記がちょっと、、、何にしても内容が難しくなる前に早く慣れたいものです。
などと思いつつ、記事では自分がしっくりくる流れに再構成してまとめていきます。数式の表現もかなり変えています。自分のレベルに落とし込むことで理解を深めようと思います。
一連の記事が自分と同じレベル感の人のお役に立てれば幸いです。
ところで、確率分布の期待値だっけ?平均値だっけ?分かんなくなってきた。
2021年2月2日は、モーニング娘。'21の牧野真莉愛さん二十歳の誕生日です。おめでとうございます!!
近頃の美少女と美人さんを行き来する感じが強すぎる。
今年も順調にハロプロ記念日駆動執筆でやっていきます。
【次の章の内容】